一、Nagios概述
1、简介
Nagios是插件式的结构,它本身没有任何监控功能,所有的监控都是通过插件进行的,因此其是高度模块化和富于弹性的。Nagios监控的对象可分为两类:主机和服务。主机通常指的是物理主机,如服务器、路由器、工作站和打印机等,这里的主机也可以是虚拟设备,如xen虚拟出的Linux系统;而服务通常指某个特定的功能,如提供http服务的httpd进程等。而为了管理上的方便,主机和服务还可以分别被规划为主机组和服务组等。
Nagios不监控任何具体数值指标(如操作系统上的进程个数),它仅用四种抽象属性对被监控对象的状态进行描述:OK、WARNING,CRITICAL和UNKNOWN。于是,管理员只需要对某种被监控对象的WARNING和CRITICAL状态的阈值进行关注和定义即可。Nagios通过将WARNING和CRITCAL的阈值传递给插件,并由插件负责某具体对象的监控及结果分析,其输出信息为状态信息(OK,WARNING,CRITICAL或UNKOWN)以及一些附加的详细说明信息。
2、特性
由上述说明可以,Nagios是极富弹性的,其监控功能完全可以按照管理员的期望进行。此外,它外提供了对问题的自动响应能力和一个功能强大的通知系统。所有这些功能的实现是基于一个结构明晰的对象定义系统和少数几个对象类型实现的。
1) 命令(Commands)
“命令”用于定义Nagios如何执行某特定的监控工作。它是基于某特定的Nagios插件定义出的一个抽象层,通常包含一组要执行的操作。
2)时段(Time periods)
“时段”用于定义某“操作”可以执行或不能执行的日期和时间跨度,如工作日内的每天8:00-18:00等;
3)联系人和联系人组(Contactsand contact groups)
“联系人”用于定义某监控事件的通知对象、要通知的信息以及这些接收通知者何时及如何接收通知;一个或多个联系人可以定义为联系人组,而一个联系人也可以属于多个组;
4) 主机和主机组(host andhost groups)
“主机”通常指某物理主机,其包括此主机相关的通知信息的接收者(即联系人)、如何及何时进行监控的定义。主机也可以分组,即主机组(hostgroups),一个主机可同时属于多个组;
5) 服务(Services)
“服务”通常指某主机上可被监控的特定的功能或资源,其包括此服务相关的通知信息的接收者、如何及何时进行监控等。服务也可以分组,即服务组(Serviceg
roups),一个服务可同时属于多个服务组;
3、依赖关系
Nagios的强大功能还表现在其成熟的依赖关系系统上。比如,某路由设备故障必然会导致关联在其上的其它主机无法被正常访问,如果不能定义这些设备间的依赖关系,那么监控系统上必然会出现大量的设备故障信息。而Nagios则通过依赖关系来描述网络设备的拓扑结构,并能够实现在某设备故障时不再对依赖于此设备的其它设备进行检测,从而避免了无谓的故障信息,方便管理员及时定位并排除故障。此外,Nagios的依赖关系还可以在服务级别上实现,如果某服务依赖于其它服务时,也能实现类似主机依赖关系的功能。
4、宏
Nagios还能够使用宏,并且宏的定义在整个Nagios系统中具有一致性。宏是能够用于对象定义中的变量,其值通常依赖于上下文。在“命令”中定义的宏,相对于主机、服务或其它许多参数来说,其值会随之不同。比如,某命令可以根据向其传递的IP地址的不同来监控不同的主机。
5、计划中宕机
Nagios还提供了调度性计划中的宕机机制,管理员可以周期性的设定某主机或服务为计划中的不可用状态。这种功能可以阻止Nagios在调度宕机时段通知任何信息。当然,这也可以让Nagios自动通知管理员该进行主机或服务维护了。
6、软状态和硬状态(Soft andHard States)
如上所述,Nagios的主要工作是检测主机或服务的状态,并将其存储下来。某一时刻,主机或服务状态仅可以是四种可用状态之一,因此,其状态能够正确反映主机或服务的实际状况就显得特别关键。为了避免某偶然的临时性或随机性问题,Nagios引入了软状态和硬状态。在实际的检测中,Nagios一旦发现某主机或服务的状态为UNKOWN或不同于上一次检测时的状态,其将会对此主机或服务进行多次测试以确保此状态的变动是非偶然性的。具体共要做出几次测试是可以配置的,在这个指定次数的测试时段内,Nagios假设此变化后的状态为软状态。一旦测试完成后状态仍然为新变的状态时,此状态就成了硬状态。
Nagios工作模式:
组织架构:
Nagios各组件调用:
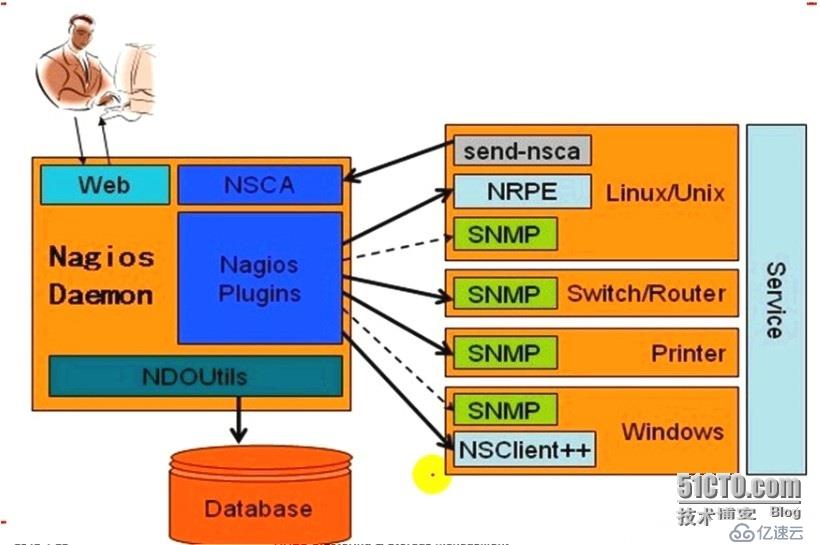
Nagios支持的插件类型:
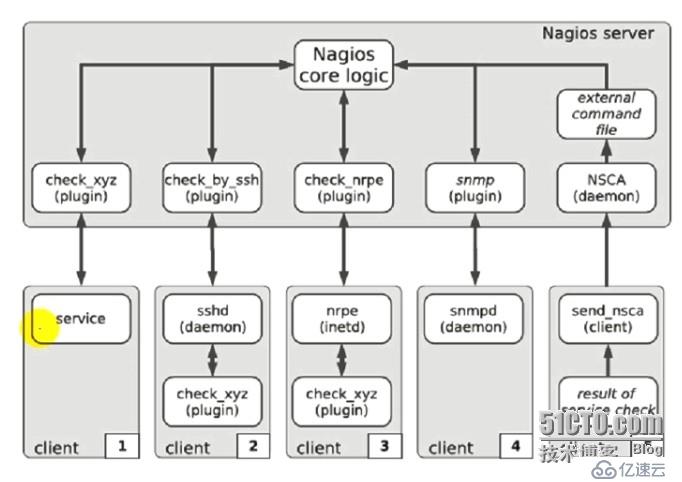
可以对插件进行分类:
1、ssh类的插件:客户端需要运行sshd进程,然后nagios发送ssh类的命令到客户端,客户端把获得的信息返回给ssh类的插件,ssh类插件通过分析把结果返给Nagios核心,核心决定是否对分析结果进行报警。
2、nrpe类的插件:专门用于监控linux、unix主机的机制,需要在客户端上安装nrpe服务进程,服务需要运行起来,而且nrpe需要装上各种nagios的插件,这种插件在本地实现运行,然后收集的信息本地实现分析,分析以后由客户端的nrpe发送到服务端的nrpe,然后再有服务端的nrpe发送给Nagios核心,核心再决定是否对分析结果进行报警。这种机制比较特殊,nagios的服务端和客户端有一层nrpe的客户端和服务端的架构,nrpe的服务端安装在nagios的客户端上,nrpe的客户端安装在nagios的服务端上,nrpe的客户端可以发送指令给nrpe的服务端,让服务端帮忙监控指定的资源,通过插件来监控指定的资源;实际上windows也可以使用类似于nrpe的机制来实现监控,但是他不叫nrpe,而叫NSClient++,专门装在windows上的客户端工具,这个工具在windows上运行起来以后,也可以实现nagios和window是通信,来获取windows上的资源来实现监控,NSClient++是一个windows上的wmi组件,可以实现获得windows上的性能状态数据,并把这个数据返回给nagios服务端上的插件,然后再由插件返回给nagios核心,最终实现结果监控。
3、snmp类的插件:和cacti的机制一样,在nagios的客户上上运行snmp的服务进程,然后nagios服务端使用snmp的命令来获取nagios客户端的信息,然后返回给Nagios核心,这个只针对支持snmp的,nagios并不优先使用snmp协议。
4、nsca类的插件:nagios上的被动监控机制,等待客户端返回信息给服务端,nagios并不主动收集信息;nsca服务端运行在nagios服务器上,nagios客户端上运行的是nsca客户端。在冗余监控模式下特别要用到。
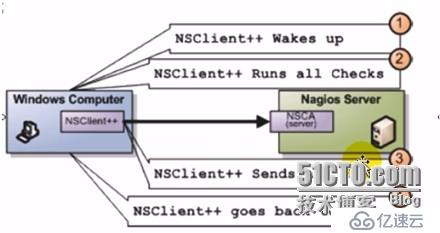
5、自定义的插件:
创建一个命令的过程就是一个实例化插件的过程
nagios强大到可以分析依赖关系,比如主机故障了,就不会继续监控主机上的服务了,因为主机因为挂了,主机上的服务肯定都检测不到了
状态分为软状态和硬状态
软状态 | 当监控发现转变的时候,他会重复进行多次检测,前几次状态的检测是软状态,不会发送告警通知 |
硬状态 | 如果多次检测结果还是一样的话,就变成了硬状态 |
不同状态之间转换被称为flapping,这种状态也也要发送通知,可以自己定义
通过web接口来展现出来
需要安装php,需要安装mysql来存储库文件
Nagios组成:
主程序(Nagios):
一个插件程序(Nagios-plugins):
四个可选的ADDON(NRPE、NSCA、NSClient++和NDOUtil):
NDOUtils:用来将Nagios的配置信息和各时间产生的数据存入数据库,以实现这些数据的快速检索和处理
在这四个ADDON中,NRPE和NSClient++工作于客户端,NDOUtils工作于服务器端,而NSCA则需要同时安装在服务器端和客户端
实验环境:
nagios服务端:node4 192.168.0.4
nagios客户端:node3 192.168.0.3 linux
nagios客户端:192.168.0.5 windows sever 2003
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





