pythonиҜҶеҲ«еӣҫеғҸ并жҸҗеҸ–ж–Үеӯ—зҡ„е®һзҺ°
pythonиҜҶеҲ«еӣҫеғҸ并жҸҗеҸ–ж–Үеӯ—зҡ„е®һзҺ°пјҹеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
1. дҫқиө–е®үиЈ…
yum install -y automake autoconf libtool gcc gcc-c++
2. е®үиЈ…leptonica
Leptonicaдё»иҰҒз”ЁдәҺеӣҫеғҸеӨ„зҗҶе’ҢеӣҫеғҸеҲҶжһҗ
еҺҹеҲҷдёҠжүҖжңүзҡ„еә“ж–Ү件йғҪжҳҜеҸҜд»ҘзӣҙжҺҘз”Ёyumе®үиЈ…зҡ„пјҢеҰӮжһңжғіиҰҒе…·дҪ“зҡ„жҹҗдёӘзүҲжң¬пјҢеҸҜд»ҘеүҚеҫҖе®ҳж–№жәҗдёӢиҪҪеҜ№еә”зүҲжң¬з„¶еҗҺжҢүз…§еҜ№еә”ж–№ејҸзј–иҜ‘
wget http://www.leptonica.org/source/leptonica-1.74.4.tar.gz
tar -zxvf leptonica-1.74.4.tar.gz
cd leptonica-1.74.4/
./configure
make && make install
3. е®үиЈ…tesseract
е…¶д»–еҗ„зүҲжң¬еҸҜд»ҘеңЁиҝҷйҮҢдёӢиҪҪ并иҮӘиЎҢзј–иҜ‘пјҢд№ҹжҸҗдҫӣзӣҙжҺҘдҪҝз”Ёзҡ„ж–Ү件гҖӮ
yum install tesseract
4. йӘҢиҜҒе®үиЈ…
tesseract --version
5. иҜӯиЁҖеҢ…дёӢиҪҪ
еүҚеҫҖtesseract-ocr/tessdataдёӢиҪҪзӣёеә”зҡ„иҜӯиЁҖеҢ…,然еҗҺе°Ҷд№Ӣ移еҠЁеҲ°tessdataзӣ®еҪ•дёӢпјҢеҸҜд»Ҙз”Ёwhereis tesseractжҹҘзңӢдёҖдёӢе…·дҪ“зҡ„зӣ®еҪ•пјҢжҲ‘зҡ„жҳҜ/usr/share/tesseract/tessdata/mv *.traineddata /usr/local/share/tessdata/
6. жҹҘзңӢзӣ®еүҚе·ІдёӢиҪҪзҡ„иҜӯиЁҖ
tesseract --list-langs
дҪҝз”Ё
# tesseract
Usage:
tesseract --help | --help-psm | --help-oem | --version
tesseract --list-langs [--tessdata-dir PATH]
tesseract --print-parameters [options...] [configfile...]
tesseract imagename|stdin outputbase|stdout [options...] [configfile...]
OCR options:
--tessdata-dir PATH Specify the location of tessdata path.
--user-words PATH Specify the location of user words file.
--user-patterns PATH Specify the location of user patterns file.
-l LANG[+LANG] Specify language(s) used for OCR.
-c VAR=VALUE Set value for config variables.
Multiple -c arguments are allowed.
--psm NUM Specify page segmentation mode.
--oem NUM Specify OCR Engine mode.
NOTE: These options must occur before any configfile.
иҜӯжі•
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
imagenameпјҡеӣҫзүҮеҗҚеӯ—
outputbaseпјҡжҢҮе®ҡиҫ“еҮәпјҢеҰӮжһңеёҢжңӣзӣҙжҺҘиҫ“еҮәиҖҢдёҚжҳҜдҝқеӯҳеҲ°ж–Ү件пјҢйӮЈд№Ҳе°ұдҪҝз”Ё stdoutпјҢеҗҰеҲҷиҝҷдёӘеҸӮж•°е°ҶдјҡдҪңдёәдҝқеӯҳз»“жһңзҡ„ж–Ү件зҡ„еүҚзјҖ
-lжҢҮе®ҡиҜӯиЁҖж–Ү件пјҢй»ҳи®ӨдҪҝз”ЁиӢұж–Ү
tesseract --print-parametersпјҡжҹҘзңӢжӣҙеӨҡеҸӮж•°дҝЎжҒҜ
дҪҝз”Ё-cжҢҮе®ҡеҚ•йЎ№еҸӮж•°зҡ„еҖјжҲ–иҖ…е°Ҷй…ҚзҪ®еҶҷе…Ҙй…ҚзҪ®ж–Ү件ж”ҫеңЁе‘Ҫд»ӨжңҖеҗҺ(ж”ҜжҢҒеӨҡдёӘй…ҚзҪ®ж–Ү件)
psm иҜҶеҲ«еӣҫеғҸзҡ„ж–№ејҸ
0пјҡе®ҡеҗ‘и„ҡжң¬зӣ‘жөӢпјҲOSDпјү
1пјҡ дҪҝз”ЁOSDиҮӘеҠЁеҲҶйЎө
2 пјҡиҮӘеҠЁеҲҶйЎөпјҢдҪҶжҳҜдёҚдҪҝз”ЁOSDжҲ–OCRпјҲOptical Character RecognitionпјҢе…үеӯҰеӯ—з¬ҰиҜҶеҲ«пјү
3 пјҡе…ЁиҮӘеҠЁеҲҶйЎөпјҢдҪҶжҳҜжІЎжңүдҪҝз”ЁOSDпјҲй»ҳи®Өпјү
4 пјҡеҒҮи®ҫеҸҜеҸҳеӨ§е°Ҹзҡ„дёҖдёӘж–Үжң¬еҲ—гҖӮ
5 пјҡеҒҮи®ҫеһӮзӣҙеҜ№йҪҗж–Үжң¬зҡ„еҚ•дёӘз»ҹдёҖеқ—гҖӮ
6 пјҡеҒҮи®ҫдёҖдёӘз»ҹдёҖзҡ„ж–Үжң¬еқ—гҖӮ
7 пјҡе°ҶеӣҫеғҸи§ҶдёәеҚ•дёӘж–Үжң¬иЎҢгҖӮ
8 пјҡе°ҶеӣҫеғҸи§ҶдёәеҚ•дёӘиҜҚгҖӮ
9 пјҡе°ҶеӣҫеғҸи§ҶдёәеңҶдёӯзҡ„еҚ•дёӘиҜҚгҖӮ
10 пјҡе°ҶеӣҫеғҸи§ҶдёәеҚ•дёӘеӯ—з¬ҰгҖӮ
pythonдёӯдҪҝз”Ё
Tesseractе®үиЈ…е®ҢжҲҗеҗҺеҸҜд»ҘеҫҲж–№дҫҝзҡ„иў«Pythonи°ғз”ЁпјҢдҪҶжҳҜйңҖиҰҒpillowе’Ңpytesseractзҡ„ж”ҜжҢҒгҖӮ
pythonдёӯиҪ¬жҚў
image_to_data(image, lang=None, config='', nice=0, output_type=Output.STRING)
image ObjectпјҢз”ұTesseractеӨ„зҗҶзҡ„еӣҫеғҸзҡ„PIL Image/NumPyж•°з»„
lang StringпјҢTesseractиҜӯиЁҖд»Јз Ғеӯ—з¬ҰдёІ
config StringпјҢд»»дҪ•е…¶д»–й…ҚзҪ®еӯ—з¬ҰдёІпјҢдҫӢеҰӮпјҡconfig='--psm 6'
иҜӯиЁҖж–Ү件еҸҜд»ҘеҸ еҠ пјҢз”ЁвҖң+вҖқйҡ”ејҖ
жҲ‘们д№ҹеҸҜд»ҘеңЁиҝҷйҮҢиҝӣиЎҢtessdataи·Ҝеҫ„зҡ„и®ҫзҪ®пјҢи·ҹеңЁconfigйҮҢйқўеҚіеҸҜ
жӣҙеӨҡй…ҚзҪ®еҢ…жӢ¬configе’ҢpsmйғҪе’Ңtesseractзұ»дјј
е®һдҫӢпјҡ
жөҒзЁӢпјҡ жү“ејҖеӣҫзүҮпјҢй…ҚзҪ®пјҢиҪ¬жҚўпјҢеҸҜд»ҘйҖҡиҝҮImageзҡ„openжҲ–иҖ…cv2зҡ„imreadжү“ејҖеӣҫзүҮпјҢд№ӢеҗҺеҜ№еӣҫзүҮиҝӣиЎҢеҜ№жҜ”еәҰеўһејәпјҢйҷҚеҷӘзӯүеӨ„зҗҶпјҢж•ҲжһңдјҡеҘҪдёҖдәӣгҖӮ
from PIL import Image
import pytesseract
class Languages:
CHS = 'chi_sim'
ENG = 'eng'
def img_to_str(image_path, lang=Languages.ENG):
return pytesseract.image_to_string(Image.open(image_path), lang)
print(img_to_str('pic/numu.png', lang=Languages.ENG))
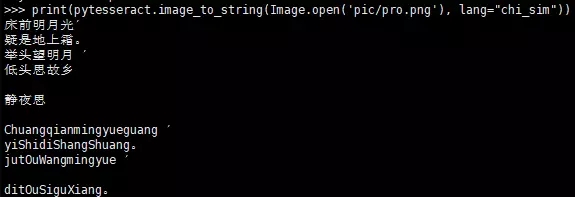
print(img_to_str('pic/pro.png', lang=Languages.ENG))
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ





