PythonдёӯitertoolsжЁЎеқ—еҰӮдҪ•дҪҝз”Ё
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңPythonдёӯitertoolsжЁЎеқ—еҰӮдҪ•дҪҝз”ЁвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁPythonдёӯitertoolsжЁЎеқ—еҰӮдҪ•дҪҝз”Ёй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқPythonдёӯitertoolsжЁЎеқ—еҰӮдҪ•дҪҝз”ЁвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
itertools — дёәй«ҳж•ҲеҫӘзҺҜиҖҢеҲӣе»әиҝӯд»ЈеҷЁзҡ„еҮҪж•°
accumulate(iterable: Iterable, func: None, initial:None)
iterableпјҡйңҖиҰҒж“ҚдҪңзҡ„еҸҜиҝӯд»ЈеҜ№иұЎ
funcпјҡеҜ№еҸҜиҝӯд»ЈеҜ№иұЎйңҖиҰҒж“ҚдҪңзҡ„еҮҪж•°пјҢеҝ…йЎ»еҢ…еҗ«дёӨдёӘеҸӮж•°
initial: зҙҜеҠ зҡ„ејҖе§ӢеҖј
еҜ№еҸҜиҝӯд»ЈеҜ№иұЎиҝӣиЎҢзҙҜи®ЎжҲ–иҖ…йҖҡиҝҮfuncе®һзҺ°еҸҢзӣ®иҝҗз®—пјҢеҪ“жҢҮе®ҡfuncзҡ„ж—¶еҖҷйңҖиҰҒдёӨдёӘеҸӮж•°гҖӮиҝ”еӣһзҡ„жҳҜиҝӯд»ЈеҷЁпјҢдёҺиҝҷдёӘж–№жі•зұ»дјјзҡ„е°ұжҳҜfunctoolsдёӢзҡ„reduceпјҢreduceе’ҢaccumulateйғҪжҳҜзҙҜи®ЎиҝӣиЎҢж“ҚдҪңпјҢдёҚеҗҢзҡ„жҳҜreduceеҸӘдјҡиҝ”еӣһжңҖеҗҺзҡ„е…ғзҙ пјҢиҖҢaccumulateдјҡжҳҫзӨәжүҖжңүзҡ„е…ғзҙ пјҢеҢ…еҗ«дёӯй—ҙзҡ„е…ғзҙ пјҢеҜ№жҜ”еҰӮдёӢпјҡ
| еҢәеҲ« | reduce | accumulate |
|---|
| иҝ”еӣһеҖј | иҝ”еӣһзҡ„жҳҜдёҖдёӘе…ғзҙ | иҝ”еӣһзҡ„жҳҜдёҖдёӘиҝӯд»ЈеҷЁпјҲеҢ…еҗ«дёӯй—ҙеӨ„зҗҶзҡ„е…ғзҙ пјү |
| жүҖеұһжЁЎеқ— | functools | itertools |
| жҖ§иғҪ | з•Ҙе·® | жҜ”reduceеҘҪдёҖдәӣ |
| еҲқе§ӢеҖј | еҸҜд»Ҙи®ҫзҪ®еҲқе§ӢеҖј | еҸҜд»Ҙи®ҫзҪ®еҲқе§ӢеҖј |
import time
from itertools import accumulate
from functools import reduce
l_data = [1, 2, 3, 4]
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(list(data))
start = time.time()
for i in range(100000):
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(time.time() - start)
start = time.time()
for i in range(100000):
data = reduce(lambda x, y: x + y, l_data)
print(time.time() - start)
#иҫ“еҮә
[2, 3, 5, 8, 12]
0.027924537658691406
0.03989362716674805
з”ұдёҠиҝ°з»“жһңеҸҜзҹҘпјҢaccumulateжҜ”reduceжҖ§иғҪзЁҚеҘҪдёҖдәӣпјҢиҖҢдё”иҝҳиғҪиҫ“еҮәдёӯй—ҙзҡ„еӨ„зҗҶиҝҮзЁӢгҖӮ
chain(*iterables)
iterables:жҺҘ收еӨҡдёӘеҸҜиҝӯд»ЈеҜ№иұЎ
дҫқж¬Ўиҝ”еӣһеӨҡдёӘиҝӯд»ЈеҜ№иұЎзҡ„е…ғзҙ пјҢиҝ”еӣһзҡ„жҳҜдёҖдёӘиҝӯд»ЈеҷЁ,еҜ№дәҺеӯ—е…ёиҫ“еҮәе…ғзҙ ж—¶пјҢй»ҳи®Өдјҡиҫ“еҮәеӯ—е…ёзҡ„key
from itertools import chain
import time
list_data = [1, 2, 3]
dict_data = {"a": 1, "b": 2}
set_data = {4, 5, 6}
print(list(chain(list_data, dict_data, set_data)))
list_data = [1, 2, 3]
list_data2 = [4, 5, 6]
start = time.time()
for i in range(100000):
chain(list_data, list_data2)
print(time.time() - start)
start = time.time()
for i in range(100000):
list_data.extend(list_data2)
print(time.time() - start)
#иҫ“еҮә
[1, 2, 3, 'a', 'b', 4, 5, 6]
0.012955427169799805
0.013965129852294922combinations(iterable: Iterable, r)
iterable:йңҖиҰҒж“ҚдҪңзҡ„еҸҜиҝӯд»ЈеҜ№иұЎ
r: жҠҪеҸ–зҡ„еӯҗеәҸеҲ—е…ғзҙ зҡ„дёӘж•°
ж“ҚдҪңеҸҜиҝӯд»ЈеҜ№иұЎпјҢж №жҚ®жүҖйңҖжҠҪеҸ–зҡ„еӯҗеәҸеҲ—дёӘж•°иҝ”еӣһеӯҗеәҸеҲ—пјҢеӯҗеәҸеҲ—дёӯзҡ„е…ғзҙ д№ҹжҳҜжңүеәҸгҖҒдёҚеҸҜйҮҚеӨҚ并且жҳҜд»Ҙе…ғз»„зҡ„еҪўејҸе‘ҲзҺ°зҡ„гҖӮ
from itertools import combinations
data = range(5)
print(tuple(combinations(data, 2)))
str_data = "asdfgh"
print(tuple(combinations(str_data, 2)))
#иҫ“еҮә
((0, 1), (0, 2), (0, 3), (0, 4), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4))
(('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'g'), ('f', 'h'), ('g', 'h'))combinations_with_replacement(iterable: Iterable, r)
дёҺдёҠиҝ°зҡ„combinations(iterable: Iterable, r)зұ»дјјпјҢдёҚиҝҮеҢәеҲ«еңЁдәҺпјҢcombinations_with_replacementзҡ„еӯҗеәҸеҲ—зҡ„е…ғзҙ еҸҜд»ҘйҮҚеӨҚпјҢд№ҹжҳҜжңүеәҸзҡ„пјҢе…·дҪ“еҰӮдёӢпјҡ
from itertools import combinations_with_replacement
data = range(5)
print(tuple(combinations_with_replacement(data, 2)))
str_data = "asdfgh"
print(tuple(combinations_with_replacement(str_data, 2)))
#иҫ“еҮә
((0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (1, 1), (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4))
(('a', 'a'), ('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 's'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'd'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'f'), ('f', 'g'), ('f', 'h'), ('g', 'g'), ('g', 'h'), ('h', 'h'))compress(data: Iterable, selectors: Iterable)
data:йңҖиҰҒж“ҚдҪңзҡ„еҸҜиҝӯд»ЈеҜ№иұЎ
selectors:еҲӨж–ӯзңҹеҖјзҡ„еҸҜиҝӯд»ЈеҜ№иұЎпјҢдёҚиғҪж—¶strпјҢжңҖеҘҪжҳҜеҲ—иЎЁгҖҒе…ғз»„гҖҒд№Ӣзұ»зҡ„
ж №жҚ®selectorsдёӯзҡ„е…ғзҙ жҳҜеҗҰдёәtrueжқҘиҫ“еҮәdataдёӯеҜ№еә”зҙўеј•зҡ„е…ғзҙ пјҢд»ҘжңҖзҹӯзҡ„дёәеҮҶпјҢиҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁгҖӮ
from itertools import compress
data = "asdfg"
list_data = [1, 0, 0, 0, 1, 4]
print(list(compress(data, list_data)))
#иҫ“еҮә
['a', 'g']
count(start, step)
start: ејҖе§Ӣзҡ„е…ғзҙ
step: иҮӘејҖе§Ӣе…ғзҙ еўһй•ҝзҡ„жӯҘй•ҝ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁпјҢд»ҺstartжҢүз…§жӯҘй•ҝйҖ’еўһпјҢдёҚдјҡдёҖж¬ЎжҖ§з”ҹжҲҗпјҢжңҖеҘҪдҪҝз”Ёnext()иҝӣиЎҢе…ғзҙ зҡ„йҖ’еҪ’зҡ„иҺ·еҸ–гҖӮ
from itertools import count
c = count(start=10, step=20)
print(next(c))
print(next(c))
print(next(c))
print(next(c))
print(c)
#иҫ“еҮә
10
30
50
70
count(90, 20)
cycle(iterable)
iterableпјҡ йңҖиҰҒеҫӘзҺҜиҫ“еҮәзҡ„еҸҜиҝӯд»ЈеҜ№иұЎ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁпјҢеҫӘзҺҜиҫ“еҮәеҸҜиҝӯд»ЈеҜ№иұЎзҡ„е…ғзҙ гҖӮдәҺcountдёҖж ·пјҢжңҖеҘҪдёҚиҰҒе°Ҷз»“жһңиҪ¬жҚўдёәеҸҜиҝӯд»ЈеҜ№иұЎпјҢеӣ дёәжҳҜеҫӘзҺҜпјҢжүҖд»Ҙе»әи®®дҪҝз”Ёnext()жҲ–иҖ…forеҫӘзҺҜиҺ·еҸ–е…ғзҙ гҖӮ
from itertools import cycle
a = "asdfg"
data = cycle(a)
print(next(data))
print(next(data))
print(next(data))
print(next(data))
#иҫ“еҮә
a
s
d
f
dropwhile(predicate, iterable)
predicate:жҳҜеҗҰиҲҚејғе…ғзҙ зҡ„ж ҮеҮҶ
iterable: еҸҜиҝӯд»ЈеҜ№иұЎ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁ,ж №жҚ®predicateжҳҜеҗҰдёәTrueжқҘиҲҚејғе…ғзҙ гҖӮеҪ“predicateдёәFalseж—¶пјҢеҗҺйқўзҡ„е…ғзҙ дёҚз®ЎжҳҜеҗҰдёәTrueйғҪдјҡиҫ“еҮәгҖӮ
from itertools import dropwhile
list_data = [1, 2, 3, 4, 5]
print(list(dropwhile(lambda i: i < 3, list_data)))
print(list(dropwhile(lambda x: x < 5, [1, 4, 6, 4, 1])))
#иҫ“еҮә
[3, 4, 5]
[6, 4, 1]
filterfalse(predicate, iterable)
predicate:жҳҜеҗҰиҲҚејғе…ғзҙ зҡ„ж ҮеҮҶ
iterable: еҸҜиҝӯд»ЈеҜ№иұЎ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁ, ж №жҚ®predicateжҳҜеҗҰдёәFalseеҲӨж–ӯиҫ“еҮәпјҢеҜ№жүҖжңүе…ғзҙ иҝӣиЎҢж“ҚдҪңгҖӮзұ»дјјдәҺfilterж–№жі•пјҢдҪҶжҳҜжҳҜfilterзҡ„зӣёеҸҚзҡ„.
import time
from itertools import filterfalse
print(list(filterfalse(lambda i: i % 2 == 0, range(10))))
start = time.time()
for i in range(100000):
filterfalse(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
start = time.time()
for i in range(100000):
filter(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
#иҫ“еҮә
[1, 3, 5, 7, 9]
0.276653528213501
0.2768676280975342
з”ұдёҠиҝ°з»“жһңзңӢеҮәпјҢfilterfalseдёҺfilterжҖ§иғҪзӣёе·®дёҚеӨ§
groupby(iterable, key=None)
iterable: еҸҜиҝӯд»ЈеҜ№иұЎ
key: еҸҜйҖүпјҢйңҖиҰҒеҜ№е…ғзҙ иҝӣиЎҢеҲӨж–ӯзҡ„жқЎд»¶, й»ҳи®Өдёәx == xгҖӮ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁ,ж №жҚ®keyиҝ”еӣһиҝһз»ӯзҡ„й”®е’Ңз»„пјҲиҝһз»ӯз¬ҰеҗҲkeyжқЎд»¶зҡ„е…ғзҙ пјүгҖӮ
жіЁж„ҸдҪҝз”ЁgroupbyиҝӣиЎҢеҲҶз»„еүҚйңҖиҰҒеҜ№е…¶иҝӣиЎҢжҺ’еәҸгҖӮ
from itertools import groupby
str_data = "babada"
for k, v in groupby(str_data):
print(k, list(v))
str_data = "aaabbbcd"
for k, v in groupby(str_data):
print(k, list(v))
def func(x: str):
print(x)
return x.isdigit()
str_data = "12a34d5"
for k, v in groupby(str_data, key=func):
print(k, list(v))
#иҫ“еҮә
b ['b']
a ['a']
b ['b']
a ['a']
d ['d']
a ['a']
a ['a', 'a', 'a']
b ['b', 'b', 'b']
c ['c']
d ['d']
1
2
a
True ['1', '2']
3
False ['a']
4
d
True ['3', '4']
5
False ['d']
True ['5']
islice(iterable, stop)\islice(iterable, start, stop[, step])
iterable: йңҖиҰҒж“ҚдҪңзҡ„еҸҜиҝӯд»ЈеҜ№иұЎ
startпјҡ ејҖе§Ӣж“ҚдҪңзҡ„зҙўеј•дҪҚзҪ®
stop: з»“жқҹж“ҚдҪңзҡ„зҙўеј•дҪҚзҪ®
step: жӯҘй•ҝ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁгҖӮзұ»дјјдәҺеҲҮзүҮпјҢдҪҶжҳҜе…¶зҙўеј•дёҚж”ҜжҢҒиҙҹж•°гҖӮ
from itertools import islice
import time
list_data = [1, 5, 4, 2, 7]
#еӯҰд№ дёӯйҒҮеҲ°й—®йўҳжІЎдәәи§Јзӯ”пјҹе°Ҹзј–еҲӣе»әдәҶдёҖдёӘPythonеӯҰд№ дәӨжөҒзҫӨпјҡ725638078
start = time.time()
for i in range(100000):
data = list_data[:2:]
print(time.time() - start)
start = time.time()
for i in range(100000):
data = islice(list_data, 2)
print(time.time() - start)
print(list(islice(list_data, 1, 3)))
print(list(islice(list_data, 1, 4, 2)))
#иҫ“еҮә
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]
з”ұдёҠиҝ°з»“жһңеҸҜд»ҘзңӢеҮәпјҢеҲҮзүҮжҖ§иғҪжҜ”isliceжҖ§иғҪзЁҚеҘҪдёҖдәӣгҖӮ
pairwise(iterable)
йңҖиҰҒж“ҚдҪңзҡ„еҸҜиҝӯд»ЈеҜ№иұЎ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁ, иҝ”еӣһеҸҜиҝӯд»ЈеҜ№иұЎдёӯзҡ„иҝһз»ӯйҮҚеҸ еҜ№пјҢе°‘дәҺдёӨдёӘиҝ”еӣһз©әгҖӮ
from itertools import pairwise
str_data = "asdfweffva"
list_data = [1, 2, 5, 76, 8]
print(list(pairwise(str_data)))
print(list(pairwise(list_data)))
#иҫ“еҮә
[('a', 's'), ('s', 'd'), ('d', 'f'), ('f', 'w'), ('w', 'e'), ('e', 'f'), ('f', 'f'), ('f', 'v'), ('v', 'a')]
[(1, 2), (2, 5), (5, 76), (76, 8)]permutations(iterable, r=None)
iterableпјҡ йңҖиҰҒж“ҚдҪңзҡ„еҸҜиҝӯд»ЈеҜ№иұЎ
r: жҠҪеҸ–зҡ„еӯҗеәҸеҲ—
дёҺcombinationsзұ»дјјпјҢйғҪжҳҜжҠҪеҸ–еҸҜиҝӯд»ЈеҜ№иұЎзҡ„еӯҗеәҸеҲ—пјҢдёҚиҝҮпјҢpermutationsжҳҜдёҚеҸҜйҮҚеӨҚ,ж— еәҸзҡ„пјҢ дёҺcombinations_with_replacementеҲҡеҘҪзӣёеҸҚгҖӮ
from itertools import permutations
data = range(5)
print(tuple(permutations(data, 2)))
str_data = "asdfgh"
print(tuple(permutations(str_data, 2)))
#иҫ“еҮә
((0, 1), (0, 2), (0, 3), (0, 4), (1, 0), (1, 2), (1, 3), (1, 4), (2, 0), (2, 1), (2, 3), (2, 4), (3, 0), (3, 1), (3, 2), (3, 4), (4, 0), (4, 1), (4, 2), (4, 3))
(('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'a'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'a'), ('d', 's'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'a'), ('f', 's'), ('f', 'd'), ('f', 'g'), ('f', 'h'), ('g', 'a'), ('g', 's'), ('g', 'd'), ('g', 'f'), ('g', 'h'), ('h', 'a'), ('h', 's'), ('h', 'd'), ('h', 'f'), ('h', 'g'))product(*iterables, repeat=1)
iterables: еҸҜиҝӯд»ЈеҜ№иұЎпјҢеҸҜд»ҘдёәеӨҡдёӘ
repeat: еҸҜиҝӯд»ЈеҜ№иұЎзҡ„йҮҚеӨҚж¬Ўж•°пјҢд№ҹе°ұжҳҜеӨҚеҲ¶зҡ„ж¬Ўж•°
иҝ”еӣһиҝӯд»ЈеҷЁгҖӮз”ҹжҲҗеҸҜиҝӯд»ЈеҜ№иұЎзҡ„з¬ӣеҚЎе°”з§Ҝ, зұ»дјјдәҺдёӨдёӘжҲ–еӨҡдёӘеҸҜиҝӯд»ЈеҜ№иұЎзҡ„жҺ’еҲ—з»„еҗҲгҖӮдёҺzipеҮҪж•°еҫҲеғҸпјҢдҪҶжҳҜzipжҳҜе…ғзҙ зҡ„дёҖеҜ№дёҖеҜ№еә”е…ізі»пјҢиҖҢproductеҲҷжҳҜдёҖеҜ№еӨҡзҡ„е…ізі»гҖӮ
from itertools import product
list_data = [1, 2, 3]
list_data2 = [4, 5, 6]
print(list(product(list_data, list_data2)))
print(list(zip(list_data, list_data2)))
# еҰӮдёӢдёӨдёӘеҗ«д№үжҳҜдёҖж ·зҡ„пјҢйғҪжҳҜе°ҶеҸҜиҝӯд»ЈеҜ№иұЎеӨҚеҲ¶дёҖд»ҪпјҢ еҫҲж–№дҫҝзҡ„иҝӣиЎҢеҗҢеҲ—иЎЁзҡ„ж“ҚдҪң
print(list(product(list_data, repeat=2)))
print(list(product(list_data, list_data)))
# еҗҢдёҠиҝ°еҗ«д№ү
print(list(product(list_data, list_data2, repeat=2)))
print(list(product(list_data, list_data2, list_data, list_data2)))
#иҫ“еҮә
[(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)]
[(1, 4), (2, 5), (3, 6)]
[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
[(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)]
[(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)]
repeat(object[, times])
objectпјҡд»»ж„ҸеҗҲжі•еҜ№иұЎ
times: еҸҜйҖүпјҢobjectеҜ№иұЎз”ҹжҲҗзҡ„ж¬Ўж•°, еҪ“дёҚдј е…ҘtimesпјҢеҲҷж— йҷҗеҫӘзҺҜ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁпјҢж №жҚ®timesйҮҚеӨҚз”ҹжҲҗobjectеҜ№иұЎгҖӮ
from itertools import repeat
str_data = "assd"
print(repeat(str_data))
print(list(repeat(str_data, 4)))
list_data = [1, 2, 4]
print(repeat(list_data))
print(list(repeat(list_data, 4)))
dict_data = {"a": 1, "b": 2}
print(repeat(dict_data))
print(list(repeat(dict_data, 4)))
#иҫ“еҮә
repeat('assd')
['assd', 'assd', 'assd', 'assd']
repeat([1, 2, 4])
[[1, 2, 4], [1, 2, 4], [1, 2, 4], [1, 2, 4]]
repeat({'a': 1, 'b': 2})
[{'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}]starmap(function, iterable)
function: дҪңз”Ёеҹҹиҝӯд»ЈеҷЁеҜ№иұЎе…ғзҙ зҡ„еҮҪж•°
iterable: еҸҜиҝӯд»ЈеҜ№иұЎ
иҝ”еӣһдёҖдёӘиҝӯд»ЈеҷЁ, е°ҶеҮҪж•°дҪңз”ЁдёҺеҸҜиҝӯд»ЈеҜ№иұЎзҡ„жүҖжңүе…ғзҙ пјҲжүҖжңүе…ғзҙ еҝ…йЎ»иҰҒжҳҜеҸҜиҝӯд»ЈеҜ№иұЎпјҢеҚідҪҝеҸӘжңүдёҖдёӘеҖјпјҢд№ҹйңҖиҰҒдҪҝз”ЁеҸҜиҝӯд»ЈеҜ№иұЎеҢ…иЈ№пјҢдҫӢеҰӮе…ғз»„(1, )пјүдёӯ,дёҺmapеҮҪж•°зұ»дјјпјӣеҪ“functionеҸӮж•°дёҺеҸҜиҝӯд»ЈеҜ№иұЎе…ғзҙ дёҖиҮҙж—¶пјҢдҪҝз”Ёе…ғз»„д»Јжӣҝе…ғзҙ пјҢдҫӢеҰӮpow(a, b)пјҢеҜ№еә”зҡ„жҳҜ[(2,3), (3,3)]гҖӮ
mapдёҺstarmapзҡ„еҢәеҲ«еңЁдәҺпјҢmapжҲ‘们дёҖиҲ¬дјҡж“ҚдҪңдёҖдёӘfunctionеҸӘжңүдёҖдёӘеҸӮж•°зҡ„жғ…еҶөпјҢstarmapеҸҜд»Ҙж“ҚдҪңfunctionеӨҡдёӘеҸӮж•°зҡ„жғ…еҶөгҖӮ
from itertools import starmap
list_data = [1, 2, 3, 4, 5]
list_data2 = [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)]
list_data3 = [(1,), (2,), (3,), (4,), (5,)]
print(list(starmap(lambda x, y: x + y, list_data2)))
print(list(map(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data3)))
#иҫ“еҮә
[2, 4, 6, 8, 10]
[1, 4, 9, 16, 25]
Traceback (most recent call last):
File "c:\Users\ts\Desktop\2022.7\2022.7.22\test.py", line 65, in <module>
print(list(starmap(lambda x: x * x, list_data)))
TypeError: 'int' object is not iterable
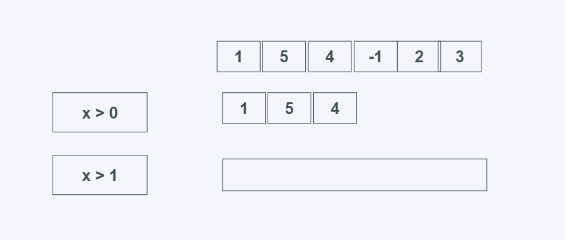
takewhile(predicate, iterable)
predicateпјҡеҲӨж–ӯжқЎд»¶пјҢдёәзңҹе°ұиҝ”еӣһ
iterable: еҸҜиҝӯд»ЈеҜ№иұЎ
еҪ“predicateдёәзңҹж—¶иҝ”еӣһе…ғзҙ пјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҪ“第дёҖдёӘе…ғзҙ дёҚдёәTrueж—¶пјҢеҲҷеҗҺйқўзҡ„ж— и®әз»“жһңеҰӮдҪ•йғҪдёҚдјҡиҝ”еӣһпјҢжүҫзҡ„еүҚеӨҡе°‘дёӘдёәTrueзҡ„е…ғзҙ гҖӮ
from itertools import takewhile
#еӯҰд№ дёӯйҒҮеҲ°й—®йўҳжІЎдәәи§Јзӯ”пјҹе°Ҹзј–еҲӣе»әдәҶдёҖдёӘPythonеӯҰд№ дәӨжөҒзҫӨпјҡ725638078
list_data = [1, 5, 4, 6, 2, 3]
print(list(takewhile(lambda x: x > 0, list_data)))
print(list(takewhile(lambda x: x > 1, list_data)))
zip_longest(*iterables, fillvalue=None)
iterablesпјҡеҸҜиҝӯд»ЈеҜ№иұЎ
fillvalueпјҡеҪ“й•ҝеәҰи¶…иҝҮж—¶пјҢзјәзңҒеҖјгҖҒй»ҳи®ӨеҖјпјҢ й»ҳи®ӨдёәNone
иҝ”еӣһиҝӯд»ЈеҷЁ, еҸҜиҝӯд»ЈеҜ№иұЎе…ғзҙ дёҖдёҖеҜ№еә”з”ҹжҲҗе…ғз»„пјҢеҪ“дёӨдёӘеҸҜиҝӯд»ЈеҜ№иұЎй•ҝеәҰдёҚдёҖиҮҙж—¶пјҢдјҡжҢүз…§жңҖй•ҝзҡ„жңүе…ғзҙ иҫ“еҮә并дҪҝз”ЁfillvalueиЎҘе……пјҢжҳҜzipзҡ„еҸҚеҗ‘жү©еұ•пјҢzipдёәжңҖе°Ҹй•ҝеәҰиҫ“еҮәгҖӮ
from itertools import zip_longest
list_data = [1, 2, 3]
list_data2 = ["a", "b", "c", "d"]
print(list(zip_longest(list_data, list_data2, fillvalue="-")))
print(list(zip_longest(list_data, list_data2)))
print(list(zip(list_data, list_data2)))
[(1, 'a'), (2, 'b'), (3, 'c'), ('-', 'd')]
[(1, 'a'), (2, 'b'), (3, 'c'), (None, 'd')]
[(1, 'a'), (2, 'b'), (3, 'c')]жҖ»з»“
accumulate(iterable: Iterable, func: None, initial:None)пјҡ
иҝӣиЎҢеҸҜиҝӯд»ЈеҜ№иұЎе…ғзҙ зҡ„зҙҜи®Ўиҝҗз®—пјҢеҸҜд»Ҙи®ҫзҪ®еҲқе§ӢеҖјпјҢзұ»дјјдәҺreduceпјҢзӣёжҜ”иҫғreduce,accumulateеҸҜд»Ҙиҫ“еҮәдёӯй—ҙиҝҮзЁӢзҡ„еҖјпјҢreduceеҸӘиғҪиҫ“еҮәжңҖеҗҺз»“жһңпјҢдё”accumulateжҖ§иғҪз•ҘеҘҪдәҺreduceгҖӮ
chain(*iterables)
дҫқж¬Ўиҫ“еҮәиҝӯд»ЈеҷЁдёӯзҡ„е…ғзҙ пјҢдёҚдјҡеҫӘзҺҜиҫ“еҮәпјҢжңүеӨҡе°‘иҫ“еҮәеӨҡе°‘гҖӮеҜ№дәҺеӯ—е…ёиҫ“еҮәе…ғзҙ ж—¶пјҢй»ҳи®Өдјҡиҫ“еҮәеӯ—е…ёзҡ„keyпјӣеҜ№дәҺеҲ—иЎЁжқҘиҜҙзӣёеҪ“дәҺжҳҜextendгҖӮ
combinations(iterable: Iterable, r)пјҡ
жҠҪеҸ–еҸҜиҝӯд»ЈеҜ№иұЎзҡ„еӯҗеәҸеҲ—пјҢе…¶е®һе°ұжҳҜжҺ’еҲ—з»„еҗҲпјҢдёҚиҝҮеҸӘиҝ”еӣһжңүеәҸгҖҒдёҚйҮҚеӨҚзҡ„еӯҗеәҸеҲ—пјҢд»Ҙе…ғз»„еҪўејҸе‘ҲзҺ°гҖӮ
combinations_with_replacement(iterable: Iterable, r)
жҠҪеҸ–еҸҜиҝӯд»ЈеҜ№иұЎзҡ„еӯҗеәҸеҲ—пјҢдёҺcombinationsзұ»дјјпјҢдёҚиҝҮиҝ”еӣһж— еәҸгҖҒдёҚйҮҚеӨҚзҡ„еӯҗеәҸеҲ—пјҢд»Ҙе…ғз»„еҪўејҸе‘ҲзҺ°гҖӮ
compress(data: Iterable, selectors: Iterable)
ж №жҚ®selectorsдёӯзҡ„е…ғзҙ жҳҜеҗҰдёәTrueжҲ–иҖ…Falseиҝ”еӣһеҸҜиҝӯд»ЈеҜ№иұЎзҡ„еҗҲжі•е…ғзҙ пјҢselectorsдёәstrж—¶пјҢйғҪдёәTrueпјҢ并且еҸӘдјҡеҶіе®ҡй•ҝеәҰгҖӮ
count(start, step)пјҡ
д»ҺstartејҖе§Ӣе®үиЈ…stepдёҚж–ӯз”ҹжҲҗе…ғзҙ пјҢжҳҜж— йҷҗеҫӘзҺҜзҡ„пјҢжңҖеҘҪжҺ§еҲ¶иҫ“еҮәдёӘж•°жҲ–иҖ…дҪҝз”Ёnext(),send()зӯүиҺ·еҸ–гҖҒи®ҫзҪ®з»“жһң
cycle(iterable)
дҫқж¬Ўиҫ“еҮәеҸҜиҝӯд»ЈеҜ№иұЎзҡ„е…ғзҙ пјҢжҳҜж— йҷҗеҫӘзҺҜзҡ„пјҢзӣёеҪ“дәҺжҳҜchainзҡ„еҫӘзҺҜгҖӮжңҖеҘҪжҺ§еҲ¶иҫ“еҮәдёӘж•°жҲ–иҖ…дҪҝз”Ёnext(),send()зӯүиҺ·еҸ–гҖҒи®ҫзҪ®з»“жһңгҖӮ
dropwhile(predicate, iterable)
ж №жҚ®predicateжҳҜеҗҰдёәFalseжқҘиҝ”еӣһеҸҜиҝӯд»ЈеҷЁе…ғзҙ пјҢpredicateеҸҜд»ҘдёәеҮҪж•°пјҢ иҝ”еӣһзҡ„жҳҜ第дёҖдёӘFalseеҸҠд№ӢеҗҺзҡ„жүҖжңүе…ғзҙ пјҢдёҚз®ЎеҗҺйқўзҡ„е…ғзҙ жҳҜеҗҰдёәTrueжҲ–иҖ…FalseгҖӮйҖӮз”ЁдәҺйңҖиҰҒиҲҚејғиҝӯд»ЈеҷЁжҲ–иҖ…еҸҜиҝӯд»ЈеҜ№иұЎзҡ„еүҚйқўдёҖйғЁеҲҶеҶ…е®№пјҢдҫӢеҰӮеңЁеҶҷе…Ҙж–Ү件时еҝҪз•Ҙж–ҮжЎЈжіЁйҮҠ
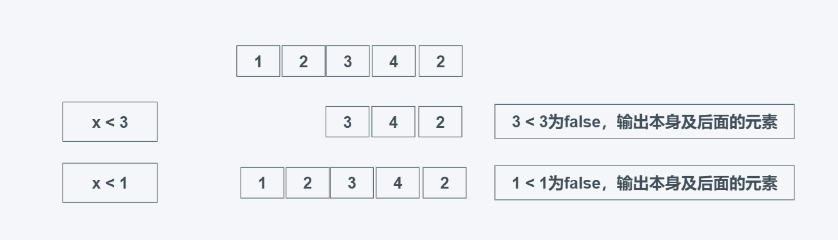
filterfalse(predicate, iterable)
дҫқжҚ®predicateиҝ”еӣһеҸҜиҝӯд»ЈеҜ№иұЎзҡ„жүҖжңүpredicateдёәTrueзҡ„е…ғзҙ пјҢзұ»дјјдәҺfilterж–№жі•гҖӮ
groupby(iterable, key=None)
иҫ“еҮәиҝһз»ӯз¬ҰеҗҲkeyиҰҒжұӮзҡ„й”®еҖјеҜ№пјҢй»ҳи®Өдёәx == xгҖӮ
islice(iterable, stop)\islice(iterable, start, stop[, step])
еҜ№еҸҜиҝӯд»ЈеҜ№иұЎиҝӣиЎҢеҲҮзүҮпјҢе’Ңжҷ®йҖҡеҲҮзүҮзұ»дјјпјҢдҪҶжҳҜиҝҷдёӘдёҚж”ҜжҢҒиҙҹж•°гҖӮйҖӮз”ЁдәҺеҸҜиҝӯд»ЈеҜ№иұЎеҶ…е®№зҡ„еҲҮеүІпјҢдҫӢеҰӮдҪ йңҖиҰҒиҺ·еҸ–дёҖдёӘж–Ү件дёӯзҡ„жҹҗеҮ иЎҢзҡ„еҶ…е®№
pairwise(iterable)
иҝ”еӣһиҝһз»ӯзҡ„йҮҚеҸ еҜ№иұЎпјҲдёӨдёӘе…ғзҙ пјүпјҢ е°‘дәҺдёӨдёӘе…ғзҙ иҝ”еӣһз©әпјҢдёҚиҝ”еӣһгҖӮ
permutations(iterable, r=None)
д»ҺеҸҜиҝӯд»ЈеҜ№иұЎдёӯжҠҪеҸ–еӯҗеәҸеҲ—пјҢдёҺcombinationsзұ»дјјпјҢдёҚиҝҮжҠҪеҸ–зҡ„еӯҗеәҸеҲ—жҳҜж— еәҸгҖҒеҸҜйҮҚеӨҚгҖӮ
product(*iterables, repeat=1)
иҫ“еҮәеҸҜиҝӯд»ЈеҜ№иұЎзҡ„з¬ӣеҚЎе°”з§ҜпјҢзұ»дјјдәҺжҺ’еәҸз»„еҗҲпјҢдёҚеҸҜйҮҚеӨҚ,жҳҜдёӨдёӘжҲ–иҖ…еӨҡдёӘеҸҜиҝӯд»ЈеҜ№иұЎиҝӣиЎҢж“ҚдҪңпјҢеҪ“жҳҜдёҖдёӘеҸҜиҝӯд»ЈеҜ№иұЎж—¶пјҢеҲҷиҝ”еӣһе…ғзҙ пјҢд»Ҙе…ғз»„еҪўејҸиҝ”еӣһгҖӮ
repeat(object[, times])
йҮҚеӨҚиҝ”еӣһobjectеҜ№иұЎпјҢй»ҳи®Өж—¶ж— йҷҗеҫӘзҺҜ
starmap(function, iterable)
жү№йҮҸж“ҚдҪңеҸҜиҝӯд»ЈеҜ№иұЎдёӯзҡ„е…ғзҙ пјҢж“ҚдҪңзҡ„еҸҜиҝӯд»ЈеҜ№иұЎдёӯзҡ„е…ғзҙ еҝ…йЎ»д№ҹиҰҒжҳҜеҸҜиҝӯд»ЈеҜ№иұЎпјҢдёҺmapзұ»дјјпјҢдҪҶжҳҜеҸҜд»ҘеҜ№зұ»дјјдәҺеӨҡе…ғзҙ зҡ„е…ғз»„иҝӣиЎҢж“ҚдҪңгҖӮ
takewhile(predicate, iterable)
иҝ”еӣһеүҚеӨҡе°‘дёӘpredicateдёәTrueзҡ„е…ғзҙ пјҢеҰӮжһң第дёҖдёӘдёәFalseпјҢеҲҷзӣҙжҺҘиҫ“еҮәдёҖдёӘз©әгҖӮ
zip_longest(*iterables, fillvalue=None)
е°ҶеҸҜиҝӯд»ЈеҜ№иұЎдёӯзҡ„е…ғзҙ дёҖдёҖеҜ№еә”пјҢз»„жҲҗе…ғз»„еҪўејҸеӯҳеӮЁпјҢдёҺzipж–№жі•зұ»дјјпјҢдёҚиҝҮzipжҳҜеҸ–жңҖзҹӯзҡ„пјҢиҖҢzip_longestжҳҜеҸ–жңҖй•ҝзҡ„пјҢзјәе°‘зҡ„дҪҝз”ЁзјәзңҒеҖјгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңPythonдёӯitertoolsжЁЎеқ—еҰӮдҪ•дҪҝз”ЁвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





