首先将一个字典转化为DataFrame,然后以DataFrame中的列进行频次统计。
代码如下:
import pandas as pd
a={'one':['A','A','B','C','C','A','B','B','A','A'],
'tao':['B','B','C','C','A','A','C','B','C','A'],
'three':['C','B','A','A','B','B','B','A','C','D']}
b=pd.DataFrame(a)
b.describe()
b是转换后DataFrame,显示如表格:
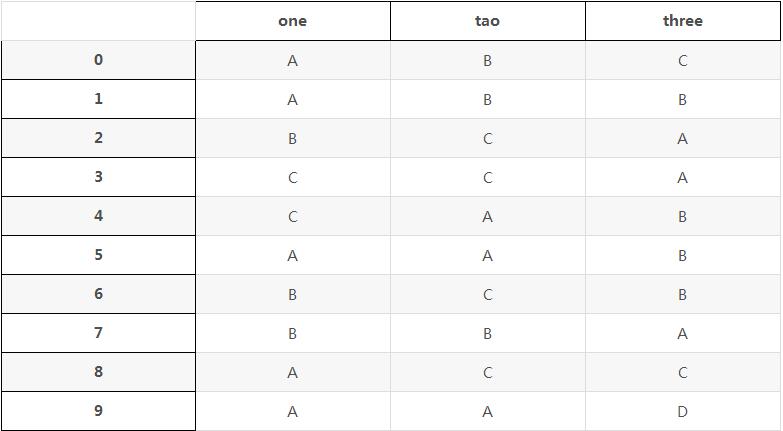
one tao three
0 A B C
1 A B B
2 B C A
3 C C A
4 C A B
5 A A B
6 B C B
7 B B A
8 A C C
9 A A D频次统计如表格:
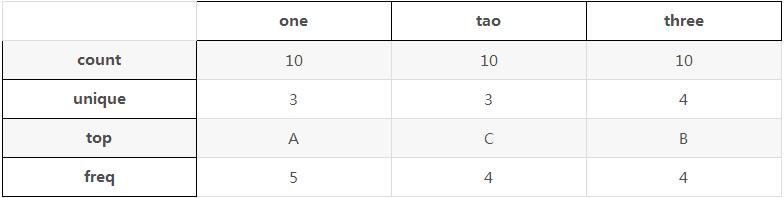
one tao three
count 10 10 10
unique 3 3 4
top A C B
freq 5 4 4其中count是总共变量数量,unique是每列有几个变量,top是频次最高的那个变量,freq是频次最高变量出现的频次。
以上这篇将字典转换为DataFrame并进行频次统计的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持亿速云。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



