PythonжҖҺд№ҲйҖҡиҝҮжүӢиӮҳжі•е®һзҺ°k_meansиҒҡзұ»
иҝҷзҜҮвҖңPythonжҖҺд№ҲйҖҡиҝҮжүӢиӮҳжі•е®һзҺ°k_meansиҒҡзұ»вҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңPythonжҖҺд№ҲйҖҡиҝҮжүӢиӮҳжі•е®һзҺ°k_meansиҒҡзұ»вҖқж–Үз« еҗ§гҖӮ
1.еҜје…Ҙmatplotlib.pylabе’ҢnumpyеҢ…
import matplotlib.pylab as plt
import numpy as np
2.е®ҡд№үе®һзҺ°йңҖиҰҒз”ЁеҲ°зҡ„еҮҪж•°
пјҲ1пјүи®Ўз®—дёӨзӮ№и·қзҰ»
# и®Ўз®—дёӨзӮ№и·қзҰ»
def distance(a, b):
return np.sqrt((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2)
пјҲ2пјүеҸ–йӣҶеҗҲзҡ„дёӯеҝғзӮ№
# еҸ–йӣҶеҗҲдёӯеҝғзӮ№
def means(arr):
x = 0
y = 0
for i in range(len(arr)):
x += arr[i][0]
y += arr[i][1]
if len(arr) > 0:
x /= len(arr)
y /= len(arr)
return np.array([x, y])
пјҲ3пјүеҜ»жүҫдёӢдёҖдёӘиҒҡзұ»дёӯеҝғзӮ№пјҢе…¶и·қзҰ»е·ІжүҫеҲ°зҡ„иҒҡзұ»дёӯеҝғзӮ№жңҖиҝңпјҢз”ЁдәҺеҲқе§ӢеҢ–иҒҡзұ»дёӯеҝғ
# еҜ»жүҫи·қзҰ»е·ІеҠ е…ҘиҒҡзұ»дёӯеҝғж•°з»„жңҖиҝңзҡ„зӮ№пјҢз”ЁдәҺеҲқе§ӢеҢ–иҒҡзұ»дёӯеҝғ
def farthest(k_arr, arr):
point = [0, 0]
max_dist = 0
for e in arr:
dist = 0
for i in range(len(k_arr)):
dist += distance(k_arr[i], e)
if dist > max_dist:
max_dist = dist
point = e
return point
3.k_meansж–№жі•
пјҲ1пјүе…ҲиҜ»еҸ–иЎЁдёӯзҡ„ж•°жҚ®
пјҲ2пјүеҰӮдҪ•йҡҸжңәиҺ·еҸ–е…¶дёӯдёҖдёӘзӮ№дҪңдёә第дёҖдёӘиҒҡзұ»дёӯеҝғ
пјҲ3пјүжҺҘдёӢжқҘжҜҸж¬ЎиҺ·еҸ–и·қзҰ»д№Ӣй—ҙжүҖжңүиҒҡзұ»дёӯеҝғзӮ№жңҖиҝңзҡ„зӮ№дҪңдёәдёӢдёҖдёӘиҒҡзұ»дёӯеҝғзӮ№
пјҲ4пјүжҜҸж¬Ўиҝӯд»Јж—¶пјҢйҒҚеҺҶйӣҶеҗҲдёӯзҡ„жүҖжңүзӮ№пјҢе°Ҷе…¶еҠ е…Ҙи·қзҰ»жңҖе°Ҹзҡ„иҒҡзұ»дёӯеҝғзӮ№ж•°з»„дёӯпјҢжӣҙж–°иҒҡзұ»дёӯеҝғ
пјҲ5пјүжңҖеҗҺе°Ҷж•°жҚ®еҸҜи§ҶеҢ–пјҢиҝ”еӣһеҲҶзұ»еҘҪзҡ„ж•°з»„
def k_means(k):
# иҜ»еҸ–ж•°жҚ®
kmeans_data = np.genfromtxt('kmeans_data.txt', dtype=float)
# еҲқе§ӢеҢ–
r = np.random.randint(len(kmeans_data) - 1)
k_arr = np.array([kmeans_data[r]])
class_arr = [[]]
for i in range(k - 1):
k_arr = np.concatenate([k_arr, np.array([farthest(k_arr, kmeans_data)])])
class_arr.append([])
# иҝӯд»ЈиҒҡзұ»
n = 20
class_temp = class_arr
for i in range(n): # иҝӯд»Јж¬Ўж•°
class_temp = class_arr
for e in kmeans_data: # жҠҠйӣҶеҗҲдёӯзҡ„жҜҸдёҖдёӘзӮ№иҒҡеҲ°зҰ»е®ғжңҖиҝ‘зҡ„зұ»
k_idx = 0 # еҒҮи®ҫи·қзҰ»з¬¬дёҖдёӘиҒҡзұ»дёӯеҝғжңҖиҝ‘
min_d = distance(e, k_arr[0])
for j in range(len(k_arr)): # иҺ·еҸ–и·қзҰ»иҜҘе…ғзҙ жңҖиҝ‘зҡ„иҒҡзұ»дёӯеҝғ
if distance(e, k_arr[j]) < min_d:
min_d = distance(e, k_arr[j])
k_idx = j
class_temp[k_idx].append(e) # жҠҠиҜҘе…ғзҙ еҠ еҲ°еҜ№еә”зҡ„зұ»дёӯ
# жӣҙж–°иҒҡзұ»дёӯеҝғ
for l in range(len(k_arr)):
k_arr[l] = means(class_temp[l])
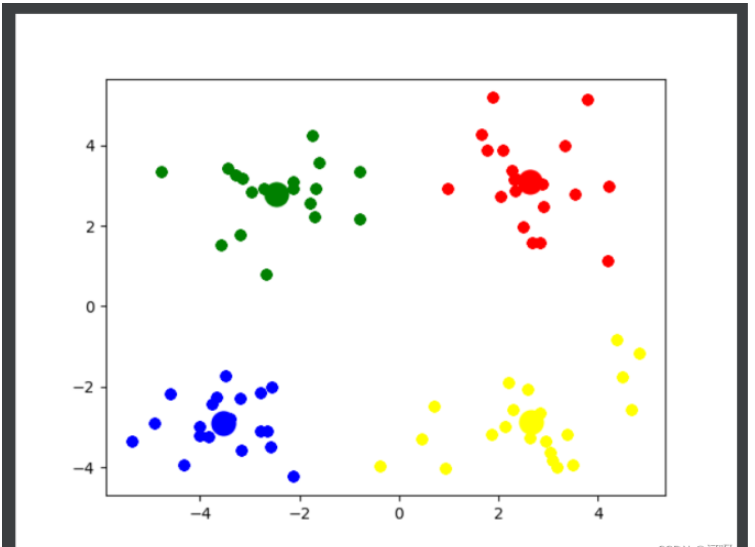
# е°Ҷж•°жҚ®еҸҜи§ҶеҢ–
col = ['red', 'blue', 'yellow', 'green', 'pink', 'black', 'purple', 'orange', 'brown']
for i in range(k):
plt.scatter(k_arr[i][0], k_arr[i][1], linewidths=10, color=col[i])
plt.scatter([e[0] for e in class_temp[i]], [e[1] for e in class_temp[i]], color=col[i])
plt.show()
# иҝ”еӣһеҲҶзұ»еҘҪзҡ„з°Ү
return class_temp4.жүӢиӮҳжі•иҺ·еҸ–жңҖдҪізҡ„kеҖј
пјҲ1пјүйҒҚеҺҶkеҖјзҡ„иҢғеӣҙпјҢд»Һ1еҲ°9
пјҲ2пјүkmeansиҺ·еҸ–еҲҶзұ»еҘҪзҡ„ж•°з»„
пјҲ3пјүйҒҚеҺҶkmeansи®Ўз®—еҜ№еә”зҡ„SSE
пјҲ4пјүз”»еҮәеҜ№еә”kеҖјзҡ„SSEзҡ„жҠҳзәҝеӣҫ
# йҖҡиҝҮиӮҳйғЁи§ӮеҜҹжі•иҺ·еҸ–kеҖј
def getK():
mean_dist = []
for k in range(1, 10):
# иҺ·еҸ–еҲҶжҲҗkз°ҮеҗҺзҡ„е…ғзҙ
kmeans = k_means(k)
sse = 0
# и®Ўз®—SSE
for i in range(len(kmeans)):
mean = means(kmeans[i])
for e in kmeans[i]:
sse += distance(mean, e) ** 2
mean_dist.append(sse)
# еҢ–жҲҗжҠҳзәҝеӣҫи§ӮеҜҹжңҖдҪізҡ„kеҖј
plt.plot(range(1, 10), mean_dist, 'bx-')
plt.ylabel('SSE')
plt.xlabel('k')
plt.show()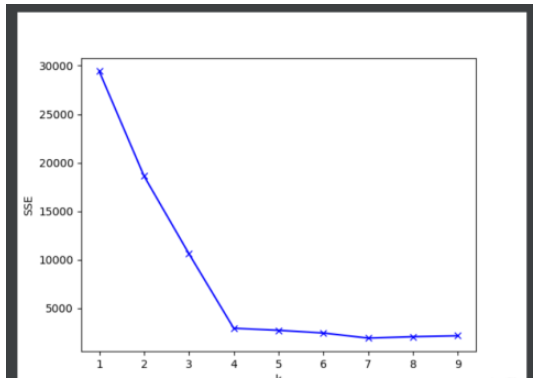
5. mainеҮҪж•°
if __name__ == '__main__':
getK()
# йҖҡиҝҮи§ӮеҜҹеҸҜзҹҘ, 4 жҳҜжңҖдҪізҡ„kеҖј
k_means(4)
6. е®Ңж•ҙд»Јз Ғ
import matplotlib.pylab as plt
import numpy as np
# и®Ўз®—дёӨзӮ№и·қзҰ»
def distance(a, b):
return np.sqrt((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2)
# еҸ–йӣҶеҗҲдёӯеҝғзӮ№
def means(arr):
x = 0
y = 0
for i in range(len(arr)):
x += arr[i][0]
y += arr[i][1]
if len(arr) > 0:
x /= len(arr)
y /= len(arr)
return np.array([x, y])
# еҜ»жүҫи·қзҰ»е·ІеҠ е…ҘиҒҡзұ»дёӯеҝғж•°з»„жңҖиҝңзҡ„зӮ№пјҢз”ЁдәҺеҲқе§ӢеҢ–иҒҡзұ»дёӯеҝғ
def farthest(k_arr, arr):
point = [0, 0]
max_dist = 0
for e in arr:
dist = 0
for i in range(len(k_arr)):
dist += distance(k_arr[i], e)
if dist > max_dist:
max_dist = dist
point = e
return point
def k_means(k):
# иҜ»еҸ–ж•°жҚ®
kmeans_data = np.genfromtxt('kmeans_data.txt', dtype=float)
# еҲқе§ӢеҢ–
r = np.random.randint(len(kmeans_data) - 1)
k_arr = np.array([kmeans_data[r]])
class_arr = [[]]
for i in range(k - 1):
k_arr = np.concatenate([k_arr, np.array([farthest(k_arr, kmeans_data)])])
class_arr.append([])
# иҝӯд»ЈиҒҡзұ»
n = 20
class_temp = class_arr
for i in range(n): # иҝӯд»Јж¬Ўж•°
class_temp = class_arr
for e in kmeans_data: # жҠҠйӣҶеҗҲдёӯзҡ„жҜҸдёҖдёӘзӮ№иҒҡеҲ°зҰ»е®ғжңҖиҝ‘зҡ„зұ»
k_idx = 0 # еҒҮи®ҫи·қзҰ»з¬¬дёҖдёӘиҒҡзұ»дёӯеҝғжңҖиҝ‘
min_d = distance(e, k_arr[0])
for j in range(len(k_arr)): # иҺ·еҸ–и·қзҰ»иҜҘе…ғзҙ жңҖиҝ‘зҡ„иҒҡзұ»дёӯеҝғ
if distance(e, k_arr[j]) < min_d:
min_d = distance(e, k_arr[j])
k_idx = j
class_temp[k_idx].append(e) # жҠҠиҜҘе…ғзҙ еҠ еҲ°еҜ№еә”зҡ„зұ»дёӯ
# жӣҙж–°иҒҡзұ»дёӯеҝғ
for l in range(len(k_arr)):
k_arr[l] = means(class_temp[l])
# е°Ҷж•°жҚ®еҸҜи§ҶеҢ–
col = ['red', 'blue', 'yellow', 'green', 'pink', 'black', 'purple', 'orange', 'brown']
for i in range(k):
plt.scatter(k_arr[i][0], k_arr[i][1], linewidths=10, color=col[i])
plt.scatter([e[0] for e in class_temp[i]], [e[1] for e in class_temp[i]], color=col[i])
plt.show()
# иҝ”еӣһеҲҶзұ»еҘҪзҡ„з°Ү
return class_temp
# йҖҡиҝҮиӮҳйғЁи§ӮеҜҹжі•иҺ·еҸ–kеҖј
def getK():
mean_dist = []
for k in range(1, 10):
# иҺ·еҸ–еҲҶжҲҗkз°ҮеҗҺзҡ„е…ғзҙ
kmeans = k_means(k)
sse = 0
# и®Ўз®—SSE
for i in range(len(kmeans)):
mean = means(kmeans[i])
for e in kmeans[i]:
sse += distance(mean, e) ** 2
mean_dist.append(sse)
# еҢ–жҲҗжҠҳзәҝеӣҫи§ӮеҜҹжңҖдҪізҡ„kеҖј
plt.plot(range(1, 10), mean_dist, 'bx-')
plt.ylabel('SSE')
plt.xlabel('k')
plt.show()
if __name__ == '__main__':
getK()
# йҖҡиҝҮи§ӮеҜҹеҸҜзҹҘ, 4 жҳҜжңҖдҪізҡ„kеҖј
k_means(4)д»ҘдёҠе°ұжҳҜе…ідәҺвҖңPythonжҖҺд№ҲйҖҡиҝҮжүӢиӮҳжі•е®һзҺ°k_meansиҒҡзұ»вҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





