首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构:
https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start=0
这是接口地址,可以大概的分析一下各个参数的规则:
下面这里是返回的json数据格式,可以看出我们要的是json中subjects列表中的每条数据,在之后的程序中会把每一个电视剧的信息保存到文件里的一行

有了这些,就直接上程序了,因为感觉程序还是比较好懂,主要还是遵从面向对象的程序设计:
import json
import requests
class DoubanSpider(object):
"""爬取豆瓣热门国产电视剧的数据并保存到本地"""
def __init__(self):
# url_temp中的start的值是动态的,所以这里用{}替换,方便后面使用format方法
self.url_temp = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
def pass_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode()
def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str)
content_list = dict_ret['subjects']
return content_list
def save_content_list(self, content_list): # 保存
with open('douban.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False)) # 一部电视剧的信息一行
f.write('\n') # 写入换行符进行换行
print('保存成功!')
def run(self): # 实现主要逻辑
num = 0
while True:
# 1. start_url
url = self.url_temp.format(num)
# 2. 发送请求,获取响应
json_str = self.pass_url(url)
# 3. 提取数据
content_list = self.get_content_list(json_str)
# 4. 保存
self.save_content_list(content_list)
if len(content_list) < 20:
break
# 5. 构造下一页url地址,进入循环
num += 20 # 每一页有二十条数据
if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()上面是利用循环遍历每一页,后来我又想到用递归也可以,虽然递归效率可能不高,这里还是展示一下,只需要改几个地方而已:
import json
import requests
class DoubanSpider(object):
"""爬取豆瓣热门国产电视剧的数据并保存到本地"""
def __init__(self):
# url_temp中的start的值是动态的,所以这里用{}替换,方便后面使用format方法
self.url_temp = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
self.num = 0
def pass_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode()
def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str)
content_list = dict_ret['subjects']
return content_list
def save_content_list(self, content_list): # 保存
with open('douban2.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False)) # 一部电视剧的信息一行
f.write('\n') # 写入换行符进行换行
print('保存成功!')
def run(self): # 实现主要逻辑
# 1. start_url
url = self.url_temp.format(self.num)
# 2. 发送请求,获取响应
json_str = self.pass_url(url)
# 3. 提取数据
content_list = self.get_content_list(json_str)
# 4. 保存
self.save_content_list(content_list)
# 5. 构造下一页url地址,进入循环
if len(content_list) == 20:
self.num += 20 # 每一页有二十条数据
self.run()
if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()
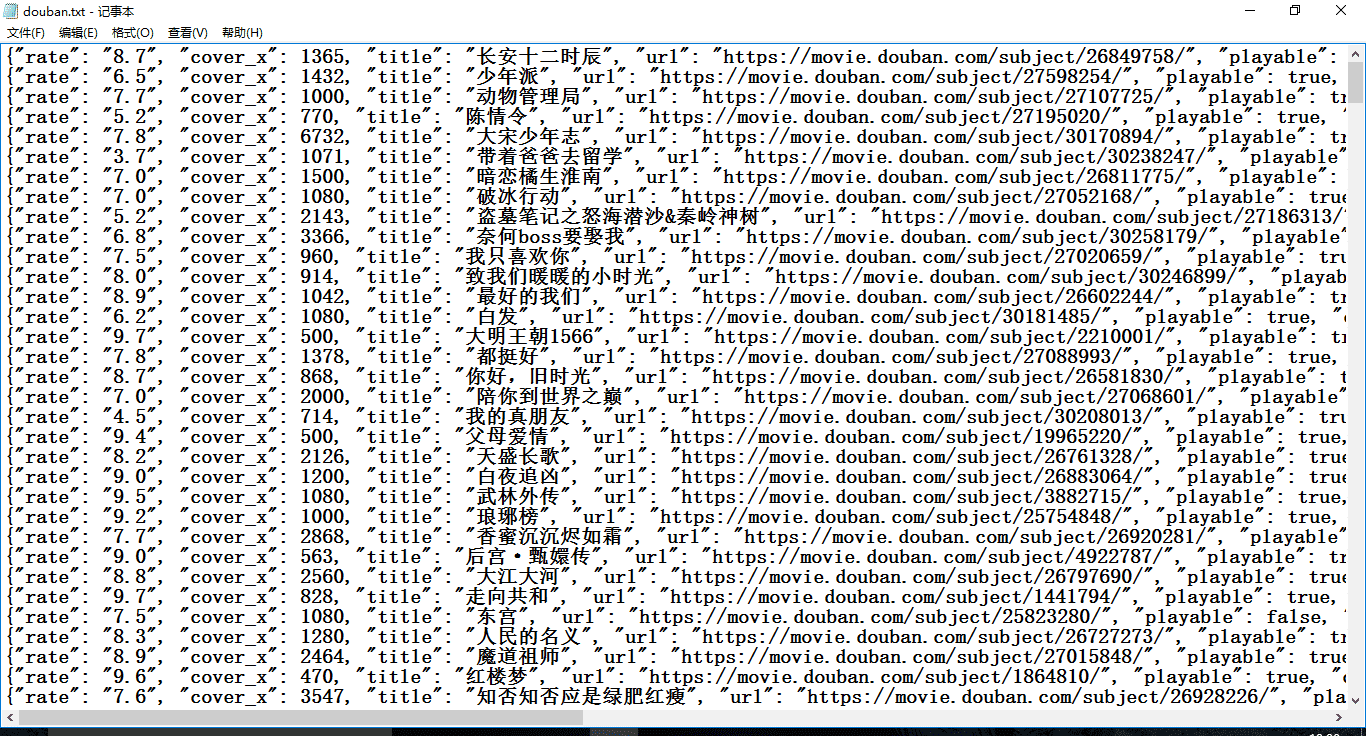
最终文件得到的结果:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



