JDKжәҗз Ғдёӯе®һз”Ёзҡ„е°ҸжҠҖе·§жңүе“Әдәӣ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іJDKжәҗз Ғдёӯе®һз”Ёзҡ„е°ҸжҠҖе·§жңүе“Әдәӣзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
1 i++ vs i--
Stringжәҗз Ғзҡ„第985иЎҢпјҢequalsж–№жі•дёӯ
while (n--!= 0) {
if (v1[i] != v2[i])
return false;
i++;
}иҝҷж®өд»Јз ҒжҳҜз”ЁдәҺеҲӨж–ӯеӯ—з¬ҰдёІжҳҜеҗҰзӣёзӯүпјҢдҪҶжңүдёӘеҘҮжҖӘең°ж–№жҳҜз”ЁдәҶi--!=0жқҘеҒҡеҲӨж–ӯпјҢжҲ‘们йҖҡеёёдёҚжҳҜз”Ёi++д№Ҳпјҹдёәд»Җд№Ҳз”Ёi--е‘ўпјҹиҖҢдё”еҫӘзҺҜж¬Ўж•°зӣёеҗҢгҖӮеҺҹеӣ еңЁдәҺзј–иҜ‘еҗҺдјҡеӨҡдёҖжқЎжҢҮд»Өпјҡ
i-- ж“ҚдҪңжң¬иә«дјҡеҪұе“ҚCPSR(еҪ“еүҚзЁӢеәҸзҠ¶жҖҒеҜ„еӯҳеҷЁ)пјҢCPSRеёёи§Ғзҡ„ж Үеҝ—жңүN(з»“жһңдёәиҙҹ), Z(з»“жһңдёә0)пјҢCпјҲжңүиҝӣдҪҚпјүпјҢOпјҲжңүжәўеҮәпјүгҖӮi > 0пјҢеҸҜд»ҘзӣҙжҺҘйҖҡиҝҮZж Үеҝ—еҲӨж–ӯеҮәжқҘгҖӮ
i++ж“ҚдҪңд№ҹдјҡеҪұе“ҚCPSR(еҪ“еүҚзЁӢеәҸзҠ¶жҖҒеҜ„еӯҳеҷЁ)пјҢдҪҶеҸӘеҪұе“ҚOпјҲжңүжәўеҮәпјүж Үеҝ—пјҢиҝҷеҜ№дәҺi < nзҡ„еҲӨж–ӯжІЎжңүд»»дҪ•её®еҠ©гҖӮжүҖд»ҘиҝҳйңҖиҰҒдёҖжқЎйўқеӨ–зҡ„жҜ”иҫғжҢҮд»ӨпјҢд№ҹе°ұжҳҜиҜҙжҜҸдёӘеҫӘзҺҜиҰҒеӨҡжү§иЎҢдёҖжқЎжҢҮд»ӨгҖӮ
з®ҖеҚ•жқҘиҜҙпјҢи·ҹ0жҜ”иҫғдјҡе°‘дёҖжқЎжҢҮд»ӨгҖӮжүҖд»ҘпјҢеҫӘзҺҜдҪҝз”Ёi--пјҢй«ҳз«ҜеӨ§ж°”дёҠжЎЈж¬ЎгҖӮ
2 жҲҗе‘ҳеҸҳйҮҸ vs еұҖйғЁеҸҳйҮҸ
JDKжәҗз ҒеңЁд»»дҪ•ж–№жі•дёӯеҮ д№ҺйғҪдјҡз”ЁдёҖдёӘеұҖйғЁеҸҳйҮҸжқҘжҺҘеҸ—жҲҗе‘ҳеҸҳйҮҸпјҢжҜ”еҰӮ
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;еӣ дёәеұҖйғЁеҸҳйҮҸеҲқе§ӢеҢ–еҗҺжҳҜеңЁиҜҘж–№жі•зәҝзЁӢж ҲдёӯпјҢиҖҢжҲҗе‘ҳеҸҳйҮҸеҲқе§ӢеҢ–жҳҜеңЁе ҶеҶ…еӯҳдёӯпјҢжҳҫ然еүҚиҖ…жӣҙеҝ«пјҢжүҖд»ҘпјҢжҲ‘们еңЁж–№жі•дёӯе°ҪйҮҸйҒҝе…ҚзӣҙжҺҘдҪҝз”ЁжҲҗе‘ҳеҸҳйҮҸпјҢиҖҢжҳҜдҪҝз”ЁеұҖйғЁеҸҳйҮҸгҖӮ
3 еҲ»ж„ҸеҠ иҪҪеҲ°еҜ„еӯҳеҷЁ && е°ҶиҖ—ж—¶ж“ҚдҪңж”ҫеҲ°й”ҒеӨ–йғЁ
еңЁConcurrentHashMapдёӯпјҢй”Ғsegmentзҡ„ж“ҚдҪңеҫҲжңүж„ҸжҖқпјҢе®ғдёҚжҳҜзӣҙжҺҘй”ҒпјҢиҖҢжҳҜзұ»дјјдәҺиҮӘж—Ӣй”ҒпјҢеҸҚеӨҚе°қиҜ•иҺ·еҸ–й”ҒпјҢ并且еңЁиҺ·еҸ–й”Ғзҡ„иҝҮзЁӢдёӯпјҢдјҡйҒҚеҺҶй“ҫиЎЁпјҢд»ҺиҖҢе°Ҷж•°жҚ®е…ҲеҠ иҪҪеҲ°еҜ„еӯҳеҷЁдёӯзј“еӯҳдёӯпјҢйҒҝе…ҚеңЁй”Ғзҡ„иҝҮзЁӢдёӯеңЁдҫҝеҲ©пјҢеҗҢж—¶пјҢз”ҹжҲҗж–°еҜ№иұЎзҡ„ж“ҚдҪңд№ҹжҳҜж”ҫеҲ°й”Ғзҡ„еӨ–йғЁжқҘеҒҡпјҢйҒҝе…ҚеңЁй”Ғдёӯзҡ„иҖ—ж—¶ж“ҚдҪң
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
/** еңЁеҫҖиҜҘ segment еҶҷе…ҘеүҚпјҢйңҖиҰҒе…ҲиҺ·еҸ–иҜҘ segment зҡ„зӢ¬еҚ й”Ғ
дёҚжҳҜејәеҲ¶lock()пјҢиҖҢжҳҜиҝӣиЎҢе°қиҜ• */
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);scanAndLockForPut()жәҗз Ғ
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// еҫӘзҺҜиҺ·еҸ–й”Ғ
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
//иҜҘhashдҪҚж— еҖјпјҢж–°е»әеҜ№иұЎпјҢиҖҢдёҚз”ЁеҶҚеҲ°put()ж–№жі•зҡ„й”ҒдёӯеҶҚж–°е»ә
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
//иҜҘhashдҪҚзҪ®keyд№ҹзӣёеҗҢпјҢйҖҖеҢ–жҲҗиҮӘж—Ӣй”Ғ
else if (key.equals(e.key))
retries = 0;
else
// еҫӘзҺҜй“ҫиЎЁпјҢcpuиғҪиҮӘеҠЁе°Ҷй“ҫиЎЁиҜ»е…Ҙзј“еӯҳ
e = e.next;
}
// retries>0ж—¶е°ұеҸҳжҲҗиҮӘж—Ӣй”ҒгҖӮеҪ“然пјҢеҰӮжһңйҮҚиҜ•ж¬Ўж•°еҰӮжһңи¶…иҝҮ MAX_SCAN_RETRIESпјҲеҚ•ж ё1еӨҡж ё64пјүпјҢйӮЈд№ҲдёҚжҠўдәҶпјҢиҝӣе…ҘеҲ°йҳ»еЎһйҳҹеҲ—зӯүеҫ…й”Ғ
// lock() жҳҜйҳ»еЎһж–№жі•пјҢзӣҙеҲ°иҺ·еҸ–й”ҒеҗҺиҝ”еӣһпјҢеҗҰеҲҷжҢӮиө·
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
// иҝҷдёӘж—¶еҖҷжҳҜжңүеӨ§й—®йўҳдәҶпјҢйӮЈе°ұжҳҜжңүж–°зҡ„е…ғзҙ иҝӣеҲ°дәҶй“ҫиЎЁпјҢжҲҗдёәдәҶж–°зҡ„иЎЁеӨҙ
// жүҖд»Ҙиҝҷиҫ№зҡ„зӯ–з•ҘжҳҜпјҢзӣёеҪ“дәҺйҮҚж–°иө°дёҖйҒҚиҝҷдёӘ scanAndLockForPut ж–№жі•
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}4 еҲӨж–ӯеҜ№иұЎзӣёзӯүеҸҜе…Ҳз”Ё==
еңЁеҲӨж–ӯеҜ№иұЎжҳҜеҗҰзӣёзӯүж—¶пјҢеҸҜе…Ҳз”Ё==пјҢеӣ дёә==зӣҙжҺҘжҜ”иҫғең°еқҖпјҢйқһеёёеҝ«пјҢиҖҢequalsзҡ„иҜқдјҡжңҖеҜ№иұЎеҖјзҡ„жҜ”иҫғпјҢзӣёеҜ№иҫғж…ўпјҢжүҖд»ҘжңүеҸҜиғҪзҡ„иҜқпјҢеҸҜд»Ҙз”Ёa==b || a.equals(b)жқҘжҜ”иҫғеҜ№иұЎжҳҜеҗҰзӣёзӯү
5 е…ідәҺtransient
transientжҳҜз”ЁжқҘйҳ»жӯўеәҸеҲ—еҢ–зҡ„пјҢдҪҶHashMapжәҗз ҒдёӯеҶ…йғЁж•°з»„жҳҜе®ҡд№үдёәtransientзҡ„
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
йӮЈеІӮдёҚйҮҢйқўзҡ„й”®еҖјеҜ№йғҪж— жі•еәҸеҲ—еҢ–дәҶд№ҲпјҢзҪ‘з»ңдёӯз”ЁhashmapжқҘдј иҫ“еІӮдёҚжҳҜж— жі•дј иҫ“пјҢе…¶е®һдёҚ然гҖӮ
Effective Java 2nd, Item75, JoshuaеӨ§зҘһжҸҗеҲ°:
For example, consider the case of a hash table. The physical
representation is a sequence of hash buckets containing key-value
entries. The bucket that an entry resides in is a function of the hash
code of its key, which is not, in general, guaranteed to be the same
from JVM implementation to JVM implementation. In fact, it isn't even
guaranteed to be the same from run to run. Therefore, accepting the
default serialized form for a hash table would constitute a serious
bug. Serializing and deserializing the hash table could yield an
object whose invariants were seriously corrupt.
жҖҺд№ҲзҗҶи§Ј? зңӢдёҖдёӢHashMap.get()/put()зҹҘйҒ“, иҜ»еҶҷMapжҳҜж №жҚ®Object.hashcode()жқҘзЎ®е®ҡд»Һе“ӘдёӘbucketиҜ»/еҶҷ. иҖҢObject.hashcode()жҳҜnativeж–№жі•, дёҚеҗҢзҡ„JVMйҮҢеҸҜиғҪжҳҜдёҚдёҖж ·зҡ„.
жү“дёӘжҜ”ж–№иҜҙ, еҗ‘HashMapеӯҳдёҖдёӘentry, keyдёә еӯ—з¬ҰдёІ"STRING", еңЁз¬¬дёҖдёӘjavaзЁӢеәҸйҮҢ, "STRING"зҡ„hashcode()дёә1, еӯҳе…Ҙ第1еҸ·bucket; еңЁз¬¬дәҢдёӘjavaзЁӢеәҸйҮҢ, "STRING"зҡ„hashcode()жңүеҸҜиғҪе°ұжҳҜ2, еӯҳе…Ҙ第2еҸ·bucket. еҰӮжһңз”Ёй»ҳи®Өзҡ„дёІиЎҢеҢ–(Entry[] tableдёҚз”Ёtransient), йӮЈд№ҲиҝҷдёӘHashMapд»Һ第дёҖдёӘjavaзЁӢеәҸйҮҢйҖҡиҝҮдёІиЎҢеҢ–еҜје…Ҙ第дәҢдёӘjavaзЁӢеәҸеҗҺ, е…¶еҶ…еӯҳеҲҶеёғжҳҜдёҖж ·зҡ„, иҝҷе°ұдёҚеҜ№дәҶ.
дёҫдёӘдҫӢеӯҗпјҢжҜ”еҰӮеҗ‘HashMapеӯҳдёҖдёӘй”®еҖјеҜ№entry, key="ж–№иҖҒеҸё", еңЁз¬¬дёҖдёӘjavaзЁӢеәҸйҮҢ, "ж–№иҖҒеҸё"зҡ„hashcode()дёә1, еӯҳе…Ҙtable[1]пјҢеҘҪпјҢзҺ°еңЁдј еҲ°еҸҰдёҖдёӘеңЁJVMзЁӢеәҸйҮҢ, "ж–№иҖҒеҸё" зҡ„hashcode()жңүеҸҜиғҪе°ұжҳҜ2, дәҺжҳҜеҲ°table[2]еҺ»еҸ–пјҢз»“жһңеҖјдёҚеӯҳеңЁгҖӮ
HashMapзҺ°еңЁзҡ„readObjectе’ҢwriteObjectжҳҜжҠҠеҶ…е®№ иҫ“еҮә/иҫ“е…Ҙ, жҠҠHashMapйҮҚж–°з”ҹжҲҗеҮәжқҘ.
6 дёҚиҰҒз”Ёchar
charеңЁJavaдёӯutf-16зј–з ҒпјҢжҳҜ2дёӘеӯ—иҠӮпјҢиҖҢ2дёӘеӯ—иҠӮжҳҜж— жі•иЎЁзӨәе…ЁйғЁеӯ—з¬Ұзҡ„гҖӮ2дёӘеӯ—иҠӮиЎЁзӨәзҡ„з§°дёә BMPпјҢеҸҰеӨ–зҡ„дҪңдёәhigh surrogateе’Ң low surrogate жӢјжҺҘз»„жҲҗз”ұ4еӯ—иҠӮиЎЁзӨәзҡ„еӯ—з¬ҰгҖӮжҜ”еҰӮStringжәҗз Ғдёӯзҡ„indexOf:
//иҝҷйҮҢз”ЁintжқҘжҺҘеҸ—дёҖдёӘcharпјҢж–№дҫҝеҲӨж–ӯиҢғеӣҙ
public int indexOf(int ch, int fromIndex) {
final int max = value.length;
if (fromIndex < 0) {
fromIndex = 0;
} else if (fromIndex >= max) {
// Note: fromIndex might be near -1>>>1.
return -1;
}
//еңЁBmpиҢғеӣҙ
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
//еҗҰеҲҷиҪ¬еҲ°еӣӣдёӘеӯ—иҠӮзҡ„еҲӨж–ӯж–№ејҸ
return indexOfSupplementary(ch, fromIndex);
}
}жүҖд»ҘJavaзҡ„charеҸӘиғҪиЎЁзӨәutf­16дёӯзҡ„bmpйғЁеҲҶеӯ—з¬ҰгҖӮеҜ№дәҺCJKпјҲдёӯж—Ҙйҹ©з»ҹдёҖиЎЁж„Ҹж–Үеӯ—пјүйғЁеҲҶжү©еұ•еӯ—з¬ҰйӣҶеҲҷж— жі•иЎЁзӨәгҖӮ
дҫӢеҰӮпјҢдёӢеӣҫдёӯйҷӨExt-AйғЁеҲҶпјҢcharеқҮж— жі•иЎЁзӨәгҖӮ
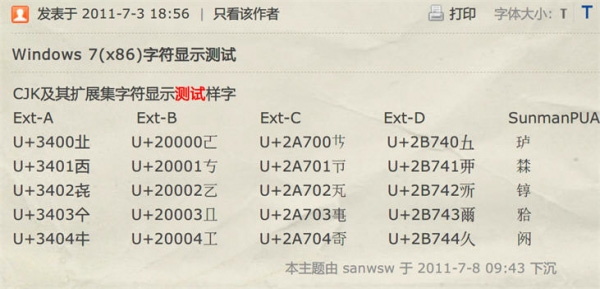
жӯӨеӨ–иҝҳжңүдёҖз§ҚиҜҙжі•жҳҜиҰҒз”ЁcharпјҢеҜҶз ҒеҲ«з”ЁStringпјҢStringжҳҜеёёйҮҸпјҲеҚіеҲӣе»әд№ӢеҗҺе°ұж— жі•жӣҙж”№пјүпјҢдјҡдҝқеӯҳеҲ°еёёйҮҸжұ дёӯпјҢеҰӮжһңжңүе…¶д»–иҝӣзЁӢеҸҜд»ҘdumpиҝҷдёӘиҝӣзЁӢзҡ„еҶ…еӯҳпјҢйӮЈд№ҲеҜҶз Ғе°ұдјҡйҡҸзқҖеёёйҮҸжұ иў«dumpеҮәеҺ»д»ҺиҖҢжі„йңІпјҢиҖҢchar[]еҸҜд»ҘеҶҷе…Ҙе…¶д»–зҡ„дҝЎжҒҜд»ҺиҖҢж”№еҸҳпјҢеҚіжҳҜиў«dumpдәҶд№ҹдјҡеҮҸе°‘жі„йңІеҜҶз Ғзҡ„йЈҺйҷ©гҖӮ
дҪҶдёӘдәәи®ӨдёәдҪ йғҪиғҪdumpеҶ…еӯҳдәҶйҡҫйҒ“жҳҜдёҖдёӘcharиғҪеӨҹйҳІиҢғзҡ„дҪҸзҡ„пјҹйҷӨйқһжҳҜStringеңЁеёёйҮҸжұ дёӯжңӘиў«еӣһ收пјҢиҖҢиў«е…¶е®ғзәҝзЁӢзӣҙжҺҘд»ҺеёёйҮҸжұ дёӯиҜ»еҸ–пјҢдҪҶжҒҗжҖ•д№ҹжҳҜйқһеёёзҪ•и§Ғзҡ„еҗ§гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңJDKжәҗз Ғдёӯе®һз”Ёзҡ„е°ҸжҠҖе·§жңүе“ӘдәӣвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ





