1.梯度下降
1)什么是梯度下降?
因为梯度下降是一种思想,没有严格的定义,所以用一个比喻来解释什么是梯度下降。

简单来说,梯度下降就是从山顶找一条最短的路走到山脚最低的地方。但是因为选择方向的原因,我们找到的的最低点可能不是真正的最低点。如图所示,黑线标注的路线所指的方向并不是真正的地方。
既然是选择一个方向下山,那么这个方向怎么选?每次该怎么走?
先说选方向,在算法中是以随机方式给出的,这也是造成有时候走不到真正最低点的原因。
如果选定了方向,以后每走一步,都是选择最陡的方向,直到最低点。
总结起来就一句话:随机选择一个方向,然后每次迈步都选择最陡的方向,直到这个方向上能达到的最低点。
2)梯度下降是用来做什么的?
在机器学习算法中,有时候需要对原始的模型构建损失函数,然后通过优化算法对损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。而在求解机器学习参数的优化算法中,使用较多的就是基于梯度下降的优化算法(GradientDescent,GD)。
3)优缺点
优点:效率。在梯度下降法的求解过程中,只需求解损失函数的一阶导数,计算的代价比较小,可以在很多大规模数据集上应用
缺点:求解的是局部最优值,即由于方向选择的问题,得到的结果不一定是全局最优
步长选择,过小使得函数收敛速度慢,过大又容易找不到最优解。
2.梯度下降的变形形式
根据处理的训练数据的不同,主要有以下三种形式:
1)批量梯度下降法BGD(BatchGradientDescent):
针对的是整个数据集,通过对所有的样本的计算来求解梯度的方向。
优点:全局最优解;易于并行实现;
缺点:当样本数据很多时,计算量开销大,计算速度慢
2)小批量梯度下降法MBGD(mini-batchGradientDescent)
把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性
优点:减少了计算的开销量,降低了随机性
3)随机梯度下降法SGD(stochasticgradientdescent)
每个数据都计算算一下损失函数,然后求梯度更新参数。
优点:计算速度快
缺点:收敛性能不好
总结:SGD可以看作是MBGD的一个特例,及batch_size=1的情况。在深度学习及机器学习中,基本上都是使用的MBGD算法。
3.随机梯度下降
随机梯度下降(SGD)是一种简单但非常有效的方法,多用用于支持向量机、逻辑回归等凸损失函数下的线性分类器的学习。并且SGD已成功应用于文本分类和自然语言处理中经常遇到的大规模和稀疏机器学习问题。
SGD既可以用于分类计算,也可以用于回归计算。
1)分类
a)核心函数
sklearn.linear_model.SGDClassifier
b)主要参数(详细参数)
loss:指定损失函数。可选值:‘hinge'(默认),‘log',‘modified_huber',‘squared_hinge',‘perceptron',
"hinge":线性SVM
"log":逻辑回归
"modified_huber":平滑损失,基于异常值容忍和概率估计
"squared_hinge":带有二次惩罚的线性SVM
"perceptron":带有线性损失的感知器
alpha:惩罚系数
c)示例代码及详细解释
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import SGDClassifier
from sklearn.datasets.samples_generator import make_blobs
##生产数据
X, Y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.60)
##训练数据
clf = SGDClassifier(loss="hinge", alpha=0.01)
clf.fit(X, Y)
## 绘图
xx = np.linspace(-1, 5, 10)
yy = np.linspace(-1, 5, 10)
##生成二维矩阵
X1, X2 = np.meshgrid(xx, yy)
##生产一个与X1相同形状的矩阵
Z = np.empty(X1.shape)
##np.ndenumerate 返回矩阵中每个数的值及其索引
for (i, j), val in np.ndenumerate(X1):
x1 = val
x2 = X2[i, j]
p = clf.decision_function([[x1, x2]]) ##样本到超平面的距离
Z[i, j] = p[0]
levels = [-1.0, 0.0, 1.0]
linestyles = ['dashed', 'solid', 'dashed']
colors = 'k'
##绘制等高线:Z分别等于levels
plt.contour(X1, X2, Z, levels, colors=colors, linestyles=linestyles)
##画数据点
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired,
edgecolor='black', s=20)
plt.axis('tight')
plt.show()
d)结果图
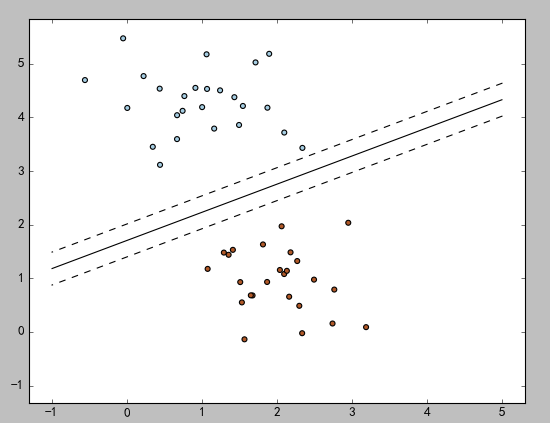
2)回归
SGDRegressor非常适合回归问题具有大量训练样本(>10000),对于其他的问题,建议使用的Ridge,Lasso或ElasticNet。
a)核心函数
sklearn.linear_model.SGDRegressor
b)主要参数(详细参数)
loss:指定损失函数。可选值‘squared_loss'(默认),‘huber',‘epsilon_insensitive',‘squared_epsilon_insensitive'
说明:此参数的翻译不是特别准确,请参考官方文档。
"squared_loss":采用普通最小二乘法
"huber":使用改进的普通最小二乘法,修正异常值
"epsilon_insensitive":忽略小于epsilon的错误
"squared_epsilon_insensitive":
alpha:惩罚系数
c)示例代码
因为使用方式与其他线性回归方式类似,所以这里只举个简单的例子:
import numpy as np from sklearn import linear_model n_samples, n_features = 10, 5 np.random.seed(0) y = np.random.randn(n_samples) X = np.random.randn(n_samples, n_features) clf = linear_model.SGDRegressor() clf.fit(X, y)
总结
以上就是本文关于Python语言描述随机梯度下降法的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





