小编给大家分享一下selenium+python如何实现688网站验证码图片的截取功能,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
1. 背景
•在1688网站爬取数据时,如果访问过于频繁,无论用户是否已经登录,就会弹出如下所示的验证码登录框。
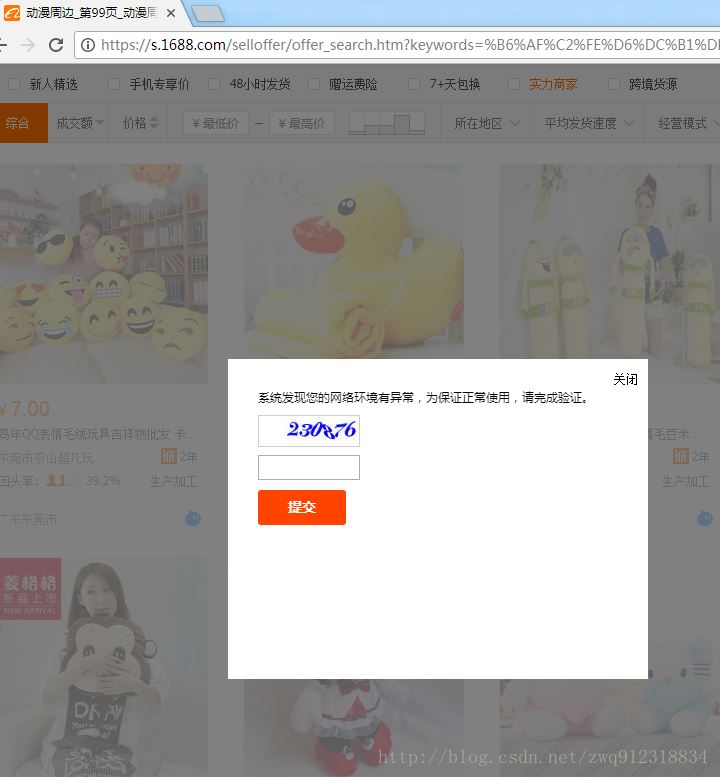
一般的验证码是类似于如下的元素(通过链接单独加载进页面,而不是嵌入图片元素):
<img id="J_CheckCodeImg1" width="100" height="30" onmousedown="return false;" src="//pin.aliyun.com/get_img?identity=sm-searchweb2&sessionid=9c3a51d81de07ddf1bfd9bbc70863b0f&type=default&t=1511315617645">
•一般来说,获取验证码图片有两种方式:
•第一,拿到上面验证码的图片链接:src=”//pin.aliyun.com/get_img?identity=sm-searchweb2&sessionid=9c3a51d81de07ddf1bfd9bbc70863b0f&type=default&t=1511315617645”,但是这种方式有时候行不通。因为有时候会发现当前的验证码和通过提取出来的url链接打开的验证码,内容是不一样的,其内容不断发生变化。
•第二,利用selenium先进行可视区域的截屏,然后定位验证码元素的位置以及大小,然后利用Image(PIL模块中)进行裁剪,得到验证码图片,然后送往验证码模块或者打码平台处理。
2. 环境
•python 3.6.1
•系统:win7
•IDE:pycharm
•安装过chrome浏览器
•配置好chromedriver
•selenium 3.7.0
3. 分析网页结构
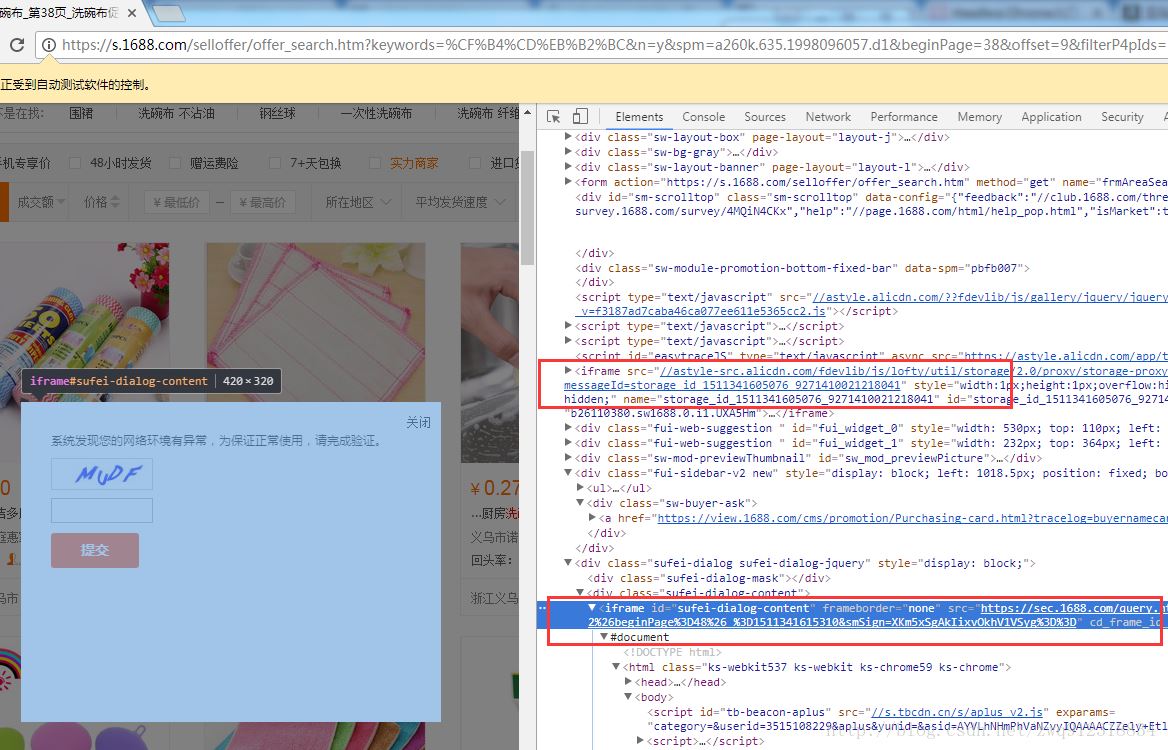
通过分析网页源代码,我们可以得出以下结论:
•这个验证码登录框是通过iframe嵌入到网页中的。
•页面中不止这一个iframe嵌套。
•这个验证码iframe有很明显的特征:id=”sufei-dialog-content”和src=”https://sec.1688.com/query.htm?……”
<iframe id="sufei-dialog-content" frameborder="none" src="https://sec.1688.com/query.htm?style=mini&smApp=searchweb2&smPolicy=searchweb2-RpcAsyncAll-anti_Spider-checkcode&smCharset=GBK&smTag=MTIxLjE1LjI2LjIzMywzNTE1MTA4MjI5LGFlNGE1ZGI1YTQ4NDQ3NTNiYzY5OTZlZmU1OWE3Njhm&smReturn=https%3A%2F%2Fs.1688.com%2Fselloffer%2Frpc_async_render.jsonp%3Fkeywords%3D%25CF%25B4%25CD%25EB%25B2%25BC%26startIndex%3D0%26n%3Dy%26pageSize%3D60%26rpcflag%3Dnew%26async%3Dtrue%26templateConfigName%3DmarketOfferresult%26enableAsync%3Dtrue%26qrwRedirectEnabled%3Dfalse%26filterP4pIds%3D1245873517%252C561786598916%252C559726907082%252C523166432402%252C557139543735%252C529784793813%252C543923733444%252C560590249743%26asyncCount%3D20%26_pageName_%3Dmarket%26offset%3D9%26uniqfield%3Dpic_tag_id%26leftP4PIds%3D%26callback%3DjQuery18305735956012709345_1511341604992%26beginPage%3D48%26_%3D1511341615310&smSign=XKm5xSgAkIixvOkhV1VSyg%3D%3D" cd_frame_id_="c4ae94ef2bea60f0b4729f319df59251"></iframe>
4. 代码
# 前提是,在程序启动时,对浏览器窗口大小进行了设置
from selenium import webdriver
import time
from PIL import Image
browser = webdriver.Chrome()
# 根据桌面分辨率来定,主要是为了抓到验证码的截屏,验证码需要出现在可视区域中
browser.set_window_size(960, 960)
# 处理验证码弹窗
def captchaHandler(browser, DamatuInstance):
iframeLst = browser.find_elements_by_tag_name('iframe')
print(f"captchaHandler: enter , iframeLst = {iframeLst}")
for iframe in iframeLst:
iframeID = iframe.get_attribute('id')
iframeSrc = iframe.get_attribute('src')
print(f"captchaHandler: iframeID = {iframeID}, iframeSrc = {iframeSrc}")
# 找到验证码登录iframe
if iframeID and iframeID.find('dialog') != -1:
if iframeSrc and iframeSrc.find(r'sec.1688.com') != -1:
# 拿到iframe的宽度和高度
frameWidth = iframe.size['width']
frameHeight = iframe.size['height']
# 代表验证码区域可见
# 某些情况下,会出现验证码框不弹出,而iframe还在的暂态
if frameWidth > 0 and frameHeight > 0:
print(f"验证码弹出, 进行处理, frameWidth = {frameWidth}, frameHeight = {frameHeight}")
# 截屏,在chrome中截取的是可视区域,而不是整个html页面
# 前提是当前project下已经创建了clawerImgs目录
browser.get_screenshot_as_file('clawerImgs/screenshot.png')
# 先拿到iframe在整个可视页面(也就是上面的截屏)中的相对位置,因为前面对页面的窗口大小进行了设置960 X 960
# location_once_scrolled_into_view 拿到的是相对于可视区域的坐标
# location 拿到的是相对整个html页面的坐标
frameX = int(iframe.location_once_scrolled_into_view['x'])
frameY = int(iframe.location_once_scrolled_into_view['y'])
print(f"captchaHandler: frameX = {frameX}, frameY = {frameY}, frameWidth = {frameWidth}, frameHeight = {frameHeight}")
# 获取指定元素位置,先拿iframe元素的图片
left = frameX
top = frameY
right = frameX + frameWidth
bottom = frameY + frameHeight
# 通过Image处理图像,截取frame的图片 ———— 无意义,只是做经验总结
imgFrame = Image.open('clawerImgs/screenshot.png')
imgFrame = imgFrame.crop((left, top, right, bottom)) # 裁剪
imgFrame.save('clawerImgs/iframe.png')
# 切换到验证码弹出框的frame,不然无法获取到验证码元素,因为验证码元素是在iframe中
browser.switch_to.frame(iframe)
# ------获取验证码图片,第一种方法:在frame区域截取
# 获取指定元素位置
captchaElem = browser.find_element_by_xpath("//img[contains(@id, 'CheckCodeImg')]")
# 因为验证码在frame中没有缩放,直接取验证码图片的绝对坐标
# 这个坐标是相对于它所属的frame的,而不是整个可视区域
captchaX = int(captchaElem.location['x'])
captchaY = int(captchaElem.location['y'])
# 取验证码的宽度和高度
captchaWidth = captchaElem.size['width']
captchaHeight = captchaElem.size['height']
captchaRight = captchaX + captchaWidth
captchaBottom = captchaY + captchaHeight
print(f"captchaHandler: 1 captchaX = {captchaX}, captchaY = {captchaY}, captchaWidth = {captchaWidth}, captchaHeight = {captchaHeight}")
# 通过Image处理图像,第一种方法:在frame区域截取
imgObject = Image.open('clawerImgs/iframe.png')
imgCaptcha = imgObject.crop((captchaX, captchaY, captchaRight, captchaBottom)) # 裁剪
imgCaptcha.save('clawerImgs/captcha1.png')
# ------获取验证码图片,第二种方法:在整个可视区域截取。 就要加上这个iframe的便宜量
captchaElem = browser.find_element_by_xpath("//img[contains(@id, 'CheckCodeImg')]")
captchaX = int(captchaElem.location['x']) + frameX
captchaY = int(captchaElem.location['y']) + frameY
captchaWidth = captchaElem.size['width']
captchaHeight = captchaElem.size['height']
captchaRight = captchaX + captchaWidth
captchaBottom = captchaY + captchaHeight
print(f"captchaHandler: 2 captchaX = {captchaX}, captchaY = {captchaY}, captchaWidth = {captchaWidth}, captchaHeight = {captchaHeight}")
# 通过Image处理图像,第二种方法:在整个可视区域截取
imgObject = Image.open('clawerImgs/screenshot.png')
imgCaptcha = imgObject.crop((captchaX, captchaY, captchaRight, captchaBottom)) # 裁剪
imgCaptcha.save('clawerImgs/captcha2.png')5. 结果展示
•整个可视区域:screenshot.png

•验证码登录框iframe区域:iframe.png

•相对于iframe截取的验证码图片:captcha1.png

•相对于整个可视区域截取的验证码图片:captcha2.png

6. 拓展
# 摘自https://www.cnblogs.com/my8100/p/7225408.html
chrome
default:
location 不滚动,直接返回相对整个html的坐标 {'x': 15.0, 'y': 129.0}
location_once_scrolled_into_view 返回相对可视区域的坐标(改变浏览器高度,可以观察到底部元素底部对齐后y的变化)
顶部/底部元素 完全可见不滚动,{u'x': 15, u'y': 60}
顶部元素部分可见或完全不可见都会滚动到 顶部对齐 {u'x': 15, u'y': 0} account-wall
底部元素部分可见或完全不可见都会滚动到 底部对齐 {u'x': 15, u'y': 594} theme-list
frame:
location 不滚动,直接返回相对frame即当前相应内层html的坐标{'x': 255.0, 'y': 167.0} captcha_frame 的 lc-refresh
location_once_scrolled_into_view 返回相对可视区域的坐标
完全可见不滚动{u'x': 273, u'y': 105}
部分可见或完全不可见滚动到 顶部对齐 {u'x': 273, u'y': 0}
firefox
default:
顶部元素 底部元素
location 不滚动,直接返回相对整个html的坐标 {'x': 15.0, 'y': 130.0} {'x': 15.0, 'y': 707.0}
location_once_scrolled_into_view 返回相对可视区域的坐标(y=1足以说明)
可见不可见 都滚动到顶部对齐 {'x': 15.0, 'y': 1.0} {'x': 15.0, 'y': 1.0}
如果下拉条直到底部,底部元素仍然无法顶部对齐 {'x': 15.0, 'y': 82.0}
frame:
location 不滚动,都是相对frame即当前相应html的坐标{'x': 255.0, 'y': 166.0}
location_once_scrolled_into_view 可见不可见都会滚动到顶部对齐,('y'依旧是166.0)
结果也是相对frame即当前相应html的坐标{'x': 255.0, 'y': 166.0}
# 总结
location
始终不滚动,返回相对整个html或者对应frame的坐标
location_once_scrolled_into_view
chrome完全可见不滚动,firefox始终会滚动;而且chrome底部元素会底部对齐,其余情况两者都是顶部对齐。
一般返回相对可视区域坐标,但是firefox的frame依旧返回相对frame的坐标
# 摘自:https://zhuanlan.zhihu.com/p/25171554
selenium.webdriver 内置了截取当前页面的功能,其中:
a.WebDriver.Chrome自带的方法只能对当前窗口截屏,若是需要截取的窗口超过了一屏,就只能另辟蹊径了。
b.WebDriver.PhantomJS自带的方法支持对整个网页截屏。以上是“selenium+python如何实现688网站验证码图片的截取功能”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





