这期内容当中小编将会给大家带来有关如何进行JDK源码分析LinkedHashMap相关,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
LinkedHashMap实质是HashMap+LinkedList,提供了顺序访问的功能。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {}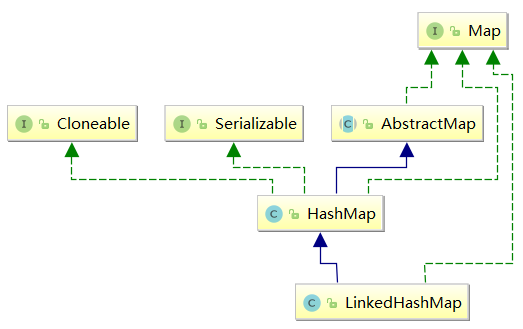
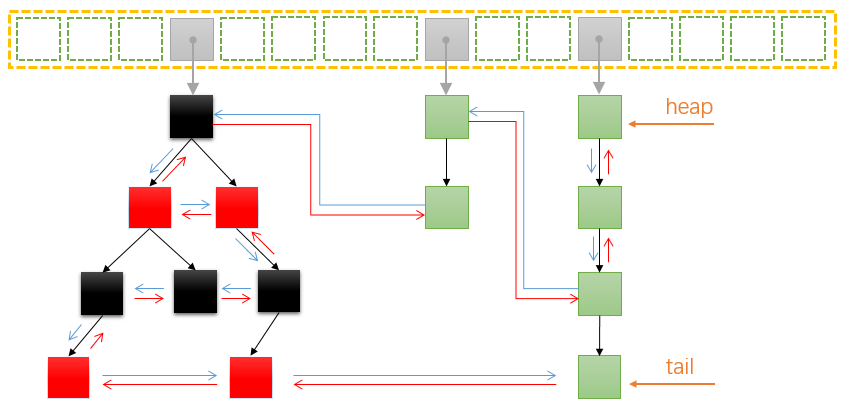
从上述定义中也能看到LinkedHashMap其实就是继承了HashMap,并加了双向链表记录顺序,代码和结构本身不难,但是其中结构的组织,代码复用这些地方十分值得我们学习;具体结构如图所示:
public LinkedHashMap(int initialCapacity, float loadFactor) {}public LinkedHashMap(int initialCapacity) {}public LinkedHashMap() {}public LinkedHashMap(Map<? extends K, ? extends V> m) {}public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {}/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
* @serial
*/
final boolean accessOrder;可以看到LinkedHashMap的5个构造函数和HashMap的作用基本是一样的,都是初始化initialCapacity和loadFactor,但是多了一个accessOrder,这也是LinkedHashMap最重要的一个成员变量了;
当accessOrder为true的时候,表示LinkedHashMap中记录的是访问顺序,也是就没放get一个元素的时候,这个元素就会被移到链表的尾部;
当accessOrder为false的时候,表示LinkedHashMap中记录的是插入顺序;

扎眼一看可能会觉得HashMap体系的节点继承关系比较混乱;一所以这样设计因为
LinkedHashMap继承至HashMap,其中的节点同样有普通节点和树节点两种;并且树节点很少使用;
现在的设计中,树节点是可以完全复用的,但是HashMap的树节点,会浪费双向链表的能力;
如果不这样设计,则至少需要两条继承关系,并且需要抽出双向链表的能力,整个继承体系以及方法的复用会变得非常复杂,不利于扩展;
上面我们已经讲了LinkedHashMap就是HashMap+链表,所以我们只需要在结构有可能改变的地方加上链表的修改就可以了,结构可能改变的地方只要有put/get/replace,这里需要注意扩容的时候虽然结构改变了,但是节点的顺序仍然保持不变,所以扩容可以完全复用;
未找到key时,直接在最后添加一个节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p); return p;
}TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p); return p;
}private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p; if (last == null)
head = p; else {
p.before = last;
last.after = p;
}
}上面代码很简单,但是很清晰的将添加节点到最后的逻辑抽离的出来;
找到key,则替换value,这部分需要联系 HashMap 相关 中的put方法部分;
// HashMap.putVal...// 如果找到keyif (e != null) { // existing mapping for key
V oldValue = e.value; if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); return oldValue;
}// 如果没有找到key++modCount;if (++size > threshold)
resize();
afterNodeInsertion(evict);return null;
...在之前的HashMap源码分析当中可以看到有几个空的方法
void afterNodeAccess(Node<K,V> p) { }void afterNodeInsertion(boolean evict) { }void afterNodeRemoval(Node<K,V> p) { }这三个就是用来调整链表位置的事件方法,可以看到HashMap.putVal中就使用了两个,
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null; if (b == null)
head = a; else
b.after = a; if (a != null)
a.before = b; else
last = b; if (last == null)
head = p; else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}afterNodeAccess可以算是LinkedHashMap比较核心的方法了,当访问了一个节点的时候,如果accessOrder = true则将节点放到最后,如果accessOrder = false则不变;
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false;
}afterNodeInsertion方法是插入节点后是否需要移除最老的节点,这个方法和维护链表无关,但是对于LinkedHashMap的用途有很大作用,后天会举例说明;
public V get(Object key) {
Node<K,V> e; if ((e = getNode(hash(key), key)) == null) return null; if (accessOrder)
afterNodeAccess(e); return e.value;
}public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e; if ((e = getNode(hash(key), key)) == null) return defaultValue; if (accessOrder)
afterNodeAccess(e); return e.value;
}get方法主要也是通过afterNodeAccess来维护链表位置关系;
以上就是LinkedHashMap链表位置关系调整的主要方法了;
public boolean containsValue(Object value) { for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value; if (v == value || (value != null && value.equals(v))) return true;
} return false;
}可以看到LinkedHashMap还重写了containsValue,在HashMap中寻找value的时候,需要遍历所有节点,他是遍历每个哈希桶,在依次遍历桶中的链表;而在LinkedHashMap里面要遍历所有节点的时候,就可以直接通过双向链表进行遍历了;
public class Cache<K, V> { private static final float DEFAULT_LOAD_FACTOR = 0.75f; private final int MAX_CAPACITY; private LinkedHashMap<K, V> map; public Cache(int capacity, boolean accessOrder) {
capacity = (int) Math.ceil((MAX_CAPACITY = capacity) / DEFAULT_LOAD_FACTOR) + 1;
map = new LinkedHashMap(capacity, DEFAULT_LOAD_FACTOR, accessOrder) { @Override
protected boolean removeEldestEntry(Map.Entry eldest) { return size() > MAX_CAPACITY;
}
};
} public synchronized void put(K key, V value) {
map.put(key, value);
} public synchronized V get(K key) { return map.get(key);
} @Override
public String toString() {
StringBuilder sb = new StringBuilder(); for (Map.Entry entry : map.entrySet()) {
sb.append(String.format("%s:%s ", entry.getKey(), entry.getValue()));
} return sb.toString();
}
}以上是就是一个LinkedHashMap的简单应用,
当accessOrder = true时,就是LRUCache,
当accessOrder = false时,就是FIFOCache;
// LRUCacheCache<String, String> cache = new Cache<>(3, true);
cache.put("a", "1");
cache.put("b", "2");
cache.put("c", "3");
cache.put("d", "4");
cache.get("c");
System.out.println(cache);// 打印:b:2 d:4 c:3
// FIFOCacheCache<String, String> cache = new Cache<>(3, false);
cache.put("a", "1");
cache.put("b", "2");
cache.put("c", "3");
cache.put("d", "4");
cache.get("c");
System.out.println(cache);// 打印:b:2 c:3 d:4
总体而言LinkedHashMap的代码比较简单,但是我觉得里面代码的组织,逻辑的提取等方面特别值得借鉴。
上述就是小编为大家分享的如何进行JDK源码分析LinkedHashMap相关了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



