这篇文章主要介绍了使用Python标准库进行性能测试的方法,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
Profile 和 cProfile
在 Python 标准库里面有两个模块可以用来做性能测试。
1. 一个是 Profile,它是一个纯 Python 的实现,所以会慢一些,如果你需要对模块进行拓展,那么这个模块比较合适。
2. 第二个是 cProfile,从名字就可以看出这是一个 C 语言的实现版,官方推荐在大多数情况下使用。
这两者的接口和数据的输出格式是完全一样的,你可以在这两者之间自由的切换,所以下面我们仅以 cProfile 为例进行介绍。
使用 cProfile 进行性能测试
在 cProfile 中,进行性能测试十分简单,只需调用 run 方法,并将需要测试的函数及参数传递给它即可,下面我们对fib(n) 进行性能测试。
import cProfile
def fib(n):
if n == 0:
return 0
if n == 1:
return 1
return fib(n-1) + fib(n-2)
if __name__ == '__main__':
cProfile.run('fib(30)')性能测试的结果如下图
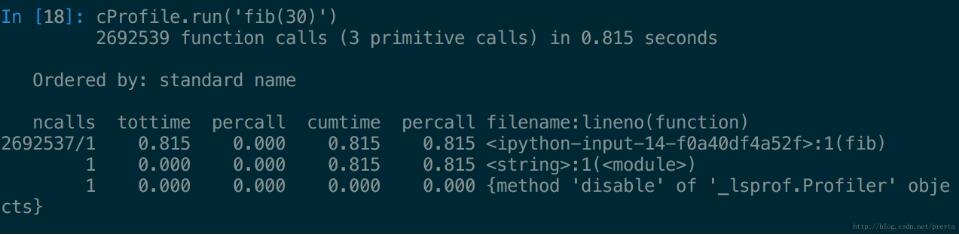
可以看到一共进行了 2692539 次函数调用,共耗时 0.815 秒。下面每一行对应于一个函数的调用情况,其中:
1. ncalls, 函数总共调用次数;
2. tottime, 这个函数调用总共花费时间;
3. percall, 每个调用的平均花费时间;
4. cumtime, 总共累计花费时间;
5. percall, 每个调用的平均累计时间;
6. filename:lineno(function), 对应函数信息。
所以从图中可以明显看到几乎的耗时都在fib上,而且函数调用数过多,这主要是因为函数是递归调用的,并且会产生很多冗余分支,所以程序需要进行优化。有两种方法进行改进,一是缓存fib(n)的信息,不需要每次都进行计算;二是将程序改为迭代式。
而对函数值进行缓存在 Python 3 里有一个简单的装饰器叫做lru_cache,可以自动的帮你缓存函数的值,而不需要自己手动存储。
import functools @functools.lru_cache(maxsize=None) def fib(n): if n == 0: return 0 if n == 1: return 1 return fib(n-1) + fib(n-2)
运行结果如下:
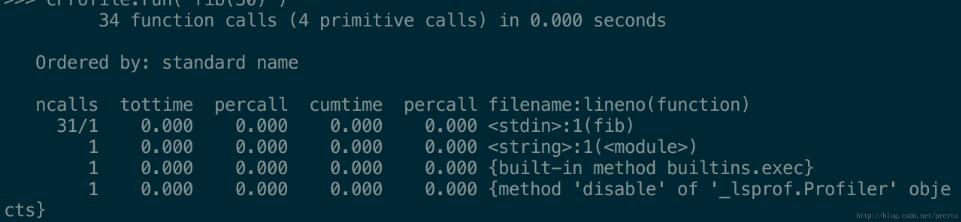
可以看到,fib 函数只调用了 31 次,几乎所有额外的调用都命中了缓存,远远小于前面的调用次数,运行时间也得到了相当明显的提升。同时使用下面的迭代版程序也运行得非常快,这里就不再展开。
def fib(n): prev, cur = 0, 1 if n == 0: return prev if n == 1: return cur count = 1 while count < n: count += 1 prev, cur = cur, prev + cur return cur
除了前面提到的 run 方法外,还有一个叫做 runctx 的方法,允许提供一些上下文参数。例如前面的 cProfile.run('fib(30)') 可以改为cProfile.runctx('fib', globals(), {'n':30})最后的运行结果是相同的。
最后,除了直接打印到命令行的方式,run 和 runctx 可以通过第二个参数传递文件名的方式将输出结果写入文件。
使用 pstats 对显示进行控制
cProfile 虽然可以对程序进行简单的性能测试,但是当程序过大,调用函数很多的时候,就需要一些对测试结果进行过滤和排序的工具了,而 pstats 就是这样的一个工具。
# fib_profile.py
import cProfile
import pstats
for i in range(5):
cProfile.run('fib(1000)', 'fib_profile_{}'.format(i))
stats = pstats.Stats('fib_profile_0')
for i in range(1, 5):
stats.add('fib_profile_{}'.format(i))
stats.strip_dirs()
stats.sort_stats('cumulative')
stats.print_stats('fib')上面的程序首先写入了多个测试结果,然后初始化了 stats,可以通过 stats 的 add 方法添加新的文件,pstats 会自动的将结果聚合起来;然后 strip_dirs 将会移除文件名前面的路径,只保留文件名;sort_stats 是对输出结果进行排序,也就是在前面所说的那几行里进行选择(具体的可参阅官方文档);最后的 print_stats 对结果进行输出,在这面可以对行进行过滤,比如上面的程序就只输出了包含 fib 的行;实际输出结果如下。
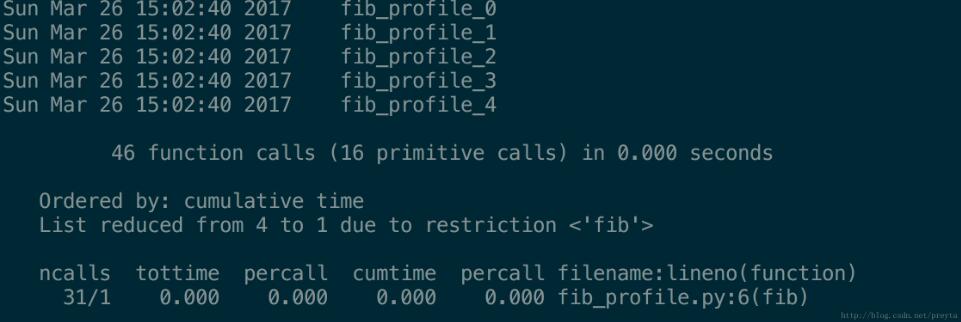
感谢你能够认真阅读完这篇文章,希望小编分享的“使用Python标准库进行性能测试的方法”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





