前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员。
在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息。
数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页}
以上就是我们需要的信息。
爬虫前的分析:
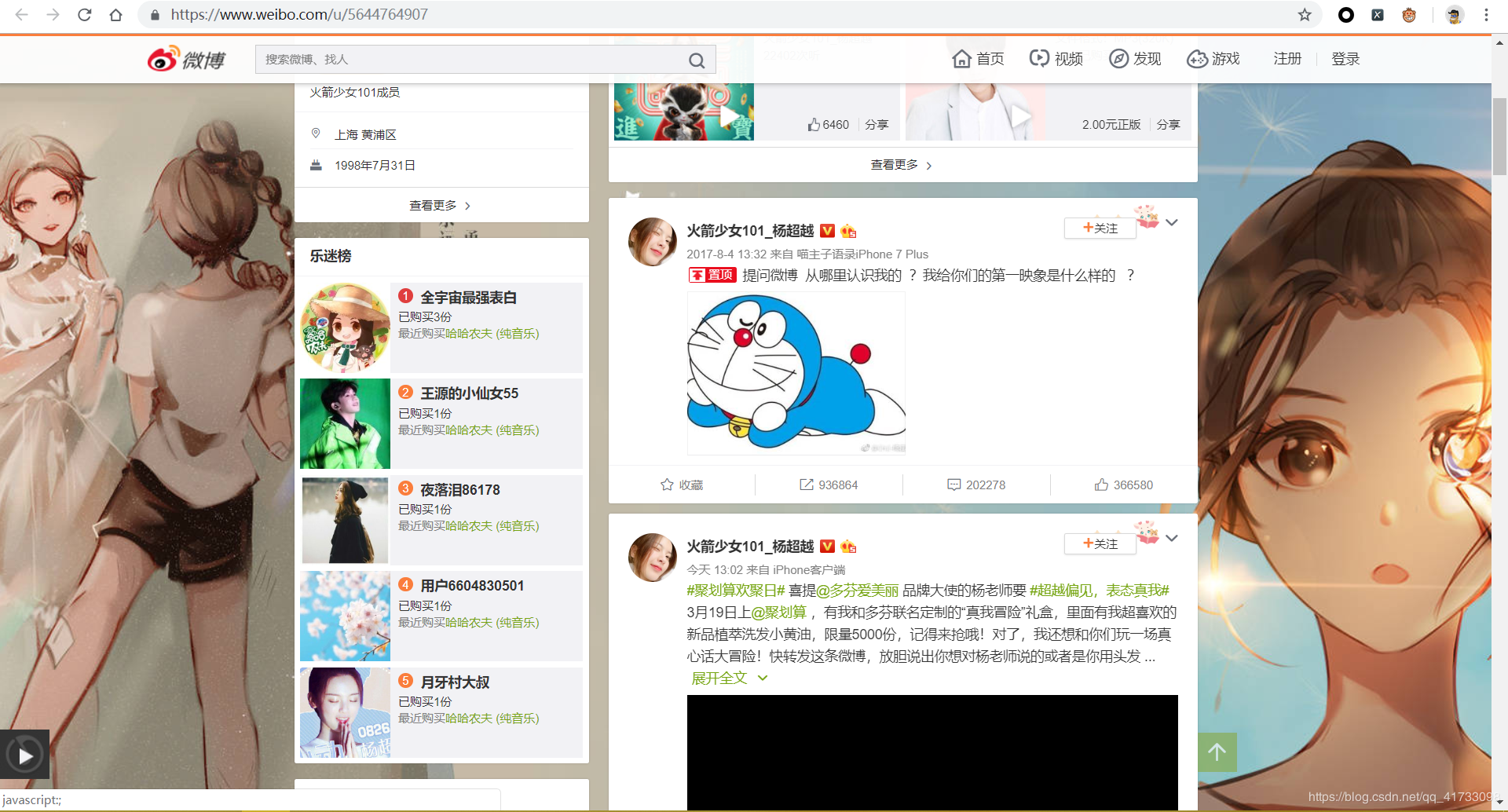
以上是杨超越的微博主页,这是我们首先需要获取到的内容。
因为我们需要等到这个主页内这些微博详情页 的链接,但是我们向下刷新,会发现微博的主页信息是ajax动态加载出来的,
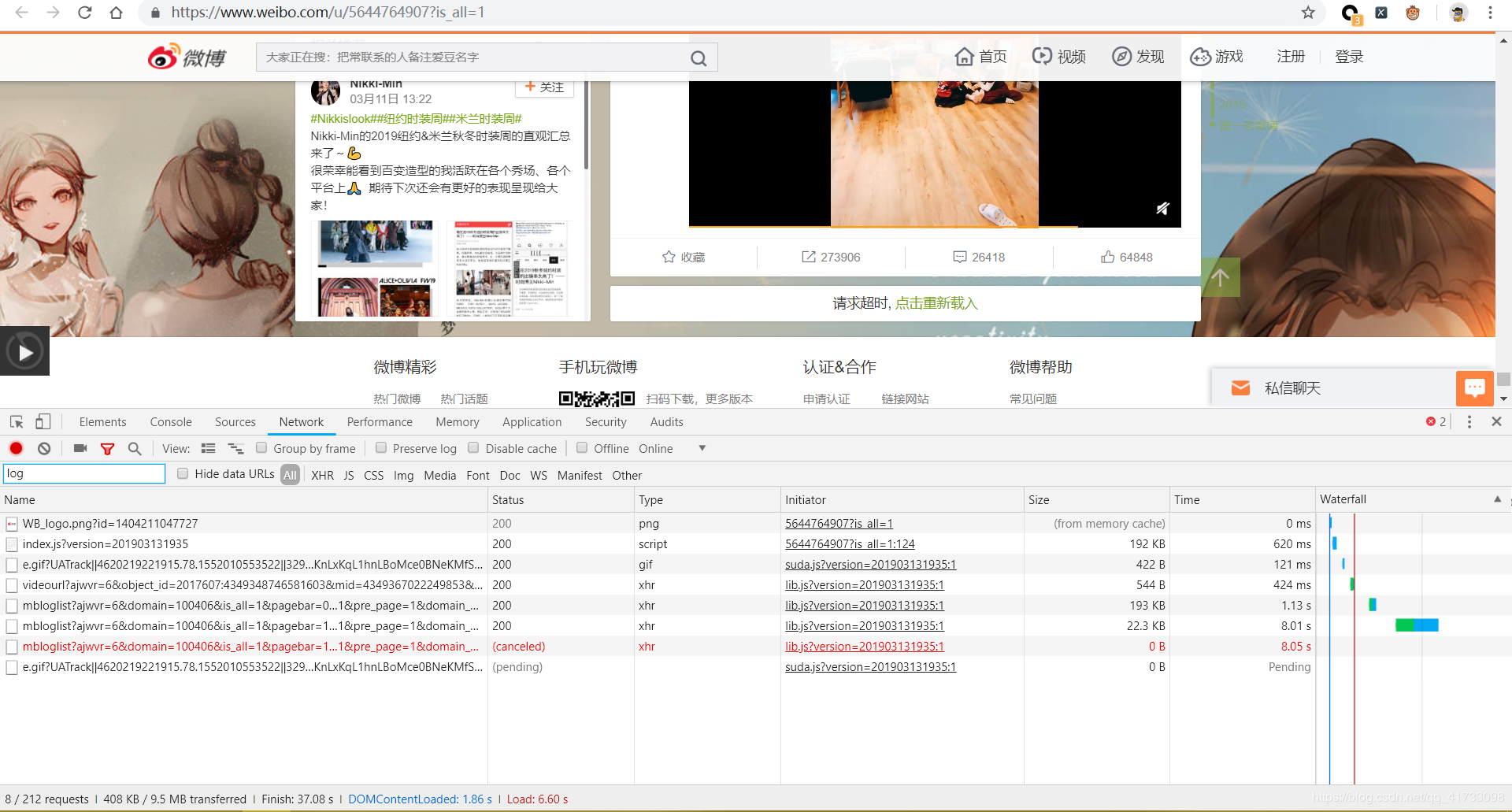
这张图片就是我们向下刷新获取到 的新的链接,这个就是我们需要获取到的信息页面信息。
接下来 就是获取详情页面的信息,详情页中含有评论的相关信息,通过向下刷新,我们也会发现,相关的评论信息也是通过ajax加载出来的 ,
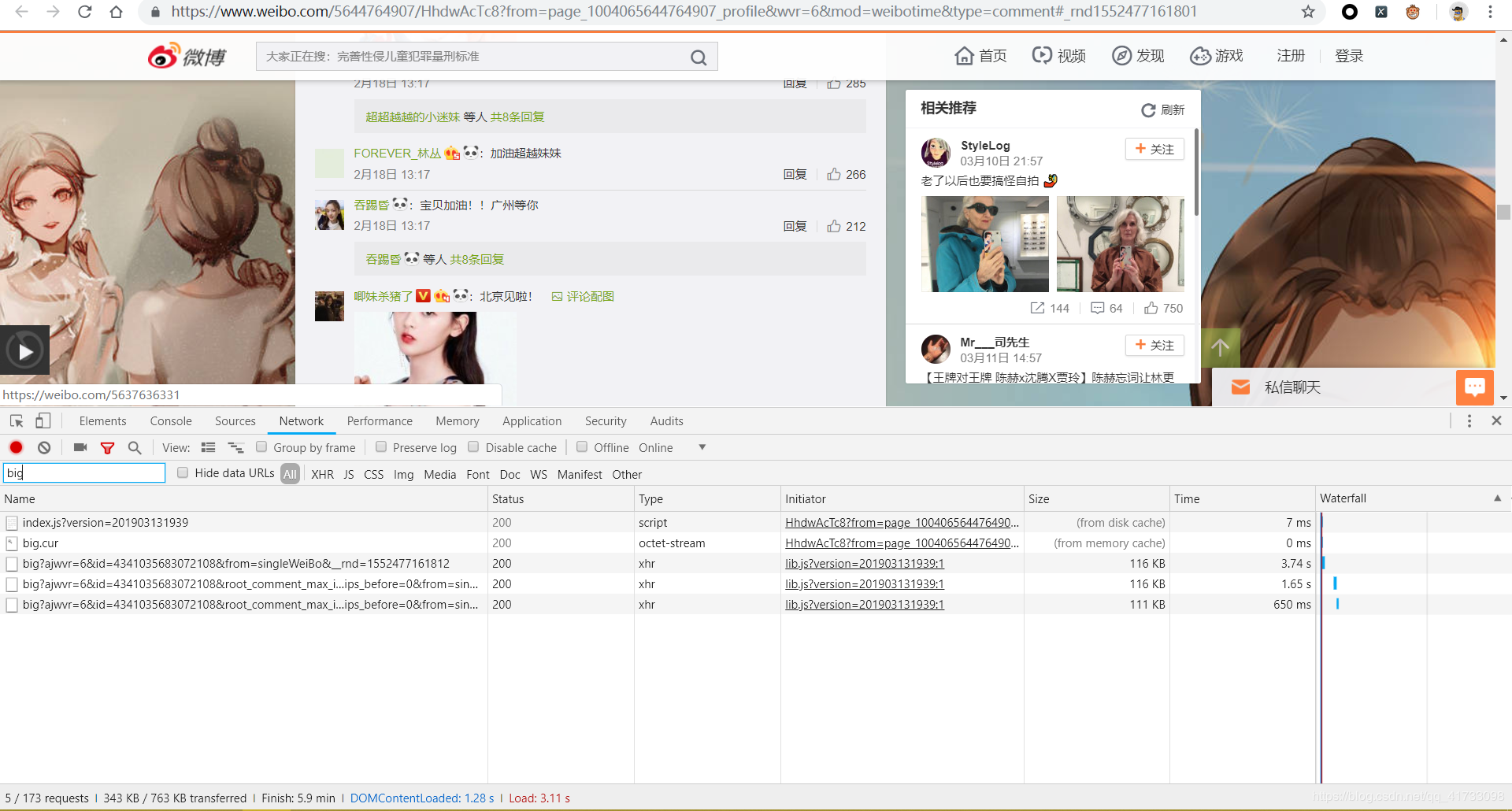
ok,以上就是我们针对整个流程大致的一个分析过程。
具体操作流程:
我们首相将主页获取完成以后,我们就会发现,其中 的内容带有相关的反爬措施,获取到的源码中的信息含有很多的转义符“\”,并且其中的相关“<”和“>”是通过html的语言直接编写的,这样会导致我们的页面解析出现一定的问题,我们可以用replace方法直接将这些转义符全部去掉,然后我们就可以对这个页面进行正则处理,同时我也尝试过用其他的解析方法,但是其中遇到了很多 的问题,所以我就不过多的介绍了。
当我们获取到了每一篇微博的链接以后,还需要获取一个很关键的值 id ,这个值有什么用呢,其主要的作用就是在评论页面的ajax页面的拼接地址上需要使用到。接下来就是需要寻找出我们找到的这两个ajax的url有什么特点或者是规律:
当我们从这些ajax中找到规律以后,不难发现,这个爬虫差不多大功告成了。
下面我就展示一下我的代码:
注意:请在headers中添加自己的cookie
# -*- coding: utf-8 -*-
# Created : 2018/8/26 18:33
# author :GuoLi
import requests
import json
import time
from lxml import etree
import html
import re
from bs4 import BeautifulSoup
class Weibospider:
def __init__(self):
# 获取首页的相关信息:
self.start_url = 'https://weibo.com/u/5644764907?page=1&is_all=1'
self.headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"cache-control": "max-age=0",
"cookie": 使用自己本机的cookie,
"referer": "https://www.weibo.com/u/5644764907?topnav=1&wvr=6&topsug=1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36",
}
self.proxy = {
'HTTP': 'HTTP://180.125.70.78:9999',
'HTTP': 'HTTP://117.90.4.230:9999',
'HTTP': 'HTTP://111.77.196.229:9999',
'HTTP': 'HTTP://111.177.183.57:9999',
'HTTP': 'HTTP://123.55.98.146:9999',
}
def parse_home_url(self, url): # 处理解析首页面的详细信息(不包括两个通过ajax获取到的页面)
res = requests.get(url, headers=self.headers)
response = res.content.decode().replace("\\", "")
# every_url = re.compile('target="_blank" href="(/\d+/\w+\?from=\w+&wvr=6&mod=weibotime)" rel="external nofollow" ', re.S).findall(response)
every_id = re.compile('name=(\d+)', re.S).findall(response) # 获取次级页面需要的id
home_url = []
for id in every_id:
base_url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id={}&from=singleWeiBo'
url = base_url.format(id)
home_url.append(url)
return home_url
def parse_comment_info(self, url): # 爬取直接发表评论的人的相关信息(name,info,time,info_url)
res = requests.get(url, headers=self.headers)
response = res.json()
count = response['data']['count']
html = etree.HTML(response['data']['html'])
name = html.xpath("//div[@class='list_li S_line1 clearfix']/div[@class='WB_face W_fl']/a/img/@alt") # 评论人的姓名
info = html.xpath("//div[@node-type='replywrap']/div[@class='WB_text']/text()") # 评论信息
info = "".join(info).replace(" ", "").split("\n")
info.pop(0)
comment_time = html.xpath("//div[@class='WB_from S_txt2']/text()") # 评论时间
name_url = html.xpath("//div[@class='WB_face W_fl']/a/@href") # 评论人的url
name_url = ["https:" + i for i in name_url]
comment_info_list = []
for i in range(len(name)):
item = {}
item["name"] = name[i] # 存储评论人的网名
item["comment_info"] = info[i] # 存储评论的信息
item["comment_time"] = comment_time[i] # 存储评论时间
item["comment_url"] = name_url[i] # 存储评论人的相关主页
comment_info_list.append(item)
return count, comment_info_list
def write_file(self, path_name, content_list):
for content in content_list:
with open(path_name, "a", encoding="UTF-8") as f:
f.write(json.dumps(content, ensure_ascii=False))
f.write("\n")
def run(self):
start_url = 'https://weibo.com/u/5644764907?page={}&is_all=1'
start_ajax_url1 = 'https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100406&is_all=1&page={0}&pagebar=0&pl_name=Pl_Official_MyProfileFeed__20&id=1004065644764907&script_uri=/u/5644764907&pre_page={0}'
start_ajax_url2 = 'https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100406&is_all=1&page={0}&pagebar=1&pl_name=Pl_Official_MyProfileFeed__20&id=1004065644764907&script_uri=/u/5644764907&pre_page={0}'
for i in range(12): # 微博共有12页
home_url = self.parse_home_url(start_url.format(i + 1)) # 获取每一页的微博
ajax_url1 = self.parse_home_url(start_ajax_url1.format(i + 1)) # ajax加载页面的微博
ajax_url2 = self.parse_home_url(start_ajax_url2.format(i + 1)) # ajax第二页加载页面的微博
all_url = home_url + ajax_url1 + ajax_url2
for j in range(len(all_url)):
print(all_url[j])
path_name = "第{}条微博相关评论.txt".format(i * 45 + j + 1)
all_count, comment_info_list = self.parse_comment_info(all_url[j])
self.write_file(path_name, comment_info_list)
for num in range(1, 10000):
if num * 15 < int(all_count) + 15:
comment_url = all_url[j] + "&page={}".format(num + 1)
print(comment_url)
try:
count, comment_info_list = self.parse_comment_info(comment_url)
self.write_file(path_name, comment_info_list)
except Exception as e:
print("Error:", e)
time.sleep(60)
count, comment_info_list = self.parse_comment_info(comment_url)
self.write_file(path_name, comment_info_list)
del count
time.sleep(0.2)
print("第{}微博信息获取完成!".format(i * 45 + j + 1))
if __name__ == '__main__':
weibo = Weibospider()
weibo.run()
以上所述是小编给大家介绍的python爬虫爬取微博评论详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对亿速云网站的支持!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



