方法: 使用urlencode函数
urllib.request.urlopen()
import urllib.request
import urllib.parse
url = 'https://www.sogou.com/web?'
#将get请求中url携带的参数封装至字典中
param = {
'query':'周杰伦'
}
#对url中的非ascii进行编码
param = urllib.parse.urlencode(param)
#将编码后的数据值拼接回url中
url += param
response = urllib.request.urlopen(url=url)
data = response.read()
with open('./周杰伦1.html','wb') as fp:
fp.write(data)
print('写入文件完毕')开发者工具浏览器按F12或者右键按检查 ,有个抓包工具network,刷新页面,可以看到网页资源,可以看到请求头信息,UA
在抓包工具点击任意请求,可以看到所有请求信息,向应信息,
主要用到headers,response,response headers存放响应头信息,request headers 存放请求信息
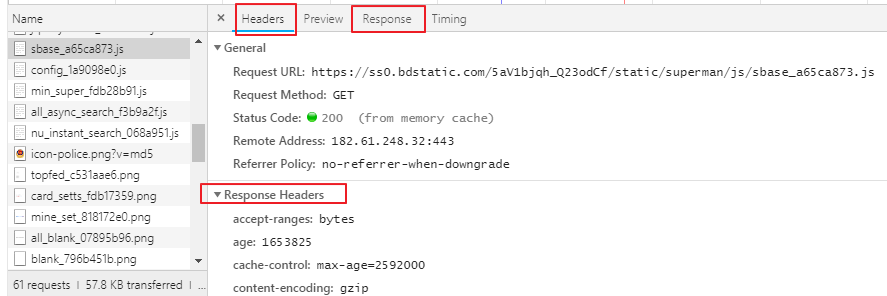
反爬出机制:网站会检查请求的UA,如果发现UA是爬虫程序,会拒绝提供网站页面数据。
如果网站检查发现请求UA是基于某一款浏览器标识(浏览器发起的请求),网站会认为请求是正常请求,会把页面数据响应信息给客户端
User-Agent(UA):请求载体的身份标识
反反爬虫机制:
伪造爬虫程序的请求的UA,把爬虫程序的请求UA伪造成谷歌标识,火狐标识
通过自定义请求对象,用于伪装爬虫程序请求的身份。
User-Agent参数,简称为UA,该参数的作用是用于表明本次请求载体的身份标识。如果我们通过浏览器发起的请求,则该请求的载体为当前浏览器,则UA参数的值表明的是当前浏览器的身份标识表示的一串数据。
如果我们使用爬虫程序发起的一个请求,则该请求的载体为爬虫程序,那么该请求的UA为爬虫程序的身份标识表示的一串数据。
有些网站会通过辨别请求的UA来判别该请求的载体是否为爬虫程序,如果为爬虫程序,则不会给该请求返回响应,那么我们的爬虫程序则也无法通过请求爬取到该网站中的数据值,这也是反爬虫的一种初级技术手段。那么为了防止该问题的出现,则我们可以给爬虫程序的UA进行伪装,伪装成某款浏览器的身份标识。
上述案例中,我们是通过request模块中的urlopen发起的请求,该请求对象为urllib中内置的默认请求对象,我们无法对其进行UA进行更改操作。urllib还为我们提供了一种自定义请求对象的方式,我们可以通过自定义请求对象的方式,给该请求对象中的UA进行伪装(更改)操作。
自定义请求头信息字典可以添加谷歌浏览器的UA标识,自定义请求对象来伪装成谷歌UA
1.封装自定义的请求头信息的字典,
2.注意:在headers字典中可以封装任意的请求头信息
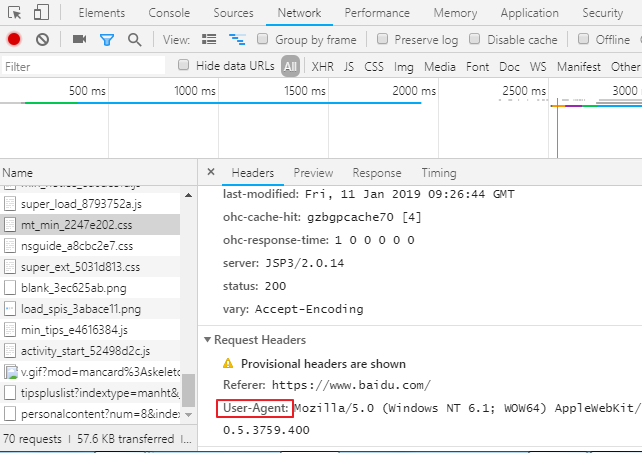
3.将浏览器的UA数据获取,封装到一个字典中。该UA值可以通过抓包工具或者浏览器自带的开发者工具中获取某请求,
从中获取UA的值
import urllib.request
import urllib.parse
url = 'https://www.sogou.com/web?query='
# url的特性:url不可以存在非ASCII编码字符数据
word = urllib.parse.quote("周杰伦")
# 将编码后的数据值拼接回url中
url = url+word # 有效url
# 发请求之前对请求的UA进行伪造,伪造完再对请求url发起请求
# UA伪造
# 1 子制定一个请求对象,headers是请求头信息,字典形式
# 封装自定义的请求头信息的字典,
# 注意:在headers字典中可以封装任意的请求头信息
headers = {
# 存储任意的请求头信息
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
# 该请求对象的UA进行了成功的伪装
request = urllib.request.Request(url=url, headers=headers)
# 2.针对自定义请求对象发起请求
response = urllib.request.urlopen(request)
# 3.获取响应对象中的页面数据:read函数可以获取响应对象中存储的页面数据(byte类型的数据值)
page_text = response.read()
# 4.持久化存储:将爬取的页面数据写入文件进行保存
with open("周杰伦.html","wb") as f:
f.write(page_text)
print("写入数据成功")这样就可以突破网站的反爬机制
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



