使用pandas怎么读取中文数据集?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
首先分享一下数据集:
编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是 3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是 4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是 5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是 6,青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是 7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是 8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是 9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否 10,青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否 11,浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否 12,浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否 13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否 14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否 15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.36,0.37,否 16,浅白,蜷缩,浊响,模糊,平坦,硬滑,0.593,0.042,否 17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否
然后利用pandas将它读进来:
import pandas
d = pandas.read_csv(r"d:\data.csv",sep=",")
print(d)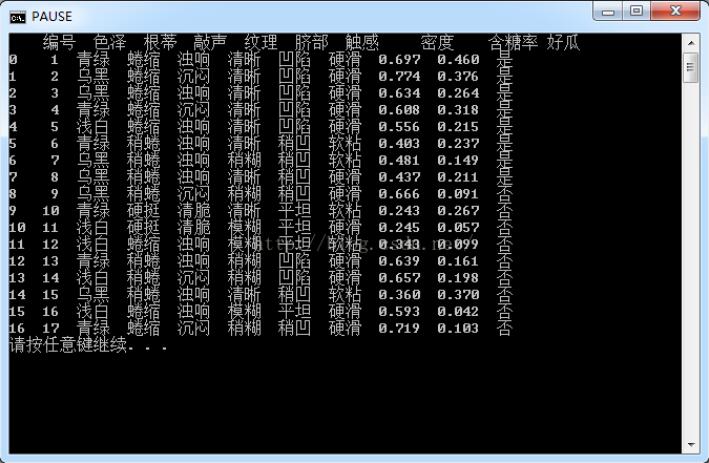
如果要选取某一行数据,可以使用head方法:
d.head(1)其中参数是行号。
也可以直接取某一列,如:
d['色泽']如果要取某一个数据则可以将两种方法结合使用:
d.head(1)['色泽']看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



