很高兴今天给大家介绍微软2016群集的VM弹性和存储容错技术,在老王看来,WSFC 2016里面针对于群集运作,VM弹性是一项很重要的改变,和滚动升级一样,是一种颠覆式的思维。
简单来说,在大家的认知里,群集就是应该当检测到节点不可用之后,快速进行failover,把应用继续转移到其它节点上运行,对吧,相信大家都认同这一点。
2012R2里面默认相同子网和跨子网都是每隔一秒全网检测一次,五次检测失效,即判定该节点不可用,RCM开始根据群集数据库内容,故障转移角色到其它节点运作,检测时间和检测失败次数操作,可以改,如果您的环境存在网络不稳定的情况,严格的监测会导致节点频繁故障转移,您也改成松散一些的1秒检测一次,20次检测失败,再执行故障转移
但是这个阀值不易修改太久,原因,一个是因为这个值是针对整个群集级别,如果群集上面有很多应用则所有应用都将受到这个影响,其二是如果检测次数时间过长,会导致宕机时间很久才被发现,因此2012R2及之前,微软建议,最长设置为20次检测失败就故障转移,不建议超过这个数值
但归根到底,我们修改监测阀值,还是为了解决网络不稳定的问题,以及用户特定的需求,例如,如果客户网络不稳定,检测会存在瞬时中断,而且也没办法更改,那么就可以把监测阀值设置宽松一些,如果客户环境网络很稳定,需要很严格的检测来保证SLA,也可以把检测阀值设置严格一些。
这是2012R2时代的解决方案,到了2016,微软认为,真正的故障转移情况已经并不多见,反而是瞬时故障的情况更常见,例如节点短暂无法进行网络通信,或短暂无法和存储连接,之后又立刻恢复了,因此微软重新设计了群集中VM故障转移策略,能够让一定时间内的节点瞬时故障,不必再触发节点虚拟机的故障转移。
在WSFC 2016中,VM弹×××默认被启用,在2016 TP1中这项功能默认被禁用,随后的版本都默认启用,运行Get-Cluster |fl * 可以看到和VM弹性相关的配置

参数说明
ResiliencyLevel : IsolateOnSpecialHeartbeat或1,AlwaysIsolate或2,默认为AlwaysIsolate,即在发生节点瞬时中断后,在一段时间内可以允许虚拟机在线或暂停状态,IsolateOnSpecialHeartbeat即当检测到瞬时中断后,立刻置节点为失败状态,执行failover
之前我们说过2016里面重构了VM故障转移策略
到底是怎么重构的呢
在WSFC 2016里面,假设你发生了瞬时中断,例如
网络短暂不稳定,节点无法和其它节点通讯
群集服务崩溃,无法与其他节点连接
管理员误操作
当发生例如这种瞬时中断,群集现在新增了三个属性
隔离:针对于群集节点,在规定时间内,群集节点发生瞬时中断后,状态会被标记为隔离,该成员不会再是合格的群集成员,但上面托管的虚拟机,在一定时间内依然可以正常运行
未监视:针对于群集管理器中看虚拟机状态,如果当节点发生瞬时中断,变成隔离状态后,在群集里面看虚拟机,虚拟机会是未监视状态
如果虚拟机存储在SMB3/SOFS路径下,节点隔离状态后虚拟机可以使用Online状态运行,因为SMB可独立运行,如果虚拟机存储在FC/FCoE/iSCSI/ShareSAS等块存储构成的CSV路径下,那么虚拟机会被置为暂停状态,因为节点被隔离后,不是合格的群集成员,也将失去CSV的访问资格,如果节点恢复正常,虚拟机会从暂停状态中恢复正常运行,如果节点的瞬时中断一段时间内未恢复,虚拟机将会被failover到其它节点运作。
3. 检疫持续:我们会设定一个时间,在这个时间内,节点如果发生瞬时中断后又恢复了,虚拟机不会被迁移,只是继续运行,但如果节点在一小时内,被隔离达到一定次数,多次发生瞬时中断,则我们判定该节点当前不正常,该节点可能会导致应用不稳定,因此我们会把该节点置为检疫状态,置为检疫状态的节点,在一段时间内该节点将处于检疫状态,上面所有的虚拟机会被实时迁移走,直到我们分析判断该节点恢复正常后,再重新加入群集。
ResiliencyPeriod:配置节点在隔离状态下运作的时间,默认为240秒,即240秒内的瞬时中断,可以被接受,不需要发生故障转移,如果超过240秒仍未恢复,则按照群集检测走,执行故障转移操作。
#配置隔离状态时间
(Get-Cluster).ResiliencyDefaultPeriod = 60

#关闭隔离状态功能
(Get-Cluster).ResiliencyDefaultPeriod =0
#配置单个虚拟机级别隔离状态时间(即未监视状态时间)
(Get-ClusterGroup“stat”).ResiliencyPeriod = 60
QuarantineThreshold:节点进入检疫状态前的隔离次数,默认为3,即节点一小时内被置为3次隔离状态后,则节点进入检疫状态,所有虚拟机会被实时迁移走
#配置进入检疫状态前的隔离次数
(Get-Cluster).QuarantineThreshold =<value>
QuarantineDuration:节点处在检疫状态下的时间,默认为7200秒,在这段时间,节点将不承载应用,所有虚拟机被实时迁移走,管理员可以排查频繁导致瞬时终端的问题,如果修复好了后可以手动让节点提前恢复,或等到7200秒自动恢复。
#配置检疫状态时间
(Get-Cluster).QuarantineDuration = <value>
这项技术说太多可能会觉得枯燥,下面我们实际来看一下案例
当前环境里面四台虚拟机,其中RODC运作在SOFS路径,其它三台虚拟机运作在通过ISCSI提供的CSV路径下,我设置节点隔离状态时间为60秒,检疫状态时间为600秒,这里老王只是为了测试快点看到结果,真实环境下建议根据实际时间评估,多长时间内可以算作瞬时中断,频繁发生瞬时中断我需要多长时间进行排查问题节点。
WSFC 2016中要实现VM弹性的功能要求
群集功能级别为9
虚拟机配置级别升级至少6x以上
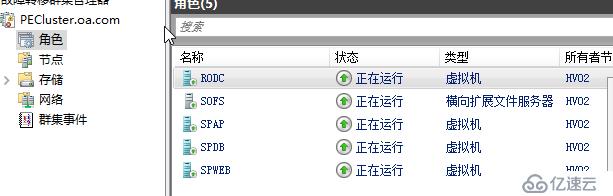
在老王的实验中,我将模拟一个群集服务短暂崩溃的场景,模拟群集服务强制停止后,观察群集的反应
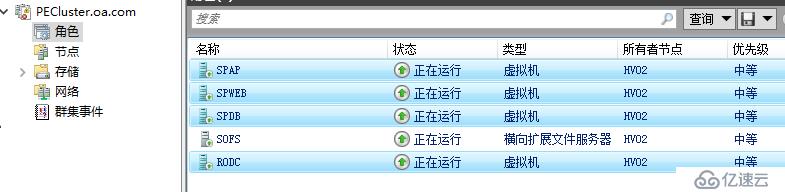
当前群集四台虚拟机都承载在HV01

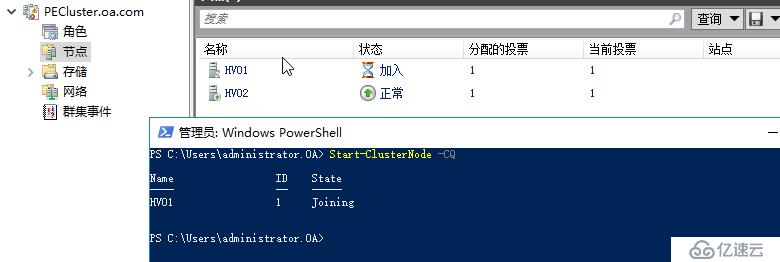
我们通过强制停止节点上面的clussvc进程来模拟群集服务崩溃
Stop-process -name clussvc -Force

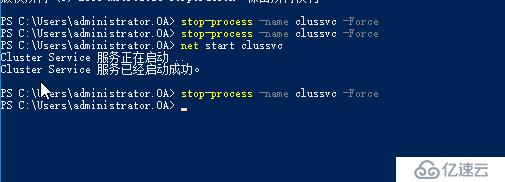
可以看到,群集服务崩溃后,节点会被置为隔离状态

所有虚拟机在群集里面看会是未被监视状态,这只是个群集管理器中看到的临时状态
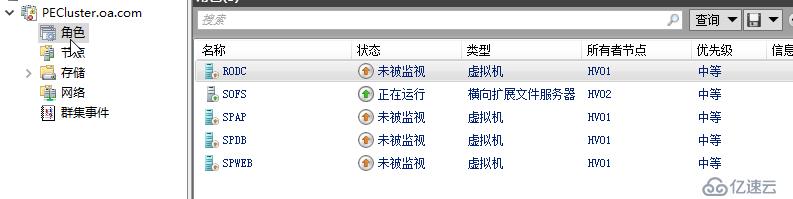
但其实在Hyper-V可以看到,实质上,存放在SOFS的RODC在60秒内会持续运行,运行在CSV上的其他虚拟机,虽然显示 正在运行-关键,这个中文显示是错的,英文上面显示为Paused-Critical,实质上它们是因为节点被隔离,失去到CSV的资格,而被置为暂停状态。
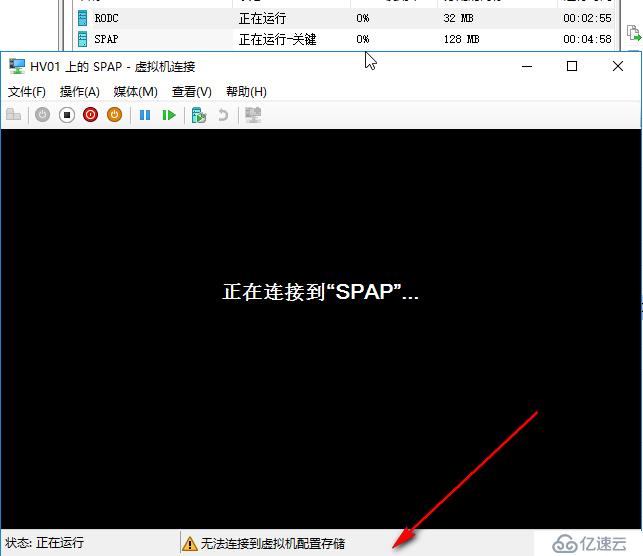
如果60秒内,节点又恢复正常了,瞬时中断恢复,网络恢复正常,服务不再崩溃,管理员恢复了误操作,则节点重新加入回到正常状态,已被暂停的虚拟机会重新开始运行,本例中我们强制终止clussvc进程后,稍后会自动启动起来
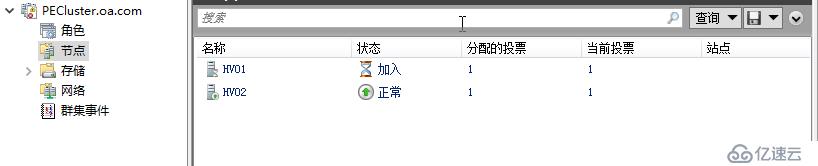

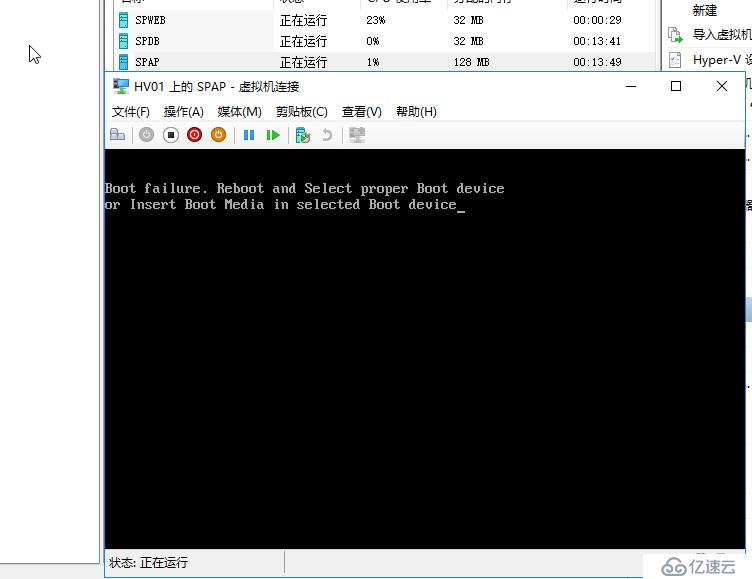
如果60秒内,瞬时中断,或是群集服务崩溃,或是网络临时中断,或是管理员误操作,没有得到修复,则节点会被置为Down状态,所有被置为未被监视状态的虚拟机会被迁移到其它活着的节点上,迁移过程是快速迁移,针对暂停的虚拟机会置为关机状态再迁移走。
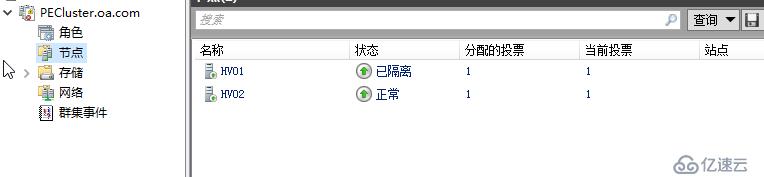
下面我们模拟1小时内3次隔离的情况发生,即同一节点三小时内发生瞬时中断
可以看到,在节点的地方查看发现已经从红隔离变成了绿隔离,但其实这个绿色的已隔离和上面红色的已隔离已经不是同一个意思,一个是Isolate,一个是Quarantine,进入绿隔离状态其实应该是我们说的检疫状态,即根据我们定义的算法,群集已经可以判断这个节点不正常了,它生病了,不应该再继续承载虚拟机,因此上面所有的虚拟机都会被实时迁移至其它节点,并在QuarantineDuration时间内,节点都将处于检疫状态,这时候管理员可以对节点进行错误诊断,确认频繁发生瞬时中断,是否意味着有真实的问题存在需要处理,
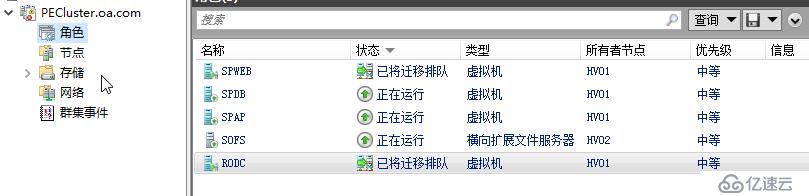
如果600秒时间到了,则群集认为您已经解决了该问题,自动解除检疫状态,放节点正常加入群集,如果您不想等待这个时间,或者您在已经提前解决了频繁瞬时中断的问题,那么您也可以运行命令 Start-ClusterNode -CQ 执行ClearQuarantine操作,把节点手动恢复正常
相信通过以上实验大家对于VM弹×××已经有了一定了解了
有了这项技术后,我们可以让群集保持以前的样子,根据检测信号完成快速的故障转移,也可以根据通过VM弹性技术,设置在一定瞬时中断时间内,接受短暂的中断又恢复,不需要立刻执行故障转移,可以分别把主机在瞬时中断下做隔离处理,甚至进一步检疫处理,相对来说更加正规一些,也比原来我们调整检测信号的方式来的效果更好,因此如果大家环境中有瞬时中断的情况,不妨了解使用下这项功能。
如果不想要VM弹×××,还想恢复以前基于信号检测直接做故障转移的运作方式
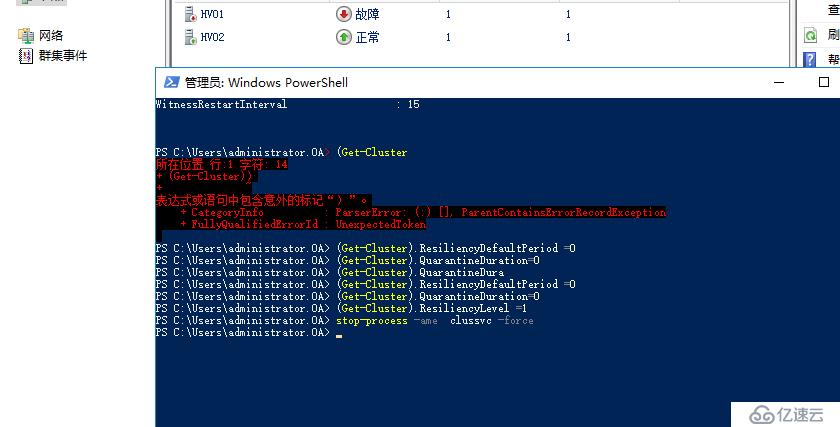
设置VM弹性值如下,则回到从前,需要注意,在2016TP2之后的版本,这项功能默认被启用,因此当发生网络中断,服务崩溃如果发现应用没快速故障转移,不要惊慌,那么是因为群集自动开启了VM弹×××,不想要它,直接这样disable掉即可

关闭VM弹性后,再次强制停止clussvc进程,发现节点直接进入故障状态,执行故障转移
以上为VM弹×××,可以帮助我们解决节点级别的网络,系统,误操作等瞬时故障,除了计算级别可以有这种弹×××,2016还在虚拟机存储中也添加了这项技术,主要针对于虚拟机访问VHDX,在2012R2中,如果虚拟机忽然访问不到VHDX,虚拟机肯定会崩溃无法使用,当存储再次可用,我们可能也需要重新打开虚拟机。
在WSFC 2016中群集虚拟机可以和存储实现更好的容错功能,非常的神奇,我们可以设置一个允许中断时间,在这段时间内,如果群集虚拟机到存储之间发生了瞬时故障,无法访问VHDX了,可以把虚拟机置为暂停关键状态,虚拟机将被冻结,状态得到保存,所有虚拟机的IO也都会被冻结
当VHDX恢复访问后,虚拟机从暂停状态回到正常运行,状态释放,所有IO得到正常运转,通过这样内置的存储容错功能,可以帮助我们在存储短暂连接失效的时候提供一种很好的方案,当存储再次可用时,虚拟机自动load io,对于用户来说,停机时间得到改善。
当前除了RODC虚拟机,其它虚拟机都是直接连接到的CSV,我们直接在ISCSI上面禁用掉16群集用的数据磁盘,这样CSV也就是失败,节点到存储失败,VHDX也再也不可读取
可以看到虚拟机又被置为正在运行-关键,但其实这个状态应该是Paused-Critical
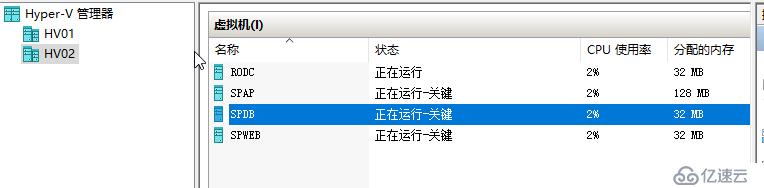
那么这个冻结虚拟机IO的时间是有限的,默认是30分钟,不可以太长,不可以是无限期的,在一段时间内,如果虚拟机仍然无法连接到VHDX,则VM将会关闭,下次启动将是冷启动
30分钟之内如果虚拟机恢复到存储的连接,则继续运作,虚拟机被置为正在运行,继续保留之前的工作状态,所有操作和IO正常运转,如果这个到存储的故障很短,那么对于用户来说是感受不到的,一旦存储连接上后,虚拟机会很快恢复运转,SOFS虚拟机最快,其次是CSV虚拟机,开挂的ShareVHDX虚拟机会直接执行实时迁移。
#配置虚拟机存储容错,HV级别配置虚拟机
开启虚拟机容错功能
Set-VM -AutomaticCriticalErrorAction <None | Pause>
默认为Pause,即存储无法连接时暂停,改成None则回到以前状态,如果要修改需关闭虚拟机!
配置虚拟机存储无法连接等待时间 默认30分钟
Set-VM –AutomaticCriticalErrorActionTimeout <value in minutes>
针对于ShareVhdx虚拟机在Hyper-V 2016会每隔十分钟轮询一次,存储是否可用,如果不可用则自动实时迁移到其它节点上。
VM存储容错功能,仅支持基于CSV的VHD,VHDX检测,或sharevhdx,sofs
不支持为群集化的本地VHD VHDX
不支持使用直通磁盘,或USB存储的虚拟机
以上,老王为大家介绍了VM弹性和存储容错的功能,关注这项技术很久了,一直很想把这项技术介绍给国内的朋友,这次终于写好了,希望能够为看到的朋友带来收获,如果您的环境中存在节点,网络,存储的瞬时故障,现在您可以通过2016中的VM弹性技术进行控制,尤其是针对于存储的神奇容错功能。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





