这篇文章将为大家详细讲解有关怎么在python中使用iterrows()函数遍历dataframe,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
假设我们有一个很简单的OTU表:
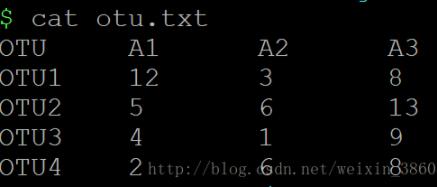
现在对这个表格进行遍历,一般写法为:
import pandas as pd
otu = pd.read_csv("otu.txt",sep="\t")
for index,row in otu.iterrows():
print index
print row这里的iterrows()返回值为元组,(index,row)
上面的代码里,for循环定义了两个变量,index,row,那么返回的元组,index=index,row=row.
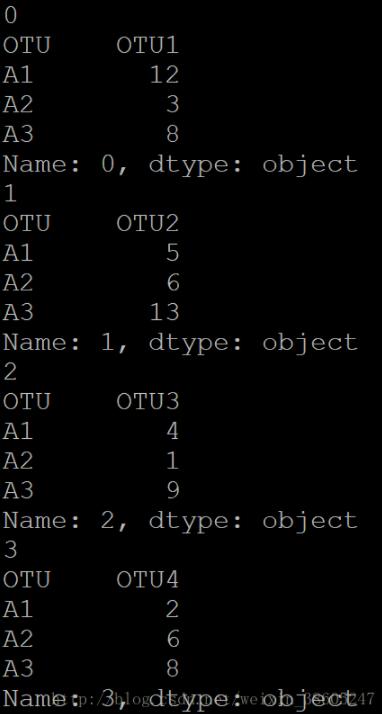
如果for循环时,只定义一个变量:
import pandas as pd
otu = pd.read_csv("otu.txt",sep="\t")
for row in otu.iterrows():
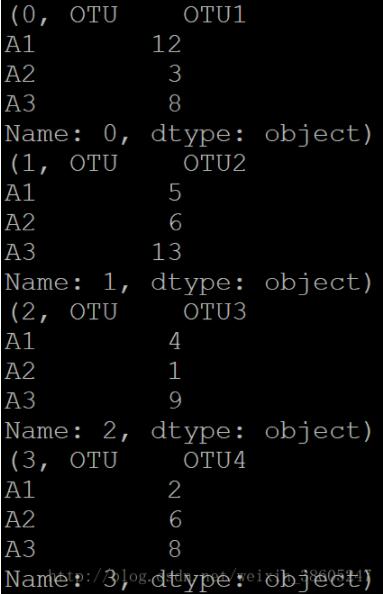
print row那么row就是整个元组。输出结果可以看出:
关于怎么在python中使用iterrows()函数遍历dataframe就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





