一、生成式
1、定义
生成式就是一个用来快速生成特定语法形式的表达式。
列表生成式:用来快速生成列表
字典生成式:用来快速生成字典
集合生成式:用来快速生成集合
2、语法格式
(1)普通的语法格式:[exp for iter_var in iterable]
(2)带过滤功能语法格式: [exp for iter_var in iterable if_exp]
(3)循环嵌套语法格式: [exp for iter_var_A in iterable_A for iter_var_B in iterable_B]
#需求: 生成100个1~50之间的随机数值。
import random
def use_list_expression(count=100, start=0, end=50):
"""第一种: 使用列表生成式实现需求"""
return [random.randint(start, end) for count in range(count)]
def use_loop(count=100, start=0, end=50):
"""第二种: 使用for循环与传统的方式实现需求"""
nums = []
for count in range(count):
num = random.randint(start, end)
nums.append(num)
return nums
print(use_list_expression(count=5))
print(use_loop(count=8))"""#需求: 找出1-100之间能被3整除的数值;
def use_loop(start=1, end=100, div_num=3):
"""使用传统的方式实现需求"""
nums = []
for num in range(start, end + 1):
if num % div_num == 0:
nums.append(num)
return nums
def use_list_expression(start=1, end=100, div_num=3):
"""使用列表生成式实现需求"""
return [num for num in range(start, end + 1) if num % div_num == 0]
print(use_loop(1, 10, 4))
print(use_loop(div_num=50))
"""nums = [item1+ item2 for item1 in 'abc' for item2 in '123']
print(nums)
nums = []
for item1 in 'abc': # item1='a' item1='b' item1='c'
for item2 in '123': # item2='1', '2', '3' item2='1', '2', '3' item2='1', '2', '3'
nums.append(item1 + item2)
print(nums)#需求: 生成100个1~200之间的随机且不重复数值。
import random
nums = {random.randint(1, 200) for count in range(100)}
print(nums)
nulldict = {
'key1' : 'value1',
'key1' : 'value1'
}
import pprint
#需求: 生成100个用户字典, key是用户名userx(x=1, 2, 3, ....), value是密码passwordx(x=1, 2, 3...)
users_info = {'user' + str(x+1): 'password'+ str(x+1) for x in range(100)}
pprint.pprint(users_info)"""
nullimport math
def circle_example():
"""求以r为半径的圆的面积和周长(r的范围从1到10)。"""
square = lambda r: math.pi * (r ** 2)
C = lambda r: 2 * math.pi * r
return [(square(r), C(r)) for r in range(1, 11)]
def swap_key_value(dictObj):
"""将字典的key值和value值调换"""
return {value: key for key, value in dictObj.items()}
def is_prime(num):
"""判断num是否为质数?如果是,返回True, 否则返回False. 具体的代码自行补充完整"""
return True
def find_prime():
"""找出1~100之间所有的质数"""
return [num for num in range(1, 101) if is_prime(num)]
if __name__ == '__main__':
result1 = circle_example()
print(result1)
d = {
'user1': 'passwd1',
'user2': 'passwd2',
}
result2 = swap_key_value(d)
print(result2)二、生成器
1、定义和特点
(1)在python中,一边循环一边计算的机制,称为生成器(Generator)
(2)应用场景:
性能限制需要用到,比如读取一个10G的文件,如果一次性将10G的文件加载到内存处理的话 (read方法),内存肯定会溢出。但使用生成器把读写交叉处理进行,比如使用(readline和readlines) 就可以再循环读取的同时不断处理,这样就可以节省大量的内存空间。
(3)特点:
1> 解耦。 爬虫与数据存储解耦;
2> 减少内存占用.。随时生产, 即时消费, 不用堆积在内存当中;
3> 可不终止调用.。写上循环, 即可循环接收数据, 对在循环之前定义的变量, 可重复使用;
4> 生成器的循环, 在 yield 处中断, 没那么占 cpu
2、创建和访问
(1)创建:
方法一:列表生成式的改写。 []改成()
方法二:yield关键字
(2)访问:
方法一:通过for循环, 依次计算并生成每一个元素
方法二:通过 next() 函数一个一个获取
第一种方法: 列表生成式的改写。 []改成()
#列表生成式
nums = [num for num in range(1, 10001) if num % 8 == 0]
print(nums)#生成器创建
nums_gen = (num for num in range(1, 10001) if num % 8 == 0)
print(nums_gen) # <generator object <genexpr> at 0x7f8f2cb92350>
print(type(nums_gen)) # <class 'generator'>#查看一个对象是否可以for循环?
from collections.abc import Iterable
print("生成器是否为可迭代对象?", isinstance(nums_gen, Iterable))
#访问生成器对象元素的方法一: 通过for循环, 依次计算并生成每一个元素。
"""
for num in nums_gen:
if num > 50:
break
print(num)
"""#访问生成器对象元素的方法二: 如果要一个一个打印出来,可以通过next()函数获得生成器的下一个返回值。
print(next(nums_gen)) #执行一次next生成一个值
print(next(nums_gen))
print(next(nums_gen))
"""
Fib数列的案例理解生成器的创建
"""
def fib1(num):
"""递归实现Fib数列"""
if num in (1, 2):
return 1
return fib1(num - 1) + fib1(num - 2)#第二种方法: 函数中包含yield关键字
def fib2(num):
"""不使用递归方式实现Fib数列"""
count = 0
a = b = 1
while True:
if count < num:
count += 1
yield a
a, b = b, a + b
else:
break#如果函数中有yield关键字, 那么函数的返回值是生成器对象.
result = fib2(100)
print(result)#访问生成器对象元素的方法一: 通过for循环, 依次计算并生成每一个元素。
"""
for num in result:
if num > 50:
break
print(num)
"""#访问生成器对象元素的方法二: 如果要一个一个打印出来,可以通过next()函数获得生成器的下一个返回值。
print(next(result)) # 执行一次next生成一个值
print(next(result))
print(next(result))
"""
yield:
函数中包含yield关键字, 返回的是生成器对象
当第一次调用next(genObj), 才开始执行函数内容。
遇到yield关键字, 执行停止。
再次调用next方法时, 从上次停止的代码位置继续执行。
遇到yield关键字, 执行停止。
"""
#def return_example():
#理解return的工作原理
#1). 函数运行结果是什么?
#2). 是否会打印'step 1'? why?
#3). 是否会打印'step 2'? why?
#"""
#print('step 1')
##函数遇到return, 函数旧执行结束。 后面的代码不会执行的。
#return True
#print('step 2')
def yield_example():
"""
理解yield的工作原理
1). 函数的运行结果是什么?
函数中包含yield关键字, 返回的是生成器对象。
当第一次调用next(genObj), 才执行函数内容.
遇到yield关键字, 执行停止。
再次调用next方法时, 从上词停止的代码位置继续执行。
遇到yield关键字, 执行停止。
............
"""
for count in range(100):
yield 'step' + str(count + 1)
print("suucess")
if __name__ == '__main__':
#return_example()
#result是一个生成器, 因为调用的函数中包含yield关键字。
result = yield_example()
print(next(result))
print(next(result))
""""""
def grep(kw):
"""搜索关键字"""
while True:
response = ''
request = yield response
if kw in request:
print(request)
if __name__ == '__main__':
grep_gen = grep('python')
next(grep_gen)
#send方法可以给生成器传递数据, 并一直执行, 遇到yield停止。
grep_gen.send('I love python')
grep_gen.send('I love Java')"""
"""
def chatRobot():
response = ''
while True:
request = yield response
if '姓名' in request:
response = '姓名暂时保密'
elif '你好' in request:
response = '你好!Hello'
else:
response = '我不知道你在说些什么, 请换种说法'
if __name__ == '__main__':
#生成器对象
Robot = chatRobot()# 调用next方法
next(Robot)
while True:
request = input("Me: >> ")
if request == '再见':
print("欢迎下次聊天.....")
break
response = Robot.send(request)
print("Robot: >> ", response)"""
代码需要联网运行
"""
#requests库是python实现的最简单易用的HTTP库,多用于网络爬虫。
import requests
#json库是python中实现json的序列化与反序列化的模块。
import json
def robot_api(word):
#青云提供的聊天机器人API地址
url = 'http://api.qingyunke.com/api.php?key=free&appid=0&msg=%s' %(word)
try:
#访问URL, 获取网页响应的内容。
response_text = requests.get(url).text
#将json字符串转成字典, 并获取字典的‘content’key对应的value值
#eg: {'result': 0, 'content': '有做广告的嫌疑,清静点别打广告行么'}
return json.loads(response_text).get('content', "无响应")
except Exception as e:
#如果访问失败, 响应的内容为''
return ''
def chatRobot():
response = ''
while True:
#yield response: response就是生成器执行next方法或者send方法的返回值。
#request = yield
request = yield response
if '姓名' in request:
response = '姓名暂时保密'
elif '你好' in request:
response = '你好!Hello'
else:
response = robot_api(request)
if __name__ == '__main__':
#生成器对象
Robot = chatRobot()
#调用next方法
next(Robot)
while True:
request = input("Me: >> ")
if request == '再见':
print("欢迎下次聊天.....")
break
response = Robot.send(request)
print("Robot: >> ", response)
"""三、生成器、迭代器、可迭代对象总结
生成式:快速生成列表,集合,字典
生成器(generator):一边循环一边计算
迭代器(iterator):可以调用next()方法访问元素
可迭代对象:可以通过for循环访问
生成器都是迭代器,都是可迭代对象
可迭代对象不一定是迭代器,例如:str,list,tuple,set,dict
怎么将可迭代对象转换成迭代器:通过iter()关键字
生成器: generator, 一边循环一边计算的工具。
迭代器: iterator, 可以调用next方法访问元素的对象.
可迭代对象: Iterable, 可以实现for循环的
生成器都是迭代器么? Yes, 生成器内部实现了迭代器的协议。
生成器都是可迭代对象吗? Yes
可迭代对象都是迭代器吗? Not Always, 比如: str,list,tuple,set,dict.
如何将可迭代对象转换成迭代器? iter()内置函数
""""""
四、闭包
1、定义
闭包就是指有权访问另一个函数作用域中的变量的函数。
常见形式:
(1)函数嵌套
(2)内部函数使用外部函数的变量
(3)外部函数的返回值是内部函数的名称
应用场景:装饰器
优点:提高代码可复用性
line_conf:是外部函数
line: 是内部函数
line是否为闭包? Yes, line调用了line_conf的局部变量a和b
"""
import matplotlib.pyplot as plt
def line_conf(a, b): # a=2, b=3
"""y = ax + b """
def line(x):
return a * x + b
return line
#line1是一个函数名
line1 = line_conf(2, 3) # 调用函数, a=2, b=3
line2 = line_conf(3, 3) # 调用函数, a=3, b=3
line3 = line_conf(4, 3) # 调用函数, a=4, b=3
#x = [1, 3, 5, 7 .....99]
x = list(range(1, 100, 2))
y1 = [line1(item) for item in x]
y2 = [line2(item) for item in x]
y3 = [line3(item) for item in x]
#plot:折线图
#plt.plot(x, y1, label='y=2x+3')
#plt.plot(x, y2, label='y=3x+3')
#plt.plot(x, y3, label='y=4x+3')
#scatter: 散点图
plt.scatter(x, y1, label='y=2x+3')
plt.scatter(x, y2, label='y=3x+3')
plt.scatter(x, y3, label='y=4x+3')
#显示绘制的图形
plt.title('line display') # 添加标题
plt.legend() # 添加图例
plt.show()五、装饰器
1、定义
(1)器指的是工具,而程序中的函数就是具备某一功能的工具,所以装饰器指的是为被装饰器对象添加额外功能的工具/函数。
(2)为什么要使用装饰器
如果我们已经上线了一个项目,我们需要修改某一个方法,但是我们不想修改方法的使用方法,这个时 候可以使用装饰器。因为软件的维护应该遵循开放封闭原则,即软件一旦上线运行后,软件的维护对修 改源代码是封闭的,对扩展功能指的是开放的。
装饰器的实现必须遵循两大原则:
1> 封闭: 对已经实现的功能代码块封闭。 不修改被装饰对象的源代码
2> 开放: 对扩展开发 装饰器其实就是在遵循以上两个原则的前提下为被装饰对象添加新功能。
(3)如何实现装饰器:
装饰器本质上是一个函数,该函数用来处理其他函数,它可以让其他函数在不需要修改代码的前提下增加额外的功能,装饰器的返回值也是一个函数对象。
#logging:专门做日志记录或者处理的模块。
import logging
#日志的基本配置
#官方符网站基本配置及使用: https://docs.python.org/zh-cn/3/howto/logging.html#logging-basic-tutorial
logging.basicConfig(
level=logging.DEBUG, # 控制台打印的日志级别
filename='message.log', # 日志文件位置
filemode='a', # 写入文件的模式,a是追加模式,默认是追加模式
#日志格式
format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'
)
#logging.debug('Network start Ok')
#logging.warning('Network start Failed')
#1). 定义装饰器
from functools import wraps
def logger(func):
"""插入日志的装饰器"""
#wraps装饰器, 用来保留func函数原有的函数名和帮抓文档。
@wraps(func)
def wrapper(*args, **kwargs): # args, kwargs是形参, args是元组, kwargs是字典.
"""闭包函数"""
logging.debug("函数%s开始执行" % (func.__name__))
result = func(*args, **kwargs) # args, kwargs是实参, *args, **kwargs解包
logging.debug("函数%s执行结束" % (func.__name__))
return result
return wrapper
#2). 如何使用装饰器?
#1). @logger语法糖, login = logger(login), python解释器遇到语法糖就直接执行
#2). login函数目前指向logger(login)函数的返回值wrapper, login=wrapper
@logger
def login(username, password):
"""用户登录"""
if username == 'root' and password == 'redhat':
print('LOGIN OK')
logging.debug('%s LOGIN OK' % (username))
else:
print('LOGIN FAILED')
logging.error('%s LOGIN FAILED' % (username))
#实质上执行的是装饰器里面的wrapper函数
login('root', 'westos')
#print(login.__name__)
#print(login.__doc__)2019-12-21 17:15:53,226 - /home/kiosk/201911python/day08_code/16_装饰器.py[line:32] - DEBUG: 函数login开始执行
2019-12-21 17:15:53,227 - /home/kiosk/201911python/day08_code/16_装饰器.py[line:46] - ERROR: root LOGIN FAILED
2019-12-21 17:15:53,227 - /home/kiosk/201911python/day08_code/16_装饰器.py[line:34] - DEBUG: 函数login执行结束
2019-12-21 17:17:00,105 - /home/kiosk/201911python/day08_code/16_装饰
"""
import os
#文件名称的匹配,并且匹配的模式使用的unix shell风格
import fnmatch
def locate(pattern, root=os.curdir):
"""生产者: 生产符合条件的文件名"""
#os.walk返回三个值: 查询根目录, 子目录,目录文件
for path, dirs, files in os.walk(os.path.abspath(root)):
# fnmatch.filter实现列表特殊字符的过滤或筛选,返回符合匹配模式的字符列表
for filename in fnmatch.filter(files, pattern):
# 拼接文件的绝对路径
yield os.path.join(path, filename)
def rename():
"""消费者: 文件重命名"""
while True:
filename = yield
dirname, basename = os.path.split(filename)
rename = os.path.join(dirname, '[西部开源]_' + basename)
os.rename(filename, rename)
if __name__ == '__main__':
fname = locate('*.py')
rename_gen = rename()
next(rename_gen)
for name in fname:
rename_gen.send(name)装饰器的应用场景
装饰器经常用于有切面需求的场景,比如:
插入日志、性能测试、事务处理、缓存、 权限校验等应用场景。
from functools import wraps
import time
def timeit(func): # 2 func=download_music
"""打印被装饰函数运行总时间的装饰器"""
#@wraps保留被装饰函数的函数名和帮助文档, 否则是wrapper的信息.
@wraps(func)
def wrapper(*args, **kwargs): # 5 args=('Music', ), kwargs={}
start_time = time.time()
result = func(*args, **kwargs) # 6 func('Music')=download_music('Music')
end_time = time.time()
print("%s函数运行总时间为%fs" %(func.__name__, end_time-start_time))
return result # 7
return wrapper # 3
@timeit # 1 @timeit实质上执行的内容: download_music = timeit(download_music) = wrapper
def download_music(name): # 7
time.sleep(0.4)
print('[Download]: ', name)
return True
#调用download_music函数时实质上调用的是wrapper函数。
download_music('Music') # 4
"""import json
from functools import wraps
import string
def json_result(func): # 2
"""被装饰函数的返回值序列化成json格式字符串"""
#保留被装饰函数的函数名和帮助文档。
@wraps(func)
def wrapper(*args, **kwargs): # 5
result = func(*args, **kwargs) # 6
return json.dumps(result) # 8
return wrapper # 3
@json_result # 1
def get_users(): # 7
return {'user' + item: 'passwd' + item for item in string.digits}
result = get_users() # 4
print(result) # 9
"""实现斐波那契数列,由于重复性占用很大的空间且计算缓慢,所以可以利用缓存来节省时间
from functools import lru_cache
from functools import wraps
import time
def timeit(func): # 2 func=download_music
"""打印被装饰函数运行总时间的装饰器"""
#@wraps保留被装饰函数的函数名和帮助文档, 否则是wrapper的信息.
@wraps(func)
def wrapper(*args, **kwargs): # 5 args=('Music', ), kwargs={}
start_time = time.time()
result = func(*args, **kwargs) # 6 func('Music')=download_music('Music')
end_time = time.time()
print("%s函数运行总时间为%fs" % (func.__name__, end_time - start_time))
return result # 7
return wrapper # 3
def fib_cache(func):
"""打印被装饰函数运行总时间的装饰器"""
caches = {1: 1, 2: 1, 3: 2, 4: 4}
#@wraps保留被装饰函数的函数名和帮助文档, 否则是wrapper的信息.
@wraps(func)
def wrapper(num):
# 如果缓存中能找到第num个Fib数列的值, 直接返回。
if num in caches:
return caches.get(num)
#如果缓存中不能找到第num个Fib数列的值,
#1). 先执行函数func(num)计算结果。
#2). 然后将将计算的信息存储在缓存中。并返回计算结果
else:
result = func(num)
caches[num] = result
return result
return wrapper
#@fib_cache
@lru_cache(maxsize=10000)
def fib1(num):
"""计算第num个Fib数列"""
if num in (1, 2):
return 1
else:
return fib1(num - 1) + fib1(num - 2)
def fib2(num):
"""计算第num个Fib数列"""
if num in (1, 2):
return 1
else:
return fib2(num - 1) + fib2(num - 2)
@timeit # use_cache = timeit(use_cache)
def use_cache():
result = fib1(20)
print(result)
@timeit
def no_cache():
result = fib2(20)
print(result)
if __name__ == '__main__':
use_cache()
no_cache()
"""一般情况下,在函数中可以使用一个装饰器,但是有时也会有两个或两个以上的装饰器。 多个装饰器装饰的顺序是自下而上(就近原则),而调用的顺序是自上而下(顺序执行)
from functools import wraps
#系统中的用户信息;
db = {
'root': {
'name': 'root',
'passwd': 'westos',
'is_super': 0 # 0-不是 1-是
},
'admin': {
'name': 'admin',
'passwd': 'westos',
'is_super': 1 # 0-不是 1-是
}
}
#存储当前登录用户的信息;
login_user_session = {}
def is_login(func):
"""判断用户是否登录的装饰器"""
#@wraps保留被装饰函数的函数名和帮助文档, 否则是wrapper的信息.
@wraps(func)
def wrapper1(*args, **kwargs):
if login_user_session:
result = func(*args, **kwargs)
return result
else:
print("未登录, 请先登录.......")
print("跳转登录".center(50, '*'))
user = input("User: ")
passwd = input('Password: ')
if user in db:
if db[user]['passwd'] == passwd:
login_user_session['username'] = user
print('登录成功')
#***** 用户登录成功, 执行buy的操作;
result = func(*args, **kwargs)
return result
else:
print("密码错误")
else:
print("用户不存在")
return wrapper1
def is_permission(func):
"""判断用户是否有权限的装饰器"""
#@wraps保留被装饰函数的函数名和帮助文档, 否则是wrapper的信息.
@wraps(func)
def wrapper2(*args, **kwargs):
print("判断是否有权限......")
current_user = login_user_session.get('username')
permissson = db[current_user]['is_super']
if permissson == 1:
result = func(*args, **kwargs)
return result
else:
print("用户%s没有权限" % (current_user))
return wrapper2
#多个装饰器装饰的顺序是自下而上(就近原则),而调用/执行的顺序是自上而下(顺序执行)。
"""
被装饰的过程:
1). @is_permission: buy = is_permission(buy) ===> buy=wrapper2
2). @is_login: buy = is_login(buy) ===> buy = is_login(wrapper2) ===> buy=wrapper1
"""
@is_login
@is_permission
def buy():
print("购买商品........")
"""
判断用户是否登录..........
判断用户是否有权限..........
购买商品........
调用的过程:
1). buy() ===> wrapper1() print("判断用户是否登录..........")
2). wrapper2() print("判断用户是否有权限..........")
3). buy() print("购买商品........")
"""
buy()
"""无参装饰器只套了两层,有参装饰器: 套三层的装饰器
from functools import wraps
def auth(type):
print("认证类型为: ", type)
def desc(func):
@wraps(func)
def wrapper(*args, **kwargs):
if type == 'local':
user = input("User:")
passwd = input("Passwd:")
if user == 'root' and passwd == 'westos':
result = func(*args, **kwargs)
return result
else:
print("用户名/密码错误")
else:
print("暂不支持远程用户登录")
return wrapper
return desc
结论: @后面跟的是装饰器函数的名称, 如果不是名称, 先执行,再和@结合。
1). @auth(type='local')
2). desc = auth(type='local')
3). @desc
4). login = desc(login)
4). login = wrapper
"""
@auth(type='remote')
def home():
print('网站主页')
home()内置高阶函数
把函数作为参数传入,或者作为返回值返回
1、map()函数
map(function, *iterable)
传入函数和可迭代对象
根据提供的函数对指定序列做映射。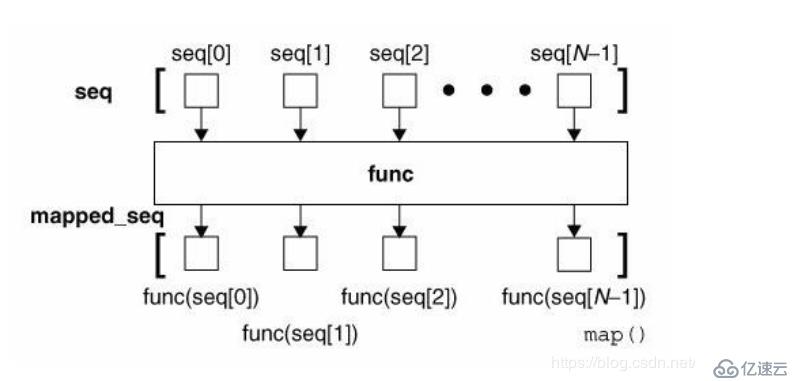
当序列多于一个时,map可以并行(注意是并行)地对每个序列执行如下图所示的过程: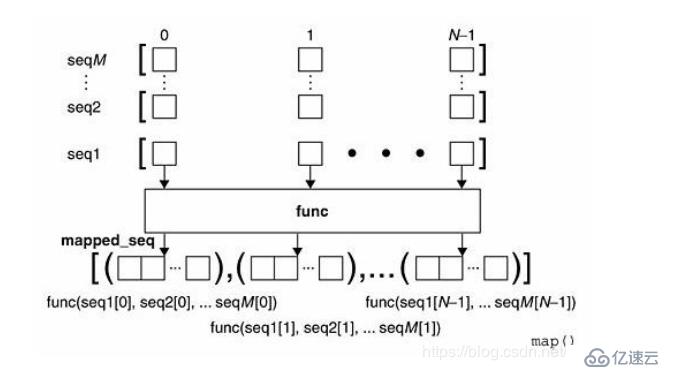
#1+1*3
#add(1,cheng(1, 3))
#map() 会根据提供的函数对指定序列做映射。
#1). map的传递函数名可以是内置函数
map_object = map(int, ['1', '2', '3'])
for item in map_object:
print(item, type(item))
#2). map的传递函数名可以是匿名函数
iterator_object = (int(item) for item in ['1', '2', '3'])
for item in iterator_object:
print(item, type(item))
map_object = map(lambda x: x ** 2, [1, 2, 3, 4])
print(list(map_object)) # [1, 4, 9, 16]
def data_process(x):
return x + 4
#3). map的传递函数名可以是非匿名函数
map_object = map(data_process, [1, 2, 3, 4])
print(list(map_object)) # [1, 4, 9, 16]#4). map的传递的可迭代对象可以是多个
x, y = 1, 1 2
x, y = 2, 2 6
x, y = 3, 3 12
"""
map_object = map(lambda x, y: x ** 2 + y, [1, 2, 3], [1, 2, 3])
print(list(map_object))
reduce() 函数
reduce(function, sequence[, initial]) -> value
对参数序列中元素进行累积
在python2中,reduce是内置高阶函数
在python3中,reduce函数需要导入:
from functools import reduce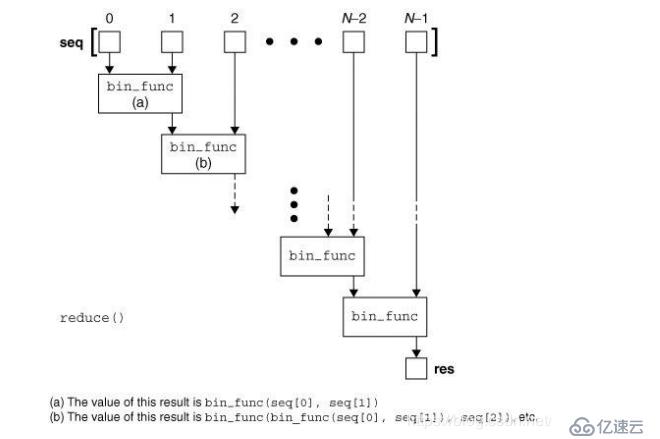
#reduce() 函数会对参数序列中元素进行累积。
#py2中, reduce是内置高阶函数;
#py3中, reduce函数需要导入;
from functools import reduce
nums_add = reduce(lambda x, y: x + y, list(range(1, 101)))
print(nums_add)
#需求: 通过reduce函数时先阶乘
N = 5
result = reduce(lambda x, y: x * y, list(range(1, N + 1))) # 1, 2, 3, 4, 5
print(result)filter() 函数
filter(function or None, iterable)
用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。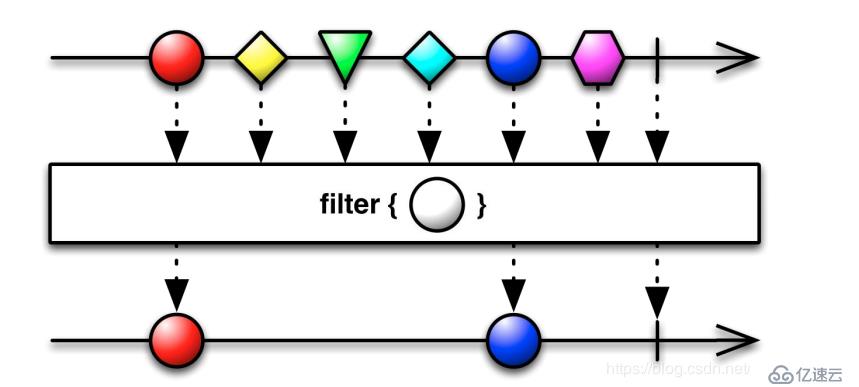
#filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
result = filter(lambda x: x % 3 == 0, list(range(1, 11)))
print(list(result))
result = [item for item in range(1, 11) if item % 3 == 0]
print(result)
def is_prime(x):
"""判断x是否为质数"""
pass
result = filter(is_prime, list(range(2, 101)))
print(list(result))"""sorted() 函数
sorted(iterable, key=None, reverse=False)
key: 主要是用来进行比较的元素,只有一个参数
reverse: 排序规则,True 降序 ,False 升序(默认)。
对所有可迭代的对象进行排序操作。返回重新排序的列表。
sort() 和 sorted() 的区别:
(1)排序对象不同: sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
(2)返回值不同:
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值
内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
import random
def is_odd(x):
"""判断是否为偶数"""
return x % 2 == 0
#排序需求: 偶数排前面, 奇数排后面
nums = list(range(10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
random.shuffle(nums)
print("排序前: ", nums)
nums.sort(key=lambda x: 0 if is_odd(x) else 1)
print("排序后: ", nums)
#sorted可以对所有可迭代的对象进行排序操作。
result = sorted({2, 3, 4, 5, 1})
print(list(result))"""免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





