这篇文章给大家分享的是有关python如何批量统计xml中各类目标的数量的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
代码如下:
# -*- coding:utf-8 -*-
import os
import xml.etree.ElementTree as ET
import numpy as np
np.set_printoptions(suppress=True, threshold=np.nan)
import matplotlib
from PIL import Image
def parse_obj(xml_path, filename):
tree=ET.parse(xml_path+filename)
objects=[]
for obj in tree.findall('object'):
obj_struct={}
obj_struct['name']=obj.find('name').text
objects.append(obj_struct)
return objects
def read_image(image_path, filename):
im=Image.open(image_path+filename)
W=im.size[0]
H=im.size[1]
area=W*H
im_info=[W,H,area]
return im_info
if __name__ == '__main__':
xml_path='C:/Users/nansbas/Desktop/hebin/03/'
filenamess=os.listdir(xml_path)
filenames=[]
for name in filenamess:
name=name.replace('.xml','')
filenames.append(name)
recs={}
obs_shape={}
classnames=[]
num_objs={}
obj_avg={}
for i,name in enumerate(filenames):
recs[name]=parse_obj(xml_path, name+ '.xml' )
for name in filenames:
for object in recs[name]:
if object['name'] not in num_objs.keys():
num_objs[object['name']]=1
else:
num_objs[object['name']]+=1
if object['name'] not in classnames:
classnames.append(object['name'])
for name in classnames:
print('{}:{}个'.format(name,num_objs[name]))
print('信息统计算完毕。')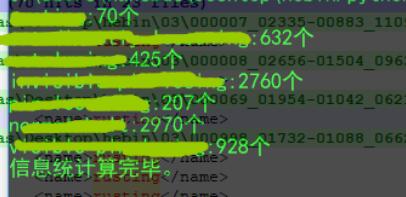
补充知识:Python对目标检测数据集xml文件操作(统计目标种类、数量、面积、比例等&修改目标名字)
1. 根据xml文件统计目标种类以及数量
# -*- coding:utf-8 -*-
#根据xml文件统计目标种类以及数量
import os
import xml.etree.ElementTree as ET
import numpy as np
np.set_printoptions(suppress=True, threshold=np.nan)
import matplotlib
from PIL import Image
def parse_obj(xml_path, filename):
tree=ET.parse(xml_path+filename)
objects=[]
for obj in tree.findall('object'):
obj_struct={}
obj_struct['name']=obj.find('name').text
objects.append(obj_struct)
return objects
def read_image(image_path, filename):
im=Image.open(image_path+filename)
W=im.size[0]
H=im.size[1]
area=W*H
im_info=[W,H,area]
return im_info
if __name__ == '__main__':
xml_path='/home/dlut/网络/make_database/数据集——合集/VOCdevkit/VOC2018/Annotations/'
filenamess=os.listdir(xml_path)
filenames=[]
for name in filenamess:
name=name.replace('.xml','')
filenames.append(name)
recs={}
obs_shape={}
classnames=[]
num_objs={}
obj_avg={}
for i,name in enumerate(filenames):
recs[name]=parse_obj(xml_path, name+ '.xml' )
for name in filenames:
for object in recs[name]:
if object['name'] not in num_objs.keys():
num_objs[object['name']]=1
else:
num_objs[object['name']]+=1
if object['name'] not in classnames:
classnames.append(object['name'])
for name in classnames:
print('{}:{}个'.format(name,num_objs[name]))
print('信息统计算完毕。')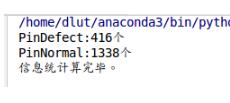
2.根据xml文件统计目标的平均长度、宽度、面积以及每一个目标在原图中的占比
# -*- coding:utf-8 -*-
#统计
# 计算每一个目标在原图中的占比
# 计算目标的平均长度、
# 计算平均宽度,
# 计算平均面积、
# 计算目标平均占比
import os
import xml.etree.ElementTree as ET
import numpy as np
#np.set_printoptions(suppress=True, threshold=np.nan) #10,000,000
np.set_printoptions(suppress=True, threshold=10000000) #10,000,000
import matplotlib
from PIL import Image
def parse_obj(xml_path, filename):
tree = ET.parse(xml_path + filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def read_image(image_path, filename):
im = Image.open(image_path + filename)
W = im.size[0]
H = im.size[1]
area = W * H
im_info = [W, H, area]
return im_info
if __name__ == '__main__':
image_path = '/home/dlut/网络/make_database/数据集——合集/VOCdevkit/VOC2018/JPEGImages/'
xml_path = '/home/dlut/网络/make_database/数据集——合集/VOCdevkit/VOC2018/Annotations/'
filenamess = os.listdir(xml_path)
filenames = []
for name in filenamess:
name = name.replace('.xml', '')
filenames.append(name)
print(filenames)
recs = {}
ims_info = {}
obs_shape = {}
classnames = []
num_objs={}
obj_avg = {}
for i, name in enumerate(filenames):
print('正在处理 {}.xml '.format(name))
recs[name] = parse_obj(xml_path, name + '.xml')
print('正在处理 {}.jpg '.format(name))
ims_info[name] = read_image(image_path, name + '.jpg')
print('所有信息收集完毕。')
print('正在处理信息......')
for name in filenames:
im_w = ims_info[name][0]
im_h = ims_info[name][1]
im_area = ims_info[name][2]
for object in recs[name]:
if object['name'] not in num_objs.keys():
num_objs[object['name']] = 1
else:
num_objs[object['name']] += 1
#num_objs += 1
ob_w = object['bbox'][2] - object['bbox'][0]
ob_h = object['bbox'][3] - object['bbox'][1]
ob_area = ob_w * ob_h
w_rate = ob_w / im_w
h_rate = ob_h / im_h
area_rate = ob_area / im_area
if not object['name'] in obs_shape.keys():
obs_shape[object['name']] = ([[ob_w,
ob_h,
ob_area,
w_rate,
h_rate,
area_rate]])
else:
obs_shape[object['name']].append([ob_w,
ob_h,
ob_area,
w_rate,
h_rate,
area_rate])
if object['name'] not in classnames:
classnames.append(object['name']) # 求平均
for name in classnames:
obj_avg[name] = (np.array(obs_shape[name]).sum(axis=0)) / num_objs[name]
print('{}的情况如下:*******\n'.format(name))
print(' 目标平均W={}'.format(obj_avg[name][0]))
print(' 目标平均H={}'.format(obj_avg[name][1]))
print(' 目标平均area={}'.format(obj_avg[name][2]))
print(' 目标平均与原图的W比例={}'.format(obj_avg[name][3]))
print(' 目标平均与原图的H比例={}'.format(obj_avg[name][4]))
print(' 目标平均原图面积占比={}\n'.format(obj_avg[name][5]))
print('信息统计计算完毕。')
3.修改xml文件中某个目标的名字为另一个名字
#修改xml文件中的目标的名字,
import os, sys
import glob
from xml.etree import ElementTree as ET
# 批量读取Annotations下的xml文件
# per=ET.parse(r'C:\Users\rockhuang\Desktop\Annotations\000003.xml')
xml_dir = r'/home/dlut/网络/make_database/数据集——合集/VOCdevkit/VOC2018/Annotations'
xml_list = glob.glob(xml_dir + '/*.xml')
for xml in xml_list:
print(xml)
per = ET.parse(xml)
p = per.findall('/object')
for oneper in p: # 找出person节点
child = oneper.getchildren()[0] # 找出person节点的子节点
if child.text == 'PinNormal': #需要修改的名字
child.text = 'normal bolt' #修改成什么名字
if child.text == 'PinDefect': #需要修改的名字
child.text = 'defect bolt-1' #修改成什么名字
per.write(xml)
print(child.tag, ':', child.text)
感谢各位的阅读!关于“python如何批量统计xml中各类目标的数量”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





