python OCRж–Үеӯ—иҜҶеҲ«зҡ„ж–№жі•жңүе“Әдәӣ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢpython OCRж–Үеӯ—иҜҶеҲ«зҡ„ж–№жі•жңүе“Әдәӣзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
е°ҶеӣҫзүҮзҝ»иҜ‘жҲҗж–Үеӯ—дёҖиҲ¬иў«з§°дёәе…үеӯҰж–Үеӯ—иҜҶеҲ«пјҲOptical Character RecognitionпјҢOCRпјүгҖӮеҸҜд»Ҙе®һзҺ°OCR зҡ„еә•еұӮеә“并дёҚеӨҡпјҢзӣ®еүҚеҫҲеӨҡеә“йғҪжҳҜдҪҝз”Ёе…ұеҗҢзҡ„еҮ дёӘеә•еұӮOCR еә“пјҢжҲ–иҖ…жҳҜеңЁдёҠйқўиҝӣиЎҢе®ҡеҲ¶гҖӮ
ж–№жі•дёҖпјҡ дҪҝз”ЁeasyocrжЁЎеқ—
easyocrжҳҜеҹәдәҺtorchзҡ„ж·ұеәҰеӯҰд№ жЁЎеқ—
easyocrе®үиЈ…еҗҺи°ғз”ЁиҝҮзЁӢдёӯеҮәзҺ°opencvзүҲжң¬дёҚе…је®№й—®йўҳпјҢжүҖд»Ҙж”ҫејғжӯӨж–№жЎҲгҖӮ
ж–№жі•дәҢпјҡйҖҡиҝҮpytesseractи°ғз”Ёtesseract
дјҳзӮ№пјҡйғЁзҪІеҝ«пјҢиҪ»йҮҸзә§пјҢзҰ»зәҝеҸҜз”ЁпјҢе…Қиҙ№
зјәзӮ№пјҡиҮӘеёҰзҡ„дёӯж–Үеә“иҜҶеҲ«зҺҮиҫғдҪҺпјҢйңҖиҰҒиҮӘе·ұе»әж•°жҚ®иҝӣиЎҢи®ӯз»ғ
Tesseract жҳҜдёҖдёӘOCR еә“пјҢзӣ®еүҚз”ұGoogle иөһеҠ©пјҲGoogle д№ҹжҳҜдёҖ家д»ҘOCR е’ҢжңәеҷЁеӯҰд№ жҠҖжңҜй—»еҗҚдәҺдё–зҡ„е…¬еҸёпјүгҖӮTesseract жҳҜзӣ®еүҚе…¬и®ӨжңҖдјҳз§ҖгҖҒжңҖзІҫзЎ®зҡ„ејҖжәҗOCR зі»з»ҹгҖӮ
  йҷӨдәҶжһҒй«ҳзҡ„зІҫзЎ®еәҰпјҢTesseract д№ҹе…·жңүеҫҲй«ҳзҡ„зҒөжҙ»жҖ§гҖӮе®ғеҸҜд»ҘйҖҡиҝҮи®ӯз»ғиҜҶеҲ«еҮәд»»дҪ•еӯ—дҪ“пјҲеҸӘиҰҒиҝҷдәӣеӯ—дҪ“зҡ„йЈҺж јдҝқжҢҒдёҚеҸҳе°ұеҸҜд»ҘпјүпјҢд№ҹеҸҜд»ҘиҜҶеҲ«еҮәд»»дҪ•Unicode еӯ—з¬ҰгҖӮ
Tesseractзҡ„е®үиЈ…дёҺдҪҝз”Ё
python иҜҶеҲ«еӣҫзүҮдёҠзҡ„ж•°еӯ—пјҢдҪҝз”Ёpytesseractеә“д»ҺеӣҫеғҸдёӯжҸҗеҸ–ж–Үжң¬пјҢиҖҢиҜҶеҲ«еј•ж“ҺйҮҮз”Ё tesseract-ocrгҖӮ
pytesseractжҳҜpythonеҢ…иЈ…еҷЁпјҢе®ғдёәеҸҜжү§иЎҢж–Ү件жҸҗдҫӣдәҶpythonic APIгҖӮ
1гҖҒе®үиЈ…еҝ…иҰҒзҡ„еҢ…пјҡ
pip install pillow
pip install pytesseract
2гҖҒе®үиЈ…tesseract-ocrзҡ„иҜҶеҲ«еј•ж“Һ
жңҖж–°зүҲжң¬дёӢиҪҪең°еқҖпјҡ https://github.com/UB-Mannheim/tesseract/wiki
жҲ–иҖ…жӣҙеӨҡзүҲжң¬зҡ„tesseractдёӢиҪҪең°еқҖпјҡhttps://digi.bib.uni-mannheim.de/tesseract/гҖҖ
гҖҖ е®үиЈ…е®ҢеҗҺпјҢйңҖиҰҒе°ҶTesseractж·»еҠ еҲ°зі»з»ҹеҸҳйҮҸдёӯгҖӮ
гҖҖ зҺҜеўғеҸҳйҮҸпјҡ жҲ‘зҡ„з”өи„‘ ->еұһжҖ§ -> й«ҳзә§зі»з»ҹи®ҫзҪ® ->зҺҜеўғеҸҳйҮҸ ->зі»з»ҹеҸҳйҮҸ пјҢеңЁ path дёӯж·»еҠ е®үиЈ…и·Ҝеҫ„гҖӮ
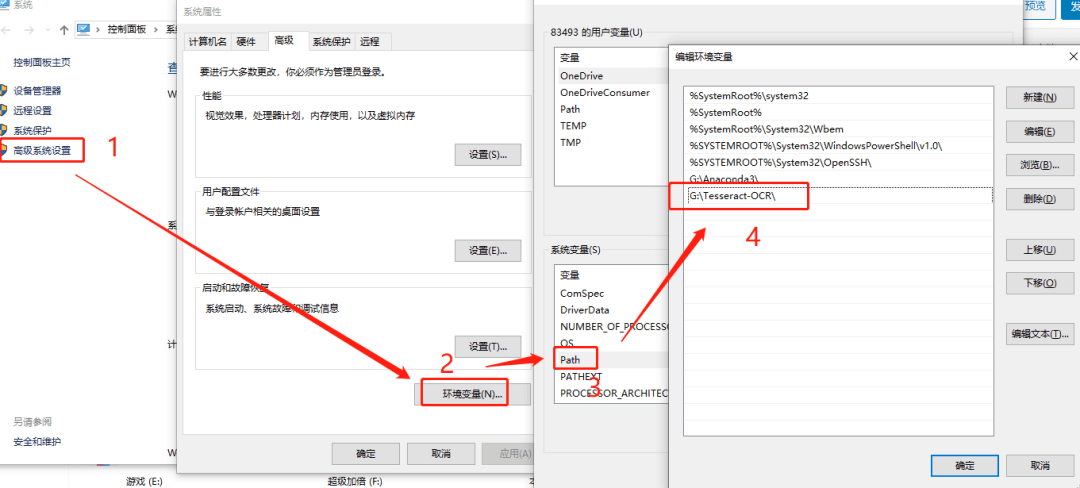
并е°Ҷи®ӯз»ғеҘҪзҡ„жЁЎеһӢж–Ү件 chi_sim.traineddata ж”ҫе…ҘиҜҘзӣ®еҪ•дёӯпјҢиҝҷж ·е®үиЈ…е°ұе®ҢжҲҗдәҶгҖӮ
еңЁе‘Ҫд»ӨиЎҢ WIN+R иҫ“е…Ҙcmd пјҡиҫ“е…Ҙ tesseract -v ,еҮәзҺ°зүҲжң¬дҝЎжҒҜпјҢеҲҷй…ҚзҪ®жҲҗеҠҹгҖӮ

tesseract-ocrй»ҳи®ӨдёҚж”ҜжҢҒдёӯж–ҮиҜҶеҲ«гҖӮж”ҜжҢҒдёӯж–ҮиҜҶеҲ«.png
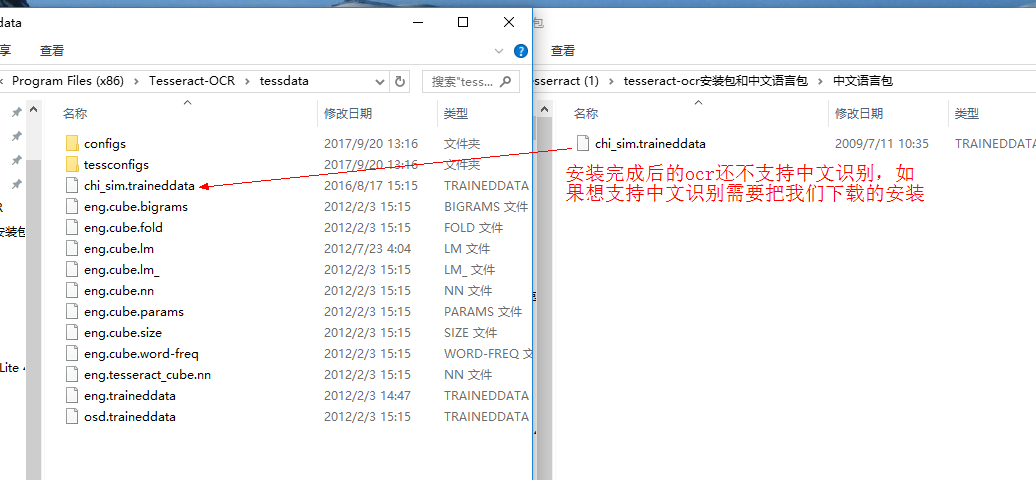
3гҖҒи§ЈеҶіpytesseract жүҫдёҚеҲ°и·Ҝеҫ„зҡ„й—®йўҳгҖӮ
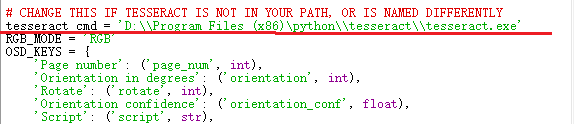
еңЁиҮӘе·ұе®үиЈ…зҡ„pytesseractеҢ…дёӯпјҢжүҫеҲ°pytesseract.pyж–Ү件
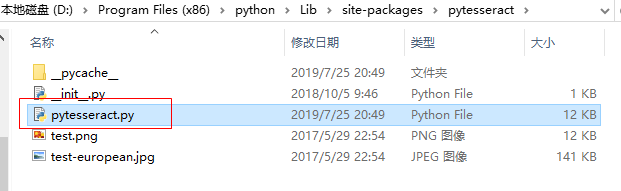
жү“ејҖpytesseract.pyж–Ү件пјҢдҝ®ж”№ tesseract_cmd зҡ„еҖјпјҡtesseract.exe зҡ„е®үиЈ…и·Ҝеҫ„ гҖӮ
дёәдәҶйҒҝе…Қе…¶д»–зҡ„й”ҷиҜҜпјҢдҪҝз”ЁеҸҢеҸҚж–ңжқ пјҢжҲ–иҖ…ж–ңжқ
4гҖҒз®ҖеҚ•дҪҝз”Ё
import pytesseract
from PIL import Image
if __name__ == '__main__':
text = pytesseract.image_to_string(Image.open("D:\\test.png"),lang="eng")
# еҰӮжһңдҪ жғіиҜ•иҜ•TesseractиҜҶеҲ«дёӯж–ҮпјҢеҸӘйңҖиҰҒе°Ҷд»Јз Ғдёӯзҡ„engж”№дёәchi_simеҚіеҸҜ
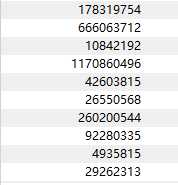
print(text)жөӢиҜ•еӣҫзүҮпјҡ
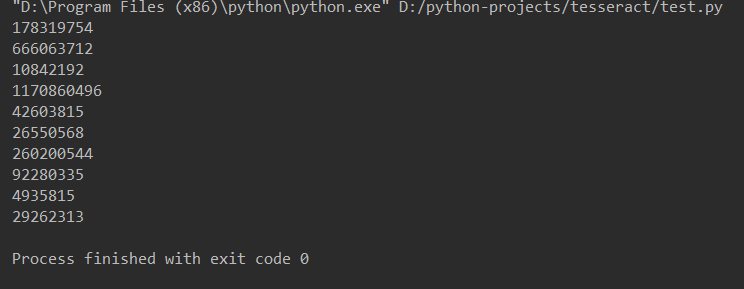
иҫ“еҮәз»“жһңпјҡ
з”ЁTesseractеҸҜд»ҘиҜҶеҲ«ж јејҸ规иҢғзҡ„ж–Үеӯ—пјҢдё»иҰҒе…·жңүд»ҘдёӢзү№зӮ№пјҡ
дҪҝз”ЁдёҖдёӘж ҮеҮҶеӯ—дҪ“пјҲдёҚеҢ…еҗ«жүӢеҶҷдҪ“гҖҒиҚүд№ҰпјҢжҲ–иҖ…еҚҒеҲҶвҖңиҠұе“Ёзҡ„вҖқеӯ—дҪ“пјү
иҷҪ然被еӨҚеҚ°жҲ–жӢҚз…§пјҢеӯ—дҪ“иҝҳжҳҜеҫҲжё…жҷ°пјҢжІЎжңүеӨҡдҪҷзҡ„з—•иҝ№жҲ–жұЎзӮ№
жҺ’еҲ—ж•ҙйҪҗпјҢжІЎжңүжӯӘжӯӘж–ңж–ңзҡ„еӯ—
жІЎжңүи¶…еҮәеӣҫзүҮиҢғеӣҙпјҢд№ҹжІЎжңүж®ӢзјәдёҚе…ЁпјҢжҲ–зҙ§зҙ§иҙҙеңЁеӣҫзүҮзҡ„иҫ№зјҳ
  дёӢйқўе°Ҷз»ҷеҮәеҮ дёӘtesseractиҜҶеҲ«еӣҫзүҮдёӯж–Үеӯ—зҡ„дҫӢеӯҗгҖӮ
  йҰ–е…ҲжҳҜE://figures/other/poems.jpg, иҫ“е…Ҙе‘Ҫд»Ө tesseract E://figures/other/poems.jpg E://figures/other/poems.txtпјҢ еҲҷдјҡе°Ҷpoems.jpgдёӯзҡ„иҜҶеҲ«ж–Үеӯ—еҶҷе…ҘеҲ°poems.txtдёӯпјҢеҰӮдёӢеӣҫпјҡ



жҺҘзқҖжҳҜзЁҚеҫ®жңүзӮ№еҖҫж–ңзҡ„ж–Үеӯ—еӣҫзүҮth.jpg,иҜҶеҲ«жғ…еҶөеҰӮдёӢпјҡ

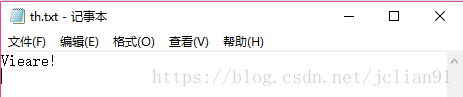
еҸҜд»ҘзңӢеҲ°иҜҶеҲ«зҡ„жғ…еҶөдёҚеҰӮеҲҡжүҚ规иҢғеӯ—дҪ“зҡ„еҘҪпјҢдҪҶжҳҜд№ҹиғҪиҜҶеҲ«еӣҫзүҮдёӯзҡ„еӨ§йғЁеҲҶеӯ—жҜҚгҖӮ
жңҖеҗҺжҳҜиҜҶеҲ«з®ҖдҪ“дёӯж–ҮпјҢйңҖиҰҒдәӢе…Ҳе®үиЈ…з®ҖдҪ“дёӯж–ҮиҜӯиЁҖеҢ…пјҢеҶҚи®Іchi_sim.traineddataж”ҫеңЁC:\Program Files (x86)\Tesseract-OCR\tessdataзӣ®еҪ•дёӢгҖӮжҲ‘们д»ҘеӣҫзүҮtimg.jpgдёәдҫӢпјҡ

иҫ“е…Ҙе‘Ҫд»Өпјҡ
tesseract E://figures/other/timg.jpg E://figures/other/timg.txt -l chi_sim
иҜҶеҲ«з»“жһңеҰӮдёӢпјҡ

еҸӘиҜҶеҲ«й”ҷдәҶдёҖдёӘеӯ—пјҢиҜҶеҲ«зҺҮиҝҳжҳҜдёҚй”ҷзҡ„гҖӮ
жңҖеҗҺеҠ дёҖеҸҘпјҢTesseractеҜ№дәҺеҪ©иүІеӣҫзүҮзҡ„иҜҶеҲ«ж•ҲжһңжІЎжңүй»‘зҷҪеӣҫзүҮзҡ„ж•ҲжһңеҘҪгҖӮ
pytesseract
pytesseractжҳҜTesseractе…ідәҺPythonзҡ„жҺҘеҸЈпјҢеҸҜд»ҘдҪҝз”Ёpip install pytesseractе®үиЈ…гҖӮе®үиЈ…е®ҢеҗҺпјҢе°ұеҸҜд»ҘдҪҝз”ЁPythonи°ғз”ЁTesseractдәҶпјҢдёҚиҝҮпјҢдҪ иҝҳйңҖиҰҒдёҖдёӘPythonзҡ„еӣҫзүҮеӨ„зҗҶжЁЎеқ—пјҢеҸҜд»Ҙе®үиЈ…pillow.
  иҫ“е…Ҙд»ҘдёӢд»Јз ҒпјҢеҸҜд»Ҙе®һзҺ°еҗҢдёҠиҝ°Tesseractе‘Ҫд»ӨдёҖж ·зҡ„ж•Ҳжһңпјҡ
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('E://figures/other/poems.jpg'))
print(text)иҝҗиЎҢз»“жһңеҰӮдёӢпјҡ

cnocr 第дәҢз§Қ Python ејҖжәҗиҜҶеҲ«е·Ҙе…·зҡ„ж•Ҳжһң
дёӨдёӘе·Ҙе…·зҡ„дҪҝз”Ёж–№жі•е’ҢеҜ№жҜ”ж•ҲжһңгҖӮ
е®үиЈ… cnocrпјҡ
pip install cnocr
зңӢеҲ° Successfully installed xxx еҲҷиҜҙжҳҺе®үиЈ…жҲҗеҠҹгҖӮ
еҰӮжһңдҪ еҸӘжғіеҜ№еӣҫзүҮдёӯзҡ„дёӯж–ҮиҝӣиЎҢиҜҶеҲ«пјҢйӮЈд№Ҳ cnocr жҳҜдёҖдёӘдёҚй”ҷзҡ„йҖүжӢ©пјҢдҪ еҸӘйңҖиҰҒе®үиЈ… cnocr еҢ…еҚіеҸҜгҖӮ
дҪҶеҰӮжһңдҪ жғіиҜ•иҜ•е…¶д»–иҜӯиЁҖзҡ„OCRиҜҶеҲ«пјҢTesseract жҳҜжӣҙеҘҪзҡ„йҖүжӢ©гҖӮ
cnocr иҜҶеҲ«еӣҫзүҮзҡ„дёӯж–Ү
cnocr дё»иҰҒй’ҲеҜ№зҡ„жҳҜжҺ’зүҲз®ҖеҚ•зҡ„еҚ°еҲ·дҪ“ж–Үеӯ—еӣҫзүҮпјҢеҰӮжҲӘеӣҫеӣҫзүҮпјҢжү«жҸҸ件зӯүгҖӮзӣ®еүҚеҶ…зҪ®зҡ„ж–Үеӯ—жЈҖжөӢе’ҢеҲҶиЎҢжЁЎеқ—ж— жі•еӨ„зҗҶеӨҚжқӮзҡ„ж–Үеӯ—жҺ’зүҲе®ҡдҪҚгҖӮ
е°Ҫз®Ўе®ғеҲҶеҲ«жҸҗдҫӣдәҶеҚ•иЎҢиҜҶеҲ«еҮҪж•°е’ҢеӨҡиЎҢиҜҶеҲ«еҮҪж•°пјҢдҪҶеңЁжң¬дәәе®һжөӢдёӢпјҢеҚ•иЎҢиҜҶеҲ«еҮҪж•°зҡ„ж•Ҳжһңйқһеёёзіҹзі•пјҢжҲ–иҖ…иҜҙиҰҒжұӮзҡ„жқЎд»¶еҚҒеҲҶиӢӣеҲ»пјҢеҹәжң¬дёҠиҝһжҲӘеӣҫзҡ„ж–Үеӯ—йғҪиҜҶеҲ«дёҚеҮәжқҘгҖӮ
дёҚиҝҮеӨҡиЎҢиҜҶеҲ«еҮҪж•°иҝҳдёҚй”ҷпјҢдҪҝз”ЁиҜҘеҮҪж•°иҜҶеҲ«зҡ„д»Јз ҒеҰӮдёӢпјҡ
from cnocr import CnOcr
ocr = CnOcr()
res = ocr.ocr('test.png')
print("Predicted Chars:", res)з”ЁдәҺиҜҶеҲ«иҝҷдёӘеӣҫзүҮйҮҢзҡ„ж–Үеӯ—пјҡ
ж•ҲжһңеҰӮдёӢпјҡ

еҰӮжһңдёҚжҳҜеҫҲеҗ№жҜӣжұӮз–өпјҢиҝҷж ·зҡ„ж•Ҳжһңе·Із»ҸеҫҲдёҚй”ҷдәҶгҖӮ
ж–№жі•дёүпјҡи°ғз”ЁзҷҫеәҰAPI
дјҳзӮ№пјҡдҪҝз”Ёж–№дҫҝпјҢеҠҹиғҪејәеӨ§
зјәзӮ№пјҡеӨ§йҮҸдҪҝз”ЁйңҖиҰҒ收иҙ№
жҲ‘иҮӘе·ұйҮҮз”Ёзҡ„жҳҜи°ғз”ЁзҷҫеәҰAPIзҡ„ж–№ејҸпјҢдёӢйқўжҳҜжҲ‘зҡ„жӯҘйӘӨпјҡ
жіЁеҶҢзҷҫеәҰиҙҰеҸ·пјҢеҲӣе»әOCRеә”з”ЁеҸҜд»ҘеҸӮиҖғе…¶д»–ж•ҷзЁӢгҖӮ
иҙӯд№°еҗҺдҪҝз”Ёpythonи°ғз”Ёж–№жі•
ж–№ејҸдёҖпјҡ йҖҡиҝҮurllibзӣҙжҺҘи°ғз”ЁпјҢжӣҝжҚўиҮӘе·ұзҡ„api_keyе’Ңsecret_keyеҚіеҸҜ
# coding=utf-8
import sys
import json
import base64
# дҝқиҜҒе…је®№python2д»ҘеҸҠpython3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
# йҳІжӯўhttpsиҜҒд№Ұж ЎйӘҢдёҚжӯЈзЎ®
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
API_KEY = 'YsZKG1wha34PlDOPYaIrIIKO'
SECRET_KEY = 'HPRZtdOHrdnnETVsZM2Nx7vbDkMfxrkD'
OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
""" TOKEN start """
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
"""
иҺ·еҸ–token
"""
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
"""
иҜ»еҸ–ж–Ү件
"""
def read_file(image_path):
f = None
try:
f = open(image_path, 'rb')
return f.read()
except:
print('read image file fail')
return None
finally:
if f:
f.close()
"""
и°ғз”ЁиҝңзЁӢжңҚеҠЎ
"""
def request(url, data):
req = Request(url, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
if __name__ == '__main__':
# иҺ·еҸ–access token
token = fetch_token()
# жӢјжҺҘйҖҡз”Ёж–Үеӯ—иҜҶеҲ«й«ҳзІҫеәҰurl
image_url = OCR_URL + "?access_token=" + token
text = ""
# иҜ»еҸ–жөӢиҜ•еӣҫзүҮ
file_content = read_file('test.jpg')
# и°ғз”Ёж–Үеӯ—иҜҶеҲ«жңҚеҠЎ
result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
# и§Јжһҗиҝ”еӣһз»“жһң
result_json = json.loads(result)
print(result_json)
for words_result in result_json["words_result"]:
text = text + words_result["words"]
# жү“еҚ°ж–Үеӯ—
print(text)ж–№ејҸдәҢпјҡйҖҡиҝҮHTTP-SDKжЁЎеқ—иҝӣиЎҢи°ғз”Ё
from aip import AipOcr
APP_ID = '25**9878'
API_KEY = 'VGT8y***EBf2O8xNRxyHrPNr'
SECRET_KEY = 'ckDyzG*****N3t0MTgvyYaKUnSl6fSw'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('test.jpg')
res = client.basicGeneral(image)
print(res)
#res = client.basicAccurate(image)
#print(res)зӣҙжҺҘиҜҶеҲ«еұҸ幕жҢҮе®ҡеҢәеҹҹдёҠзҡ„ж–Үеӯ—
from aip import AipOcr
APP_ID = '25**9878'
API_KEY = 'VGT8y***EBf2O8xNRxyHrPNr'
SECRET_KEY = 'ckDyzG*****N3t0MTgvyYaKUnSl6fSw'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY)
from io import BytesIO
from PIL import ImageGrab
out_buffer = BytesIO()
img = ImageGrab.grab((100,200,300,400))
img.save(out_buffer,format='PNG')
res = client.basicGeneral(out_buffer.getvalue())
print(res)
д»ҘдёҠе°ұжҳҜвҖңpython OCRж–Үеӯ—иҜҶеҲ«зҡ„ж–№жі•жңүе“ӘдәӣвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





