性能工具之所以使用扩展的BPF,部分原因在于它的可编程性。BPF程序可以执行自定义等待时间计算和统计摘要。仅这些功能就可以构成一个有趣的工具,并且还有许多其他具有这些功能的跟踪工具。使BPF与众不同的是,它还高效且生产安全,并且内置于Linux内核中。使用BPF,您可以在生产环境中运行这些工具,而无需添加任何新的内核组件。
让我们看一些输出和一个图表,以了解性能工具如何使用BPF。该示例来自我发布的早期BPF工具bitehist,该工具以直方图的形式显示了磁盘I/O的大小:
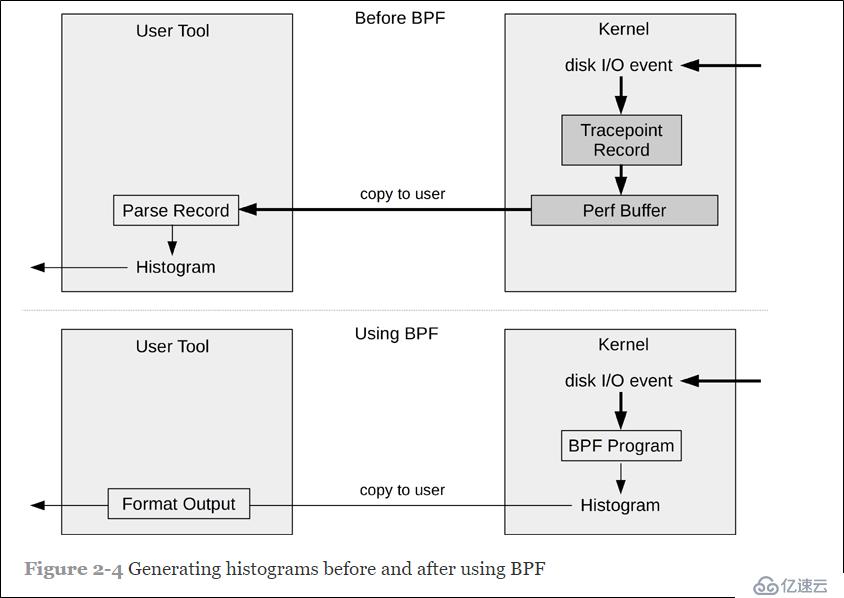
关键的变化是直方图可以在内核上下文中生成,这大大减少了复制到用户空间的数据量。这种效率的提高是如此之大,以至于它可以允许工具在生产中运行,否则这些工具将太昂贵。详细地:
在BPF之前,生成此直方图摘要的完整步骤为:
1. 在内核中:为磁盘I / O事件启用检测。
2. 在内核中,对于每个事件:将一条记录写入perf缓冲区。如果使用跟踪点(首选),则记录包含有关磁盘I / O的元数据的几个字段。
3. 在用户空间中:定期将所有事件的缓冲区复制到用户空间。
4. 在用户空间中:遍历每个事件,为字节字段解析事件元数据。其他字段将被忽略。
5. 在用户空间中:生成字节字段的直方图摘要。
注意:这些是可用的最佳步骤,但它们并没有显示唯一的方法。您可以安装树外跟踪器(例如SystemTap),但是根据您的内核和发行版,这可能会很艰难。您也可以修改内核代码,或开发自定义kprobe模块,但是这两种方法都涉及挑战,并带来风险。我开发了自己的解决方法,称为“ hacktogram”,其中涉及为直方图的每一行创建多个带范围过滤器的perf(1)统计计数器[16]。那太差了。
步骤2到步骤4对于高I / O系统具有高性能开销。想象一下,每秒传输10,000个磁盘I / O跟踪记录到用户空间程序以进行分析和汇总。
使用BPF,bitesize程序的步骤为:
1. 在内核中:启用对磁盘I / O事件的检测,并附加一个由bitesize定义的自定义BPF程序。
2. 在内核中,对于每个事件:运行BPF程序。它仅获取字节字段,并将其保存到自定义BPF映射直方图中。
3. 在用户空间中:一次读取BPF地图直方图并打印出来。
此方法避免了将事件复制到用户空间并对其进行重新处理的开销。它还避免了复制未使用的元数据字段。复制到用户空间的唯一数据显示在上一个输出中:“ count”列,它是数字数组。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



