堆结构简述
了解过数据结构的人,应该对堆结构不陌生,堆的底层是使用数组来实现的,但却保持了二叉树的特性。堆分为两种,最大堆和最小堆,以最大堆为例,最大堆保持了根结点大于两个左右两个孩子,同时所有子树一次类推。由于堆底层是数组结构,这里从跟结点开始,按照层序依次走到最后一个结点,结点下标分贝为0~N-1。结构如下图:
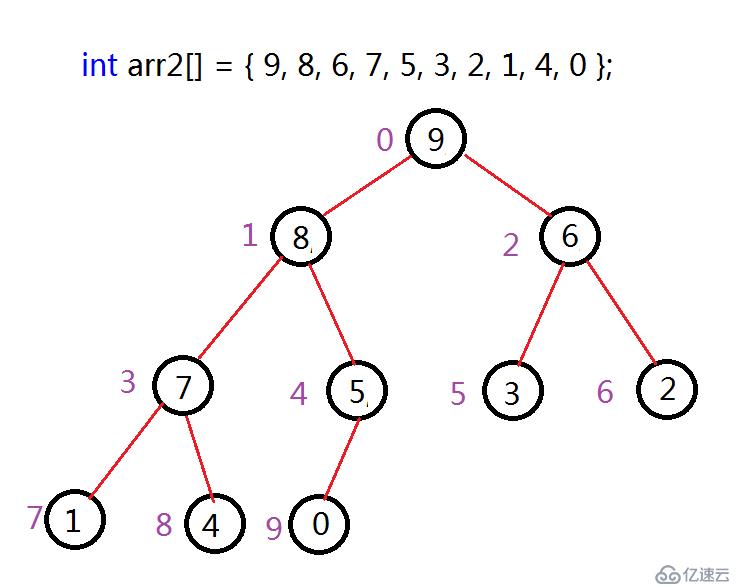
上图中,紫色表示的是该元素在数组中的下标,可以看到,每个结点的值总是大于它的左右孩子,这里并没有规定左右孩子的大小关系,也没有规定不是同一棵树之间结点的大小关系。这就是最大堆。同时这里可以注意到,如果是大堆,根节点一定是树中最大的结点,同样,如果是小堆,根节点一定是树中最小的结点。
堆结构在排序领域,占据着一定的低位,但是STL中并没有直接给出堆结构,而是把堆的相关算法,写在了 algorithm 里面。在这里我不会过多的去模拟实现一个堆,今天要说的是关于STL中给出的堆算法如何使用。
algorithm 中的堆算法
在STL中,关于堆,给出了一下几种算法。
★make_heap
★push_heap
★pop_heap
★sort_heap
这里,首先给出一个利用STL中堆算法的实例
#include <algorithm>
#include <vector>
void test()
{
int arr[] = {1,2,3,4,5,6,7};
vector<int> vec(arr, arr+7); // 左开右闭类型
make_heap(vec.begin(), vec.end()); // 默认建大堆
pop_heap(v1.begin(), v1.end());
v1.pop_back();
sort_heap(vec.begin(), vec.end()); // 堆排序
for(size_t i = 0; i < vec.size(); i++)
cout<<vec[i]<<" ";
cout<<endl;
}上面代码,首先用一个数组构建了一个向量,之后对向量vec建堆,pop出调整之后的向量中第一个元素,并进行调整,然后进行堆排序,最后将结果打印出来,打印结果如下:

看完了heap算法的基本使用,现在,我们了解一下,STL中是如何提供这些算法接口的。
1、make_heap
| default (1) | template <class RandomAccessIterator> void make_heap (RandomAccessIterator first, RandomAccessIterator last); |
|---|---|
| custom (2) | template <class RandomAccessIterator, class Compare> void make_heap (RandomAccessIterator first, RandomAccessIterator last, Compare comp ); |
前面提到过,堆分为大堆和小堆,我们建立堆的时候就需要确定,但刚刚例子中,我们并没有去指定大小堆。STL中规定,没有指定的话,默认大堆结构。从上面关于make_heap的两套接口可以看到,第一种是默认的,没有提供指定大小堆的接口,第二种这里有实现。我们可通过仿函数的结构,实现这里的传参。
对刚刚给出的例子,我们现在可以解释另外一个问题,为什么我们要进行堆排序,首先要构建vector呢?因为堆的底层实现就是通过数组的形式,而vector是堆数组的高级封装,这些库中实现好的容器给出了很多实用的接口和迭代器,使用起来的确可以方便不少。make_heap给出的接口中,前两个是任意类型的迭代器(当然,这里也可以直接传递数组的指针),不论是make_heap还是其他三个函数,这里的迭代器区间总是左闭右开的,这是个需要注意的地方。
接下来我们来介绍仿函数这里的实现。还是上面的例子,如何让上面剪子一个最小堆呢?
//仿函数结构:
struct Compare
{
bool operator()(int num1, int num2)
{
return num1 > num2;
}
};
// 建堆时,参数传递改为
make_heap(vec.begin(), vec.end() , Compare()); // 建小堆
注意,上面我写的是num1 > num2,这样建出来顶点是小堆。关于make_heap就说到这里。
2、push_heap 与 pop_heap
push表示的是向vector中插入一个元素,但这里它并不是直接插入元素,准确的说,它的功能只是做调整,在push_heap之前,首先需要调用vec.push_back(x),向vector尾部插入一个元素,然后在调用push_heap函数进行调整,使得整个树重新满足堆结构。
pop_heap与push_heap类似,同样没有直接改变vector中元素个数的能力。对于堆而言,pop要做的是将vector的第一个元素扔出去,为了不直接破坏树的结构,这里先调用pop_heap函数,将堆中的最大值或最小值放到vector的尾部,同时进行一次调整,使得堆结构依然成立,然后调用vec.pop+back()函数,将最后一个元素从vector中剔除。
这就是插入和删除的整个过程。
3、sort_heap
顾名思义,sort_heap就是进行堆排序的意思,对堆结构进行排序,得到的结果就是vector中的元素变得有序。这里,构建大堆,排序结果是升序的,构建小堆,得到的排序结果是降序的。
上面就是关于堆排序的基本算法,关于C++11新引入的两个函数,这里不做讨论。
关于STL中的堆结构,这里有几点还是需要注意的:
1、因为堆结构,是建立在vector上的结构,所以如果要进行堆排序,整个过程中至少一次建堆(make_heap)的过程。
2、当建堆完成之后,如果再向vector中插入元素,需要调用 push_heap(v1.begin(), v1.end()) 进行一次向上调整;如果从vector中Pop出一个元素,需要调用 pop_heap(v1.begin(), v1.end()) 进行一次向下调整。
如果没有调整,当调用 sort_heap(v1.begin(), v1.end()) 函数的过程中,会出现由于堆不合法引起的断言错误。
3、不可以让vector多次尾插,之后再多次向上调整,会造成堆混乱,排序时也会出现断言错误。当然,多次插入或删除之后,可以再次进行重新建堆,只不过消耗的时间代价会比较大。
堆结构实际应用
接下来,看一道面试题:
CVTE:统计公司员工最喜欢吃的前K种水果
有过上面的基础,我这里直接给出demo
#include <algorithm>
#include <map>
#include <string>
#include <vector>
struct Min
{
bool operator()(pair<string, int> p1, pair<string, int> p2)
{
return p1.second > p2.second;
}
};
void HeapSort()
{
vector<string> v1 = { "苹果", "香蕉", "苹果"
, "苹果", "苹果", "香蕉"
, "苹果", "猕猴桃", "草莓" };
map<string, int> fruit;
//用map统计次数
for (size_t i = 0; i < v1.size(); i++)
{
fruit[v1[i]]++;
}
// 用heap排序
vector<pair<string, int>> vec;
map<string, int>::iterator it = fruit.begin();
//while (it != fruit.end())
//{
// vec.push_back(pair<string, int>(it->first, it->second));
// it++;
//}
vec.insert(vec.begin(), fruit.begin(), fruit.end());
make_heap(vec.begin(), vec.end(), Min());
sort_heap(vec.begin(), vec.end(), Min());
int K = 3;
for (size_t i = 0; (i < K) && (i < vec.size()); i++)
{
cout << vec[i].first <<"--"<<vec[i].second<< endl;
}
}
int main()
{
HeapSort();
system("pause");
return 0;
} 堆排序是数据结构中一块很重要的内容,如果是在实际开发中,更加推荐的是熟悉STL中给出的算法,正如上文讲到的内容。如果是对于初学者,这里还是推荐对堆结构和算法的底层实现有一个更加深刻的认识,对于堆的调整算法,不可否认,是数据结构中较为重要的一部分。下一次,会对堆结构进行模拟实现,更加深入地了解底层结构。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





