前言:前一篇文章大概说了EM算法的整个理解以及一些相关的公式神马的,那些数学公式啥的看完真的是忘完了,那就来用代码记忆记忆吧!接下来将会对python版本的EM算法进行一些分析。
EM的python实现和解析
引入问题(双硬币问题)
假设有两枚硬币A、B,以相同的概率随机选择一个硬币,进行如下的抛硬币实验:共做5次实验,每次实验独立的抛十次,结果如图中a所示,例如某次实验产生了H、T、T、T、H、H、T、H、T、H,H代表正面朝上。
假设试验数据记录员可能是实习生,业务不一定熟悉,造成a和b两种情况
a表示实习生记录了详细的试验数据,我们可以观测到试验数据中每次选择的是A还是B
b表示实习生忘了记录每次试验选择的是A还是B,我们无法观测实验数据中选择的硬币是哪个
问在两种情况下分别如何估计两个硬币正面出现的概率?
以上的针对于b实习生的问题其实和三硬币问题类似,只是这里把三硬币中第一个抛硬币的选择换成了实习生的选择。
对于已知是A硬币还是B硬币抛出的结果的时候,可以直接采用概率的求法来进行求解。对于含有隐变量的情况,也就是不知道到底是A硬币抛出的结果还是B硬币抛出的结果的时候,就需要采用EM算法进行求解了。如下图:
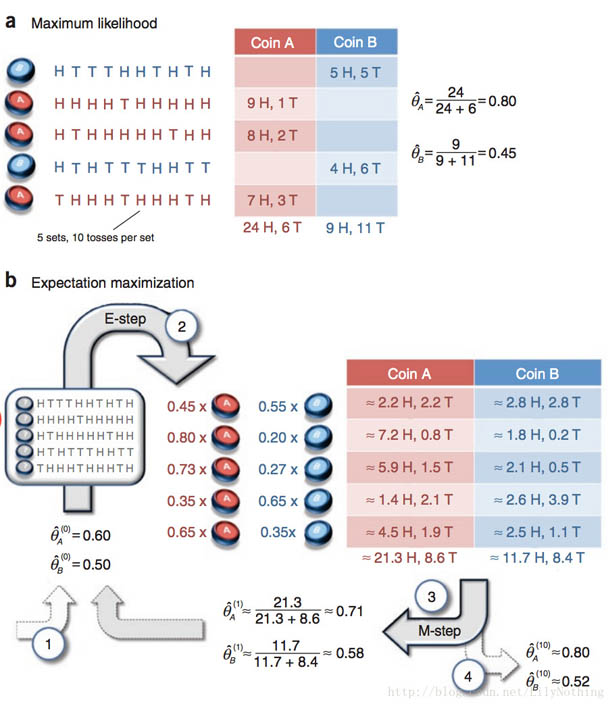
其中的EM算法的第一步就是初始化的过程,然后根据这个参数得出应该产生的结果。
构建观测数据集
针对这个问题,首先采集数据,用1表示H(正面),0表示T(反面):
#硬币投掷结果
observations = numpy.array([[1,0,0,0,1,1,0,1,0,1],
[1,1,1,1,0,1,1,1,0,1],
[1,0,1,1,1,1,1,0,1,1],
[1,0,1,0,0,0,1,1,0,0],
[0,1,1,1,0,1,1,1,0,1]])
第一步:参数的初始化
参数赋初值
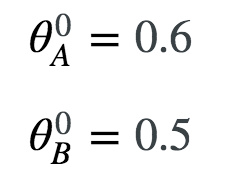
第一个迭代的E步
抛硬币是一个二项分布,可以用scipy中的binom来计算。对于第一行数据,正反面各有5次,所以:
#二项分布求解公式 contribution_A = scipy.stats.binom.pmf(num_heads,len_observation,theta_A) contribution_B = scipy.stats.binom.pmf(num_heads,len_observation,theta_B)
将两个概率正规化,得到数据来自硬币A,B的概率:
weight_A = contribution_A / (contribution_A + contribution_B) weight_B = contribution_B / (contribution_A + contribution_B)
这个值类似于三硬币模型中的μ,只不过多了一个下标,代表是第几行数据(数据集由5行构成)。同理,可以算出剩下的4行数据的μ。
有了μ,就可以估计数据中AB分别产生正反面的次数了。μ代表数据来自硬币A的概率的估计,将它乘上正面的总数,得到正面来自硬币A的总数,同理有反面,同理有B的正反面。
#更新在当前参数下A,B硬币产生的正反面次数 counts['A']['H'] += weight_A * num_heads counts['A']['T'] += weight_A * num_tails counts['B']['H'] += weight_B * num_heads counts['B']['T'] += weight_B * num_tails
第一个迭代的M步
当前模型参数下,AB分别产生正反面的次数估计出来了,就可以计算新的模型参数了:
new_theta_A = counts['A']['H']/(counts['A']['H'] + counts['A']['T']) new_theta_B = counts['B']['H']/(counts['B']['H'] + counts['B']['T'])
于是就可以整理一下,给出EM算法单个迭代的代码:
def em_single(priors,observations):
"""
EM算法的单次迭代
Arguments
------------
priors:[theta_A,theta_B]
observation:[m X n matrix]
Returns
---------------
new_priors:[new_theta_A,new_theta_B]
:param priors:
:param observations:
:return:
"""
counts = {'A': {'H': 0, 'T': 0}, 'B': {'H': 0, 'T': 0}}
theta_A = priors[0]
theta_B = priors[1]
#E step
for observation in observations:
len_observation = len(observation)
num_heads = observation.sum()
num_tails = len_observation-num_heads
#二项分布求解公式
contribution_A = scipy.stats.binom.pmf(num_heads,len_observation,theta_A)
contribution_B = scipy.stats.binom.pmf(num_heads,len_observation,theta_B)
weight_A = contribution_A / (contribution_A + contribution_B)
weight_B = contribution_B / (contribution_A + contribution_B)
#更新在当前参数下A,B硬币产生的正反面次数
counts['A']['H'] += weight_A * num_heads
counts['A']['T'] += weight_A * num_tails
counts['B']['H'] += weight_B * num_heads
counts['B']['T'] += weight_B * num_tails
# M step
new_theta_A = counts['A']['H'] / (counts['A']['H'] + counts['A']['T'])
new_theta_B = counts['B']['H'] / (counts['B']['H'] + counts['B']['T'])
return [new_theta_A,new_theta_B]
EM算法主循环
给定循环的两个终止条件:模型参数变化小于阈值;循环达到最大次数,就可以写出EM算法的主循环了
def em(observations,prior,tol = 1e-6,iterations=10000):
"""
EM算法
:param observations :观测数据
:param prior:模型初值
:param tol:迭代结束阈值
:param iterations:最大迭代次数
:return:局部最优的模型参数
"""
iteration = 0;
while iteration < iterations:
new_prior = em_single(prior,observations)
delta_change = numpy.abs(prior[0]-new_prior[0])
if delta_change < tol:
break
else:
prior = new_prior
iteration +=1
return [new_prior,iteration]
调用
给定数据集和初值,就可以调用EM算法了:
print em(observations,[0.6,0.5])
得到
[[0.72225028549925996, 0.55543808993848298], 36]
我们可以改变初值,试验初值对EM算法的影响。
print em(observations,[0.5,0.6])
结果:
[[0.55543727869042425, 0.72225099139214621], 37]
看来EM算法还是很健壮的。如果把初值设为相等会怎样?
print em(observations,[0.3,0.3])
输出:[[0.64000000000000001, 0.64000000000000001], 1]
显然,两个值相加不为1的时候就会破坏这个EM函数。
换一下初值:
print em(observations,[0.99999,0.00001])
输出:[[0.72225606292866507, 0.55543145006184214], 33]
EM算法对于参数的改变还是有一定的健壮性的。
以上是根据前人写的博客进行学习的~可以自己动手实现以下,对于python练习还是有作用的。希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





