本文实例讲述了Python使用循环神经网络解决文本分类问题的方法。分享给大家供大家参考,具体如下:
循环神经网络(Recurrent Neural Network, RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。
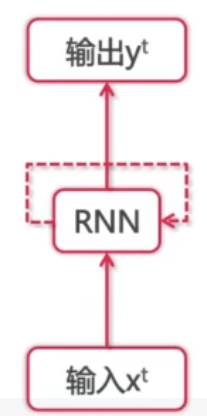
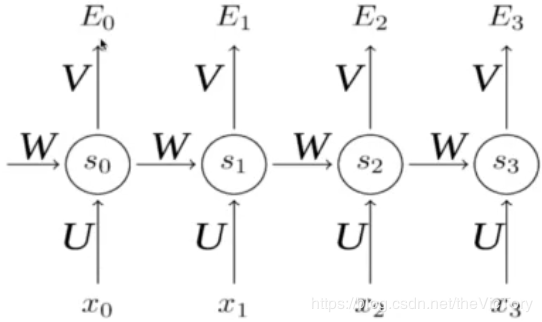
卷积网络的输入只有输入数据X,而循环神经网络除了输入数据X之外,每一步的输出会作为下一步的输入,如此循环,并且每一次采用相同的激活函数和参数。在每次循环中,x0乘以系数U得到s0,再经过系数W输入到下一次,以此循环构成循环神经网络的正向传播。

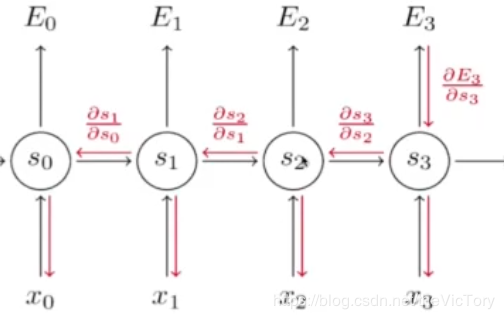
在反向传播中要求损失函数E对参数W的导数,通过链式求导法则可以得到右下的公式
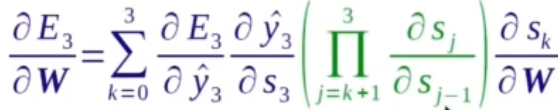
循环神经网络与卷积神经网络作比较,卷积神经网络是一个输出经过网络产生一个输出。而循环神经网络可以实现一个输入多个输出(生成图片描述)、多个输入一个输出(文本分类)、多输入多输出(机器翻译、视频解说)。
RNN使用的是tan激活函数,输出在-1到1之间,容易梯度消失。距离输出较远的步骤对于梯度贡献很小。
将底层的输出作为高层的输入就构成了多层的RNN网络,而且高层之间也可以进行传递,并且可以采用残差连接防止过拟合。
RNN的每次传播之间只有一个参数W,用这一个参数很难描述大量的、复杂的信息需求,为了解决这个问题引入了长短期记忆网络(Long Short Term Memory,LSTM)。这个网络可以进行选择性机制,选择性的输入、输出需要使用的信息以及选择性地遗忘不需要的信息。选择性机制的实现是通过Sigmoid门实现的,sigmoid函数的输出介于0到1之间,0代表遗忘,1代表记忆,0.5代表记忆50%
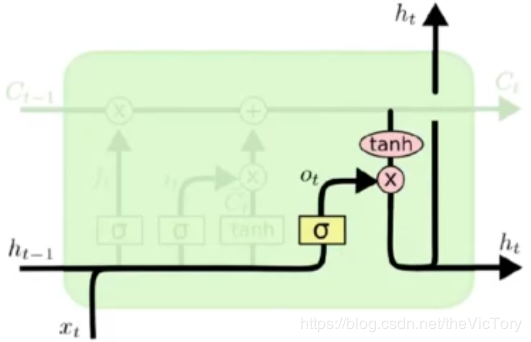
LSTM网络结构如下图所示,
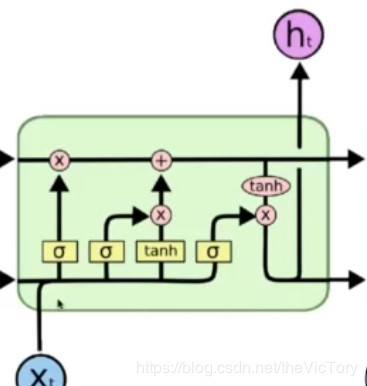
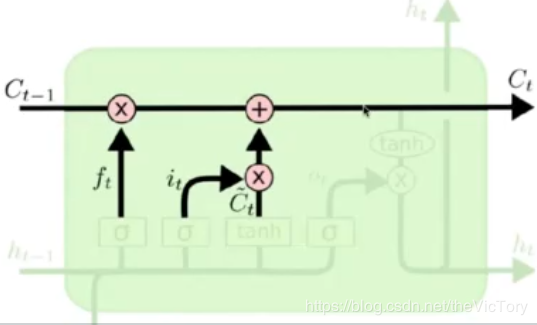
如上右图所示为本轮运算的隐含状态state,当前状态由上一状态和遗忘门结果作点积,再加上传入们结果得到
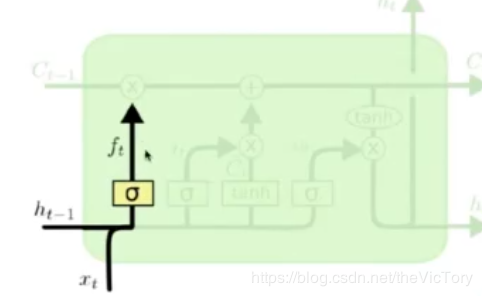
如下左图所示为遗忘门结构,上一轮的输出ht-1和数据xt在经过遗忘门选择是否遗忘之后,产生遗忘结果ft
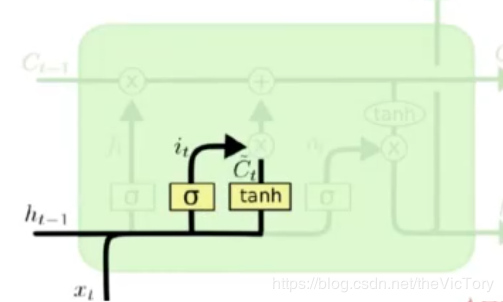
如下中图所示为传入门结构,ht-1和xt在经过遗忘门的结果it和tanh的结果Ct作点积运算得到本次运算的输入
如下右图所示为输出门结构,ht-1和xt经过遗忘门的结果ot与当状态作点积产生本次的输出
如下实现LSTM网络,首先定义_generate_params函数用于生成每个门所需的参数,调用该函数定义输入门、输出门、遗忘门、和中间状态tanh的参数。每个门的参数都是三个,输入x、h的权重和偏置值。
接着开始进行LSTM的每轮循环计算,输入门计算就是将输入embedded_input矩阵乘以输入门参数x_in,再加上h和对应参数相乘的结果,最后再加上偏置值b_in经过sigmoid便得到输入门结果。
同理进行矩阵相乘加偏置操作得到遗忘门、输出门的结果。中间态tanh与三个门的操作类似,只不过最后经过tanh函数。
将上一个隐含态state乘以遗忘门加上输入门乘以中间态的结果就得到当前的隐含态state
将当前的state经过tanh函数再加上输出门就得到本轮的输出h
经过多轮输入循环得到的就是LSTM网络的最后输出。
# 实现LSTM网络
# 生成Cell网格所需参数
def _generate_paramas(x_size, h_size, b_size):
x_w = tf.get_variable('x_weight', x_size)
h_w = tf.get_variable('h_weight', h_size)
bias = tf.get_variable('bias', b_size, initializer=tf.constant_initializer(0.0))
return x_w, h_w, bias
scale = 1.0 / math.sqrt(embedding_size + lstm_nodes[-1]) / 3.0
lstm_init = tf.random_uniform_initializer(-scale, scale)
with tf.variable_scope('lstm_nn', initializer=lstm_init):
# 输入门参数
with tf.variable_scope('input'):
x_in, h_in, b_in = _generate_paramas(
x_size=[embedding_size, lstm_nodes[0]],
h_size=[lstm_nodes[0], lstm_nodes[0]],
b_size=[1, lstm_nodes[0]]
)
# 输出门参数
with tf.variable_scope('output'):
x_out, h_out, b_out = _generate_paramas(
x_size=[embedding_size, lstm_nodes[0]],
h_size=[lstm_nodes[0], lstm_nodes[0]],
b_size=[1, lstm_nodes[0]]
)
# 遗忘门参数
with tf.variable_scope('forget'):
x_f, h_f, b_f = _generate_paramas(
x_size=[embedding_size, lstm_nodes[0]],
h_size=[lstm_nodes[0], lstm_nodes[0]],
b_size=[1, lstm_nodes[0]]
)
# 中间状态参数
with tf.variable_scope('mid_state'):
x_m, h_m, b_m = _generate_paramas(
x_size=[embedding_size, lstm_nodes[0]],
h_size=[lstm_nodes[0], lstm_nodes[0]],
b_size=[1, lstm_nodes[0]]
)
# 两个初始化状态,隐含状态state和初始输入h
state = tf.Variable(tf.zeros([batch_size, lstm_nodes[0]]), trainable=False)
h = tf.Variable(tf.zeros([batch_size, lstm_nodes[0]]), trainable=False)
# 遍历LSTM每轮循环,即每个词的输入过程
for i in range(max_words):
# 取出每轮输入,三维数组embedd_inputs的第二维代表训练的轮数
embedded_input = embedded_inputs[:, i, :]
# 将取出的结果reshape为二维
embedded_input = tf.reshape(embedded_input, [batch_size, embedding_size])
# 遗忘门计算
forget_gate = tf.sigmoid(tf.matmul(embedded_input, x_f) + tf.matmul(h, h_f) + b_f)
# 输入门计算
input_gate = tf.sigmoid(tf.matmul(embedded_input, x_in) + tf.matmul(h, h_in) + b_in)
# 输出门
output_gate = tf.sigmoid(tf.matmul(embedded_input, x_out) + tf.matmul(h, h_out) + b_out)
# 中间状态
mid_state = tf.tanh(tf.matmul(embedded_input, x_m) + tf.matmul(h, h_m) + b_m)
# 计算隐含状态state和输入h
state = state * forget_gate + input_gate * mid_state
h = output_gate + tf.tanh(state)
# 最后遍历的结果就是LSTM的输出
last_output = h
文本分类问题就是对输入的文本字符串进行分析判断,之后再输出结果。字符串无法直接输入到RNN网络,因此在输入之前需要先对文本拆分成单个词组,将词组进行embedding编码成一个向量,每轮输入一个词组,当最后一个词组输入完毕时得到输出结果也是一个向量。embedding将一个词对应为一个向量,向量的每一个维度对应一个浮点值,动态调整这些浮点值使得embedding编码和词的意思相关。这样网络的输入输出都是向量,再最后进行全连接操作对应到不同的分类即可。
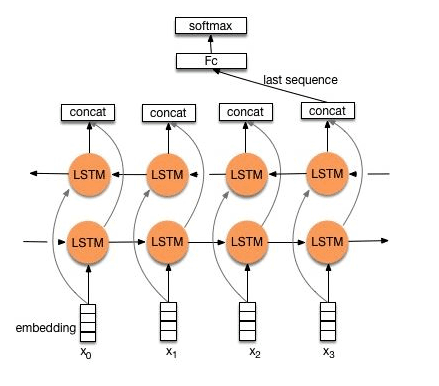
RNN网络不可避免地带来问题就是最后的输出结果受最近的输入较大,而之前较远的输入可能无法影响结果,这就是信息瓶颈问题,为了解决这个问题引入了双向LSTM。双向LSTM不仅增加了反向信息传播,而且每一轮的都会有一个输出,将这些输出进行组合之后再传给全连接层。
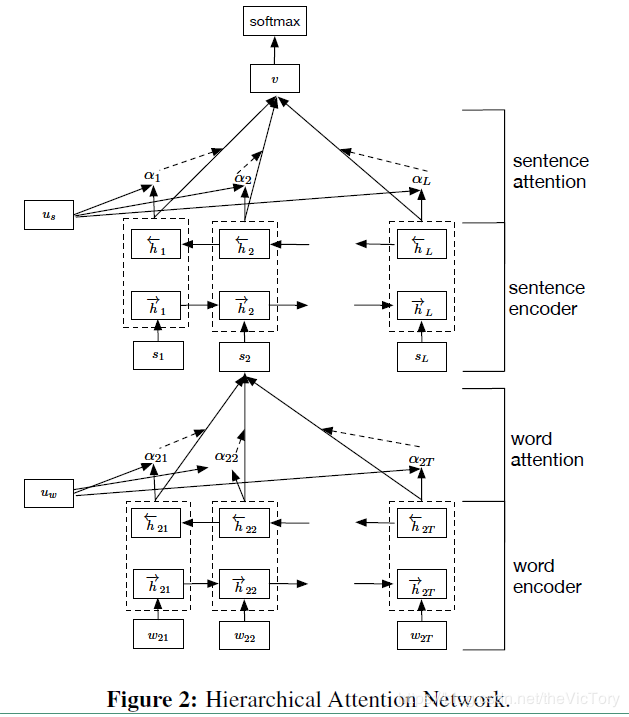
另一个文本分类模型就是HAN(Hierarchy Attention Network),首先将文本分为句子、词语级别,将输入的词语进行编码然后相加得到句子的编码,然后再将句子编码相加得到最后的文本编码。而attention是指在每一个级别的编码进行累加前,加入一个加权值,根据不同的权值对编码进行累加。
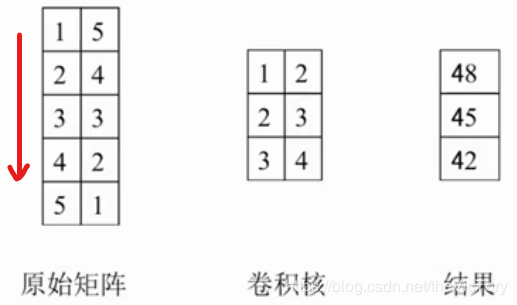
由于输入的文本长度不统一,所以无法直接使用神经网络进行学习,为了解决这个问题,可以将输入文本的长度统一为一个最大值,勉强采用卷积神经网络进行学习,即TextCNN。文本卷积网络的卷积过程采用的是多通道一维卷积,与二维卷积相比一维卷积就是卷积核只在一个方向上移动。例如下左图所示,1×1+5×2+2×2+4×3+3×3+3×4=48,之后卷积核向下移动一格得到45,以此类推。如下右图所示,输入长短不一的多个词汇。首先将其全部填充为六通道的embedding数组,然后采用六通道的一维卷积核从上到下进行卷积,得到一维的数组,然后再经过池化层和全连接层后输出。
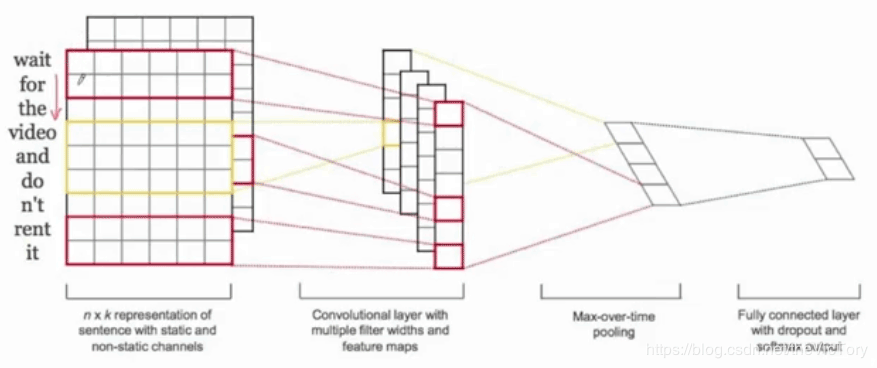
可以看到CNN网络不能完美处理输入长短不一的序列式问题,但是它可以并行处理多个词组,效率更高,而RNN可以更好地处理序列式的输入,将两者的优势结合起来就构成了R-CNN模型。首先通过双向RNN网络对输入进行特征提取,再使用CNN进一步提取,之后通过池化层将每一步的特征融合在一起,最后经过全连接层进行分类。
无论什么模型都需要使用embedding将输入转化为一个向量,当输入过大时,转化的embedding层参数就会过大,不仅不利于存储,还会造成过拟合,因此需要对embedding层进行压缩。原来的embedding编码是一个参数对应一个输入,例如wait对应参数x1,for对应x2,the对应x3。如果输入过多,编码参数就会很大,可以采用两个参数对组合的方式来编码输入,例如wait对应(x1,x2),for对应(x1,x3)...,这样就可以极大的节省参数的数量,这就是共享压缩。
在网上下载的文本分类数据集文件如下,分为测试集和训练集数据,每个训练集下有四个文件夹,每个文件夹是一个分类,每个分类有1000个txt文件,每个文件中有一条该分类的文本


通过os.walk遍历所有训练集文件,将分类文本通过jieba库拆分成单个词组,用空格分隔。然后将分类文本添加到开头,并用制表符分隔,最后将结果输出到train_segment.txt,
# 将文件中的句子通过jieba库拆分为单个词
def segment_word(input_file, output_file):
# 循环遍历训练数据集的每一个文件
for root, folders, files in os.walk(input_file):
print('root:', root)
for folder in folders:
print('dir:', folder)
for file in files:
file_dir = os.path.join(root, file)
with open(file_dir, 'rb') as in_file:
# 读取文件中的文本
sentence = in_file.read()
# 通过jieba函数库将句子拆分为单个词组
words = jieba.cut(sentence)
# 文件夹路径最后两个字即为分类名
content = root[-2:] + '\t'
# 去除词组中的空格,排除为空的词组
for word in words:
word = word.strip(' ')
if word != '':
content += word + ' '
# 换行并将文本写入输出文件
content += '\n'
with open(output_file, 'a') as outfile:
outfile.write(content.strip(' '))
结果如下:

由于一些词组出现次数很少,不具有统计意义,所以需要排除,通过get_list()方法统计每个词组出现的频率。利用python自带的dictionary数据类型可以轻易实现词组数据统计,格式为{"keyword":frequency},frequency记录keyword出现的次数。如果一个词组是新出现的则作为新词条加入词典,否则将frequency值+1。
# 统计每个词出现的频率
def get_list(segment_file, out_file):
# 通过词典保存每个词组出现的频率
word_dict = {}
with open(segment_file, 'r') as seg_file:
lines = seg_file.readlines()
# 遍历文件的每一行
for line in lines:
line = line.strip('\r\n')
# 将一行按空格拆分为每个词,统计词典
for word in line.split(' '):
# 如果这个词组没有在word_dict词典中出现过,则新建词典项并设为0
word_dict.setdefault(word, 0)
# 将词典word_dict中词组word对应的项计数加一
word_dict[word] += 1
# 将词典中的列表排序,关键字为列表下标为1的项,且逆序
sorted_list = sorted(word_dict.items(), key=lambda d: d[1], reverse=True)
with open(out_file, 'w') as outfile:
# 将排序后的每条词典项写入文件
for item in sorted_list:
outfile.write('%s\t%d\n' % (item[0], item[1]))
统计结果如下:

直接使用词组无法进行编码学习,需要将词组转化为embedding编码,根据刚才生成的train_list列表,按照从前往后的顺序为每个词组编号,如果词组频率小于阈值则排除掉。通过Word_list类来构建训练数据、测试数据的词组对象,在类的构造函数__init__()实现词组的编码。并定义类方法sentence2id将拆分好的句子词组转化为对应的id数组,如果词组列表中没有该词,则将该值置为-1。
在定义类之前首先规定一些超参数供后续使用:
# 定义超参数 embedding_size = 32 # 每个词组向量的长度 max_words = 10 # 一个句子最大词组长度 lstm_layers = 2 # lstm网络层数 lstm_nodes = [64, 64] # lstm每层结点数 fc_nodes = 64 # 全连接层结点数 batch_size = 100 # 每个批次样本数据 lstm_grads = 1.0 # lstm网络梯度 learning_rate = 0.001 # 学习率 word_threshold = 10 # 词表频率门限,低于该值的词语不统计 num_classes = 4 # 最后的分类结果有4类
class Word_list:
def __init__(self, filename):
# 用词典类型来保存需要统计的词组及其频率
self._word_dic = {}
with open(filename, 'r',encoding='GB2312',errors='ignore') as f:
lines = f.readlines()
for line in lines:
word, freq = line.strip('\r\n').split('\t')
freq = int(freq)
# 如果词组的频率小于阈值,跳过不统计
if freq < word_threshold:
continue
# 词组列表中每个词组都是不重复的,按序添加到word_dic中即可,下一个词组id就是当前word_dic的长度
word_id = len(self._word_dic)
self._word_dic[word] = word_id
def sentence2id(self, sentence):
# 将以空格分割的句子返回word_dic中对应词组的id,若不存在返回-1
sentence_id = [self._word_dic.get(word, -1)
for word in sentence.split()]
return sentence_id
train_list = Word_list(train_list_dir)
定义TextData类来完成数据的读入和管理,在__init__()函数中读取刚才处理好的train_segment.txt文件,根据制表符分割类别标记和句子词组,将类别和句子分别转化为数字id。如果句子的词组超过了最大阈值,则截去后面多余的,如果不够则用-1填充。定义类函数_shuffle_data()用于清洗数据,next_batch()用于按批次返回数据和标签,get_size()用于返回词组总条数。
class TextData:
def __init__(self, segment_file, word_list):
self.inputs = []
self.labels = []
# 通过词典管理文本类别
self.label_dic = {'体育': 0, '校园': 1, '女性': 2, '出版': 3}
self.index = 0
with open(segment_file, 'r') as f:
lines = f.readlines()
for line in lines:
# 文本按制表符分割,前面为类别,后面为句子
label, content = line.strip('\r\n').split('\t')[0:2]
self.content_size = len(content)
# 将类别转换为数字id
label_id = self.label_dic.get(label)
# 将句子转化为embedding数组
content_id = word_list.sentence2id(content)
# 如果句子的词组长超过最大值,截取max_words长度以内的id值
content_id = content_id[0:max_words]
# 如果不够则填充-1,直到max_words长度
padding_num = max_words - len(content_id)
content_id = content_id + [-1 for i in range(padding_num)]
self.inputs.append(content_id)
self.labels.append(label_id)
self.inputs = np.asarray(self.inputs, dtype=np.int32)
self.labels = np.asarray(self.labels, dtype=np.int32)
self._shuffle_data()
# 对数据按照(input,label)对来打乱顺序
def _shuffle_data(self):
r_index = np.random.permutation(len(self.inputs))
self.inputs = self.inputs[r_index]
self.labels = self.labels[r_index]
# 返回一个批次的数据
def next_batch(self, batch_size):
# 当前索引+批次大小得到批次的结尾索引
end_index = self.index + batch_size
# 如果结尾索引大于样本总数,则打乱所有样本从头开始
if end_index > len(self.inputs):
self._shuffle_data()
self.index = 0
end_index = batch_size
# 按索引返回一个批次的数据
batch_inputs = self.inputs[self.index:end_index]
batch_labels = self.labels[self.index:end_index]
self.index = end_index
return batch_inputs, batch_labels
# 获取词表数目
def get_size(self):
return self.content_size
# 训练数据集对象
train_set = TextData(train_segment_dir, train_list)
# print(data_set.next_batch(10))
# 训练数据集词组条数
train_list_size = train_set.get_size()
定义函数create_model来实现计算图模型的构建。首先定义模型输入的占位符,分别为输入文本inputs、输出标签outputs、Dropout的比率keep_prob。
首先构建embedding层,将输入的inputs编码抽取出来拼接成一个矩阵,例如输入[1,8,3]则抽取embeding[1]、embedding[8]和embedding[3]拼接成一个矩阵
接下来构建LSTM网络,这里构建了两层网络,每层的结点数在之前的参数lstm_node[]数组中定义。每个cell的构建通过函数tf.contrib.rnn.BasicLSTMCell实现,之后经过Dropout操作。再将两个cell合并为一个LSTM网络,通过函数tf.nn.dynamic_rnn将输入embedded_inputs输入到LSTM网络中进行训练得到输出rnn_output。这是一个三维数组,第二维表示训练的步数,我们只取最后一维的结果,即下标值为-1.
接下来构建全连接层,通过tf.layers.dense函数定义全连接层,再经过一个dropout操作后将输出映射到类别上,类别的种类的参数num_classes,得到估计值logits
接下来就可以求损失、精确率等评估值了。计算算预测值logits与标签值outputs之间的交叉熵损失值,接下来通过arg_max计算预测值,进而求准确率
接下来定义训练方法,通过梯度裁剪应用到变量上以防止梯度消失。
最后将输入占位符、损失等评估值、其他训练参数返回到调用函数的外部。
# 创建计算图模型
def create_model(list_size, num_classes):
# 定义输入输出占位符
inputs = tf.placeholder(tf.int32, (batch_size, max_words))
outputs = tf.placeholder(tf.int32, (batch_size,))
# 定义是否dropout的比率
keep_prob = tf.placeholder(tf.float32, name='keep_rate')
# 记录训练的总次数
global_steps = tf.Variable(tf.zeros([], tf.float32), name='global_steps', trainable=False)
# 将输入转化为embedding编码
with tf.variable_scope('embedding',
initializer=tf.random_normal_initializer(-1.0, 1.0)):
embeddings = tf.get_variable('embedding', [list_size, embedding_size], tf.float32)
# 将指定行的embedding数值抽取出来
embedded_inputs = tf.nn.embedding_lookup(embeddings, inputs)
# 实现LSTM网络
scale = 1.0 / math.sqrt(embedding_size + lstm_nodes[-1]) / 3.0
lstm_init = tf.random_uniform_initializer(-scale, scale)
with tf.variable_scope('lstm_nn', initializer=lstm_init):
# 构建两层的lstm,每层结点数为lstm_nodes[i]
cells = []
for i in range(lstm_layers):
cell = tf.contrib.rnn.BasicLSTMCell(lstm_nodes[i], state_is_tuple=True)
# 实现Dropout操作
cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=keep_prob)
cells.append(cell)
# 合并两个lstm的cell
cell = tf.contrib.rnn.MultiRNNCell(cells)
# 将embedded_inputs输入到RNN中进行训练
initial_state = cell.zero_state(batch_size, tf.float32)
# runn_output:[batch_size,num_timestep,lstm_outputs[-1]
rnn_output, _ = tf.nn.dynamic_rnn(cell, embedded_inputs, initial_state=initial_state)
last_output = rnn_output[:, -1, :]
# 构建全连接层
fc_init = tf.uniform_unit_scaling_initializer(factor=1.0)
with tf.variable_scope('fc', initializer=fc_init):
fc1 = tf.layers.dense(last_output, fc_nodes, activation=tf.nn.relu, name='fc1')
fc1_drop = tf.contrib.layers.dropout(fc1, keep_prob)
logits = tf.layers.dense(fc1_drop, num_classes, name='fc2')
# 定义评估指标
with tf.variable_scope('matrics'):
# 计算损失值
softmax_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=outputs)
loss = tf.reduce_mean(softmax_loss)
# 计算预测值,求第1维中最大值的下标,例如[1,1,5,3,2] argmax=> 2
y_pred = tf.argmax(tf.nn.softmax(logits), 1, output_type=tf.int32)
# 求准确率
correct_prediction = tf.equal(outputs, y_pred)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 定义训练方法
with tf.variable_scope('train_op'):
train_var = tf.trainable_variables()
# for var in train_var:
# print(var)
# 对梯度进行裁剪防止梯度消失或者梯度爆炸
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, train_var), clip_norm=lstm_grads)
# 将梯度应用到变量上去
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.apply_gradients(zip(grads, train_var), global_steps)
# 以元组的方式将结果返回
return ((inputs, outputs, keep_prob),
(loss, accuracy),
(train_op, global_steps))
# 调用构建函数,接收解析返回的参数
placeholders, matrics, others = create_model(train_list_size, num_classes)
inputs, outputs, keep_prob = placeholders
loss, accuracy = matrics
train_op, global_steps = others
通过Session运行计算图模型,从train_set中按批次获取训练集数据并填充占位符,运行sess.run,获取损失值、准确率等中间值打印
# 进行训练
init_op = tf.global_variables_initializer()
train_keep_prob = 0.8 # 训练集的dropout比率
train_steps = 10000
with tf.Session() as sess:
sess.run(init_op)
for i in range(train_steps):
# 按批次获取训练集数据
batch_inputs, batch_labels = train_set.next_batch(batch_size)
# 运行计算图
res = sess.run([loss, accuracy, train_op, global_steps],
feed_dict={inputs: batch_inputs, outputs: batch_labels,
keep_prob: train_keep_prob})
loss_val, acc_val, _, g_step_val = res
if g_step_val % 20 == 0:
print('第%d轮训练,损失:%3.3f,准确率:%3.5f' % (g_step_val, loss_val, acc_val))
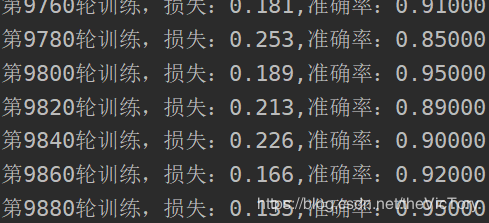
在我的数据集进行一万轮训练后,训练集的准确率在90%左右徘徊
源代码及相关数据文件:https://github.com/SuperTory/MachineLearning/tree/master/TextRNN
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数据结构与算法教程》、《Python加密解密算法与技巧总结》、《Python编码操作技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





