这篇文章主要介绍了Python如何利用全连接神经网络求解MNIST问题,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
人类的神经元在树突接受刺激信息后,经过细胞体处理,判断如果达到阈值,则将信息传递给下一个神经元或输出。类似地,神经元模型在输入层输入特征值x之后,与权重w相乘求和再加上b,经过激活函数判断后传递给下一层隐藏层或输出层。
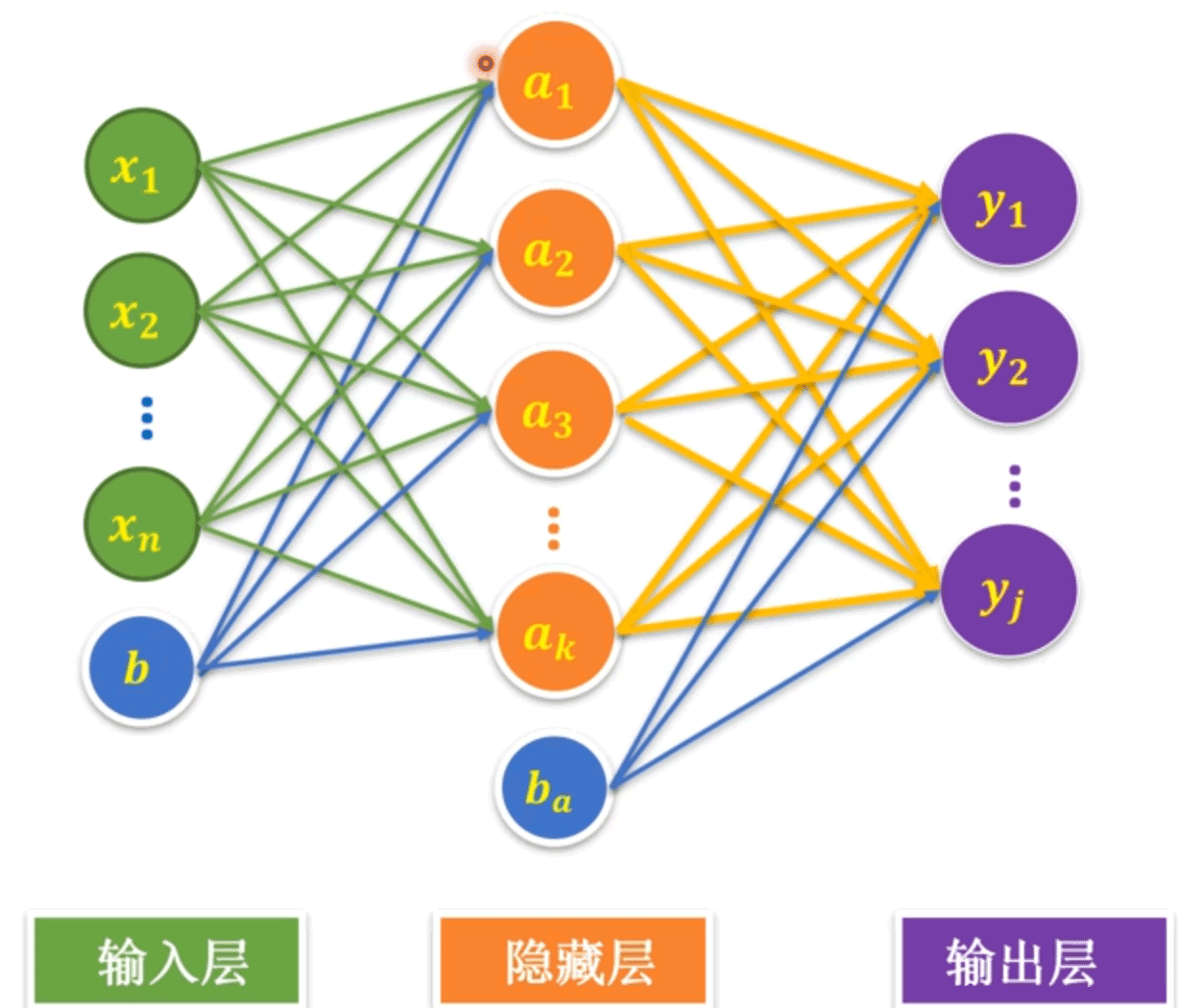
单神经元的模型只有一个求和节点(如左下图所示)。全连接神经网络(Full Connected Networks)如右下图所示,中间层有多个神经元,并且每层的每个神经元都是与上一层和下一层的节点都对应连接。中间隐藏层只有一层的神经元网络称为单隐藏层神经网络。如果有多个中间隐藏层则称为多隐藏层神经网络。
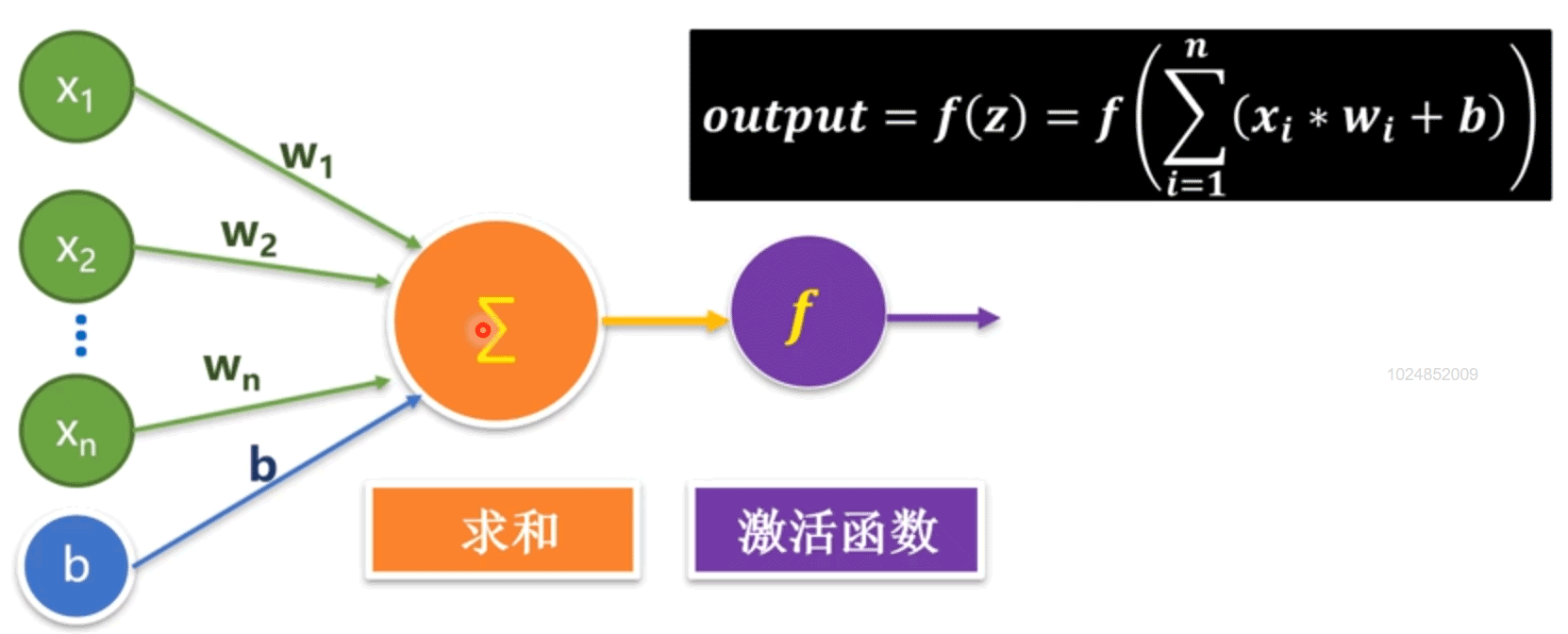
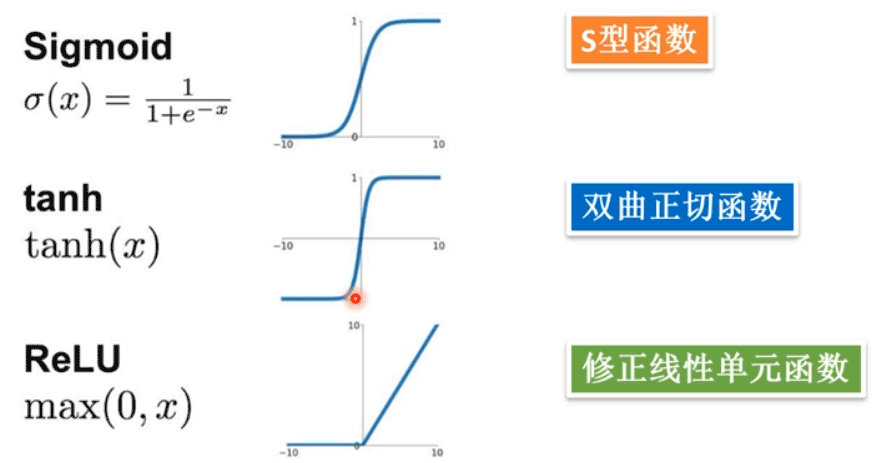
常见的激活函数如下所示:
下面是在单个神经元逻辑回归求解MNIST手写数字识别问题的基础上,采用单隐藏层神经网络进行求解的过程。
首先载入数据,从Tensor FLow提供的数据库中导入MNIST数据
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist=input_data.read_data_sets('MNIST_data/',one_hot=True)构建输入层,其中x是图像的特征值,由于是28×28=784个像素点,所有输入为未知行数、每行784的二维数组。y是图像的标签值,共有0~9十种可能,所有为[None,10]的二维数组
x=tf.placeholder(tf.float32,[None,784],name='x') y=tf.placeholder(tf.float32,[None,10],name='y')
构建隐藏层,设置隐藏层神经元个数为256,由于输入层输入为784,而隐藏层神经元为h2_num,所以W1为[784,h2_num]形式的二维数组,b为[h2_num]的一维向量。此外采用ReLU作为激活函数处理输出。
h2_num=256 #设置隐藏层神经元数量 W1=tf.Variable(tf.random_normal([784,h2_num]),name='W1') b1=tf.Variable(tf.zeros([h2_num]),name='b1') Y1=tf.nn.relu(tf.matmul(x,W1)+b1) #激活函数
构建输出层,由于隐藏层有h2_num个神经元输出,输出层输出10种输出结果,所以W2为[h2_num,10]的二维数组,b2为[10]的一维向量。最后结果通过softmax将线性输出Y2转化为独热编码方式。
W2=tf.Variable(tf.random_normal([h2_num,10]),name='W2') b2=tf.Variable(tf.zeros([10]),name='b2') Y2=tf.matmul(Y1,W2)+b2 pred=tf.nn.softmax(Y2)
设置训练的超参数、损失函数、优化器,这里采用Adam Optimizer进行优化。准确率是通过比较预测值和标签值是否一致来定义。在定义损失函数时,如果直接使用交叉熵的方式定义,会出现log0值为NaN的情况,导致数据不稳定,无法得出结果。Tensor Flow提供了结合softmax定义交叉熵的方式softmax_cross_entropy_with_logits(),第一个参数为不经softmax处理的前向计算结果Y2,第二个参数为标签值y
train_epochs=20 #训练轮数 batch_size=50 #每个批次的样本数 batch_num=int(mnist.train.num_examples/batch_size) #一轮需要训练多少批 learning_rate=0.01 #定义损失函数、优化器 loss_function=tf.reduce_mean( #softmax交叉熵损失函数 tf.nn.softmax_cross_entropy_with_logits(logits=Y2,labels=y)) optimizer=tf.train.AdamOptimizer(learning_rate).minimize(loss_function) #定义准确率 correct_prediction=tf.equal(tf.argmax(pred,1),tf.argmax(y,1)) accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
进行训练并输出损失值与准确率,训练进行多轮,每轮一开始分批次读入数据进行训练,每结束一轮输出一次损失和准确率。
ss=tf.Session()
ss.run(tf.global_variables_initializer()) #进行全部变量的初始化
for epoch in range(train_epochs):
for batch in range(batch_num): #分批次读取数据进行训练
xs,ys=mnist.train.next_batch(batch_size)
ss.run(optimizer,feed_dict={x:xs,y:ys})
loss,acc=ss.run([loss_function,accuracy],\
feed_dict={x:mnist.validation.images,y:mnist.validation.labels})
print('第%2d轮训练:损失为:%9f,准确率:%.4f'%(epoch+1,loss,acc))
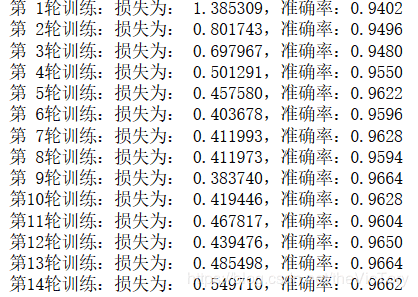
ss.close()运行结果如下图,与单个神经元相比,可以较快得到较高的准确率
评估模型,将测试集数据填充入占位符x,y去求准确率,
test_res=ss.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print('测试集的准确率为:%.4f'%(test_res))多层是指中间的隐藏层有多个,例如使用两层隐藏层,第一个隐藏层在计算后将结果输出到第二个隐藏层,再由第二个隐藏层计算后交给输出层,而第二个隐藏层的设置与第一个基本相同,例如:
#构建输入层 x=tf.placeholder(tf.float32,[None,784],name='x') y=tf.placeholder(tf.float32,[None,10],name='y') #构建第一个隐藏层 h2_num=256 #第一隐藏层神经元数量256 W1=tf.Variable(tf.truncated_normal([784,h2_num],stddev=0.1),name='W1') b1=tf.Variable(tf.zeros([h2_num]),name='b1') Y1=tf.nn.relu(tf.matmul(x,W1)+b1) #构建第二个隐藏层 h3_num=64 #第二隐藏层神经元数量64 W2=tf.Variable(tf.random_normal([h2_num,h3_num],stddev=0.1),name='W2') b2=tf.Variable(tf.zeros([h3_num]),name='b2') Y2=tf.nn.relu(tf.matmul(Y1,W2)+b2) #构建输出层 W3=tf.Variable(tf.random_normal([h3_num,10],stddev=0.1),name='W3') b3=tf.Variable(tf.zeros([10]),name='b3') Y3=tf.matmul(Y2,W3)+b3 pred=tf.nn.softmax(Y3)
在第一隐藏层产生参数W1时采用的是截断正态分布的随机函数tf.truncated_normal(),与普通正太分布相比,截断正态分布生成的值之间的差距不会太大。
设置的第一隐藏层的神经元256个,第二层64个,因此第二层的每个输入有256个特征值,并产生64个输出,相应的W2的shape为[h2_num,h3_num],b2的shape为[h3_num]。输出层W3的shape为[h3_num,10]。函数的其他部分与单层神经网络相同。
经过运算多层的神经网络训练的准确率不一定比单层的高,因为还涉及到训练的超参数的设置等多种因素。但是多层神经网络的运行速度比单层慢,越多层的神经网络意味着更加复杂的计算量。
通过以上多层神经网络的定义可以看出两个隐藏层与输出层的构建方法基本类似,都是定义对应的变量W、b,在定义W时其shape为[输出维度,输出维度],因此可以将隐藏层与输出层统一定义为一个全连接层函数:
#定义一个通用的全连接层函数模型 def fcn_layer(inputs,in_dim,out_dim,activation=None): W=tf.Variable(tf.truncated_normal([in_dim,out_dim],stddev=0.1)) b=tf.Variable(tf.zeros([out_dim])) Y=tf.matmul(inputs,W)+b if activation==None: output=Y else: output=activation(Y) return output #构建第一个隐藏层 Y1=fcn_layer(x,784,256,tf.nn.relu) #构建第二个隐藏层 Y2=fcn_layer(Y1,256,64,tf.nn.relu) #构建输出层 Y3=fcn_layer(Y2,64,10) pred=tf.nn.softmax(Y3)
其中inputs为本层的输入,in_dim为本层的输入维度,也就是上一层的输出维度,out_dim为本层的输出维度,activation为激活函数,默认为None。将输入与权重W叉乘再加上偏置值b得到Y,如果定义了激活函数,用激活函数处理Y,否则直接将Y赋给output输出。
在模型训练结束后,如果希望下次继续使用或训练模型则需要将储存起来。
首先需要定义模型数据的保存路径:
import os save_dir='D:/Temp/MachineLearning/ModelSaving/' #定义模型的保存路径 if not os.path.exists(save_dir): #如果不存在该路径则创建 os.makedirs(save_dir)
定义储存粒度与saver,所谓储存粒度即每个几轮数据进行一次储存
save_step=5 #定义存储粒度 saver=tf.train.Saver() #定义saver
在每轮训练结束后进行判断,每隔5轮储存一次,储存路径中拼接轮数信息,
if epoch%save_step==0:
saver.save(ss,os.path.join(save_dir,'mnist_fcn_{:02d}.ckpt'.format(epoch+1)))在所有迭代训练执行结束后,再整体储存一次
saver.save(ss,os.path.join(save_dir,'mnist_fcn.ckpt'))
这样就会在指定目录下生成模型的保存文件:
从定义的模型目录中读取存盘点数据,并将其中的参数赋值给当前的session,然后便可以直接利用session进行测试,其准确率与保存时一致。
save_dir='D:/Temp/MachineLearning/ModelSaving/' #定义模型的保存路径
saver=tf.train.Saver() #定义saver
ss=tf.Session()
ss.run(tf.global_variables_initializer())
ckpt=tf.train.get_checkpoint_state(save_dir) #读取存盘点
if ckpt and ckpt.model_checkpoint_path:
saver.restore(ss,ckpt.model_checkpoint_path) #从存盘中恢复参数到当前的session
print('数据恢复从',ckpt.model_checkpoint_path)
test_res=accuracy.eval(session=ss,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print('测试集的准确率为:%.4f'%(test_res))在读取模型时有时候会遇到报错:
NotFoundError (see above for traceback): Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint.
这时只需重启kernel即可。
也可以将训练好的模型以图的形式保存为.pb文件,下次直接可以使用,但不可以继续训练。
通过tf.train.write_graph函数来保存模型如下:
import tensorflow as tf v=tf.Variable(1.0,'new_var') with tf.Session() as ss: tf.train.write_graph(ss.graph_def,'D:\Temp\MachineLearning\ModelSaving\Graph', 'test_graph.pb',as_text=False)
读取图文件并还原:
with tf.Session() as ss:
with tf.gfile.GFile('D:/Temp\MachineLearning/ModelSaving/Graph/test_graph.pb','rb') as pb_file:
graph_def=tf.GraphDef()
graph_def.ParseFromString(pb_file.read())
ss.graph.as_default()
tf.import_graph_def(graph_def)
print(graph_def)感谢你能够认真阅读完这篇文章,希望小编分享的“Python如何利用全连接神经网络求解MNIST问题”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





