这篇文章主要介绍了Python怎么采集王者皮肤图片的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Python怎么采集王者皮肤图片文章都会有所收获,下面我们一起来看看吧。
我们在对王者英雄的主页,进行了分析,我们发现,其网页地址相似,就差一个数字。
https://pvp.qq.com/web201605/herodetail/{ename}.shtml我们可以把它当作为每个英雄的编号,我们可以从英雄列表获取编号,不过,这里我们直接请求第三方接口数据。
html_url ='https://www.sapi.run/hero/getHeroList.php'
datas = requests.get(html_url).json()['data']
for data in datas:
ename = data['ename']
cname = data['cname']
print(ename,cname)这段代码中,html_url 是一个 URL,指向一个 SAPI 的 Hero 列表页面。requests.get(html_url).json()['data'] 返回一个 JSON 对象,其中包含了 Hero 列表页面的数据。ename 和 cname 是 JSON 对象中的两个键值对,分别表示 Hero 的编号和名字。
在这段代码中,我们使用了一个 for 循环来遍历 JSON 对象中的每一个键值对,并打印出它们的值。这样就可以得到 Hero 列表页面中所有 Hero 的编号和名字。
我们拿到每一个英雄的编号之后,我们就可以访问每一个英雄的主页,我们在其主页可以看到他们的英雄名称和他们的英雄皮肤的地址。我们先获取英雄皮肤的名称。
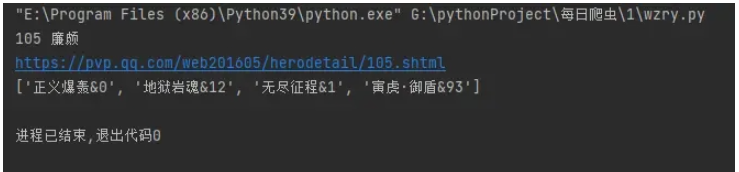
herodetail_url = f'https://pvp.qq.com/web201605/herodetail/{ename}.shtml'
print(herodetail_url)
res = requests.get(herodetail_url,headers=headers)
res.encoding = 'gbk'
# print(res.text)
pfs = re.findall('data-imgname="(.*?)"',res.text)[0]
pfs=pfs.split('|')
print(pfs)这段代码中,herodetail_url 是一个 URL,指向一个 Hero 详细页面。requests.get(herodetail_url,headers=headers) 返回一个 JSON 对象,其中包含了 Hero 详细页面的数据。res.encoding = 'gbk' 设置了 JSON 对象的编码方式为 GBK。re.findall('data-imgname="(.*?)"',res.text)[0] 使用正则表达式匹配 Hero 详细页面中的英雄名称,并返回第一个匹配项。pfs 是匹配项的值,它是一个包含英雄名称的列表。
接下来,我们对字段进行处理。
for pf in pfs:
pf = pf.split('&')[0]
# print(pf)
pf_list.append(pf)
print(len(pf_list))
print(pf_list)我们得到了这样的数据。['正义爆轰', '地狱岩魂', '无尽征程', '寅虎·御盾'],到了这里,我们皮肤名字就获取下来了。
pages = len(pfs)
for page in range(1,pages+1):
pf_url = f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{page}.jpg'
pf_url_list.append(pf_url)这段代码中,我们首先计算出 Hero 详细页面中图片的数量,然后使用 range 函数生成从 1 到 pages 的整数序列。接下来,我们使用一个循环来遍历这个序列,并将每个图片的 URL 添加到 pf_url_list 列表中。
最后,我们将 pf_url_list 列表中的所有 URL 连接起来,并将它们作为参数传递给 requests.get() 函数,以获取 Hero 详细页面的数据。
到这里,我们把所有皮肤的地址获取了下来。
for name,url in zip(pf_list,pf_url_list):
path = f'.//皮肤//{cname}//'
# print(path)
if not os.path.exists(path):
os.mkdir(path)
# print(cname,name,url)
pf_save = requests.get(url,headers=headers)
print(f"path + '{name}.jpg'")
with open(path + f'{name}.jpg', 'wb') as f:
f.write(pf_save.content)这段代码中,我们首先将 pf_list 和 pf_url_list 两个列表进行了 zip 操作,并将结果存储在 pf_list 和 pf_url_list 两个变量中。然后,我们使用 os.path.exists() 函数来检查 path 目录是否存在,如果不存在,则使用 os.mkdir() 函数创建该目录。接下来,我们使用 requests.get() 函数来获取 pf_url_list 列表中的每个 URL,并将它们作为参数传递给 requests.get() 函数,以获取 pf_list 列表中的每个 URL。
最后,我们使用 with open() 语句打开 path + '{name}.jpg' 文件,并将 pf_save.content 写入该文件中。这样就可以将 pf_list 和 pf_url_list 中的每个 URL 保存到 path + '{name}.jpg' 文件中。
关于“Python怎么采集王者皮肤图片”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Python怎么采集王者皮肤图片”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://juejin.cn/post/7221821674747494437



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



