小编给大家分享一下scrapy爬取豆瓣电影数据的方法,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨方法吧!
1.建立项目
执行如下命令建立scrapy爬虫项目
scrapy startproject spider_douban
命令执行完成后,建立了spider_douban文件夹,目录结构如下:
.
├── scrapy.cfg
└── spider_douban
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── douban_spider.py
└── __init__.py
2.建立爬虫数据模型
打开 ./spider_douban/items.py 文件,编辑内容如下:
import scrapy class DoubanMovieItem(scrapy.Item): # 排名 ranking = scrapy.Field() # 电影名称 movie_name = scrapy.Field() # 评分 score = scrapy.Field() # 评论人数 score_num = scrapy.Field()
3.新建爬虫文件
新建 ./spiders/douban_spider.py 文件,编辑内容如下:
from scrapy import Request
from scrapy.spiders import Spider
from spider_douban.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
start_urls = {
'https://movie.douban.com/top250'
}
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
'''
def parse(self, response):
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
print(movies)
print('=============================================')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(r'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url)爬虫文件各部分功能记录
douban_spider.py文件主要有几部分构成。
导入模块
from scrapy import Request from scrapy.spiders import Spider from spider_douban.items import DoubanMovieItem
Request 类用于请求要爬取的页面数据
Spider 类是爬虫的基类
DoubanMovieItem 是我们第一步建立的爬取数据模型
初始设置
基于spider类定义的爬虫类DoubanMovieTop250Spider中,首先定义爬虫的基本信息:
name:在项目中爬虫的名称,可以在项目目录中执行scrapy list获取已经定义的爬虫列表
start_urls:是爬取的第一个页面地址
headers:是向web服务器发送页面请求的时候附加的user-agent消息,告诉web服务器是什么类型的浏览器或设备在请求页面,对于不具备简单反爬机制的网站,headers部分可以省略。
为了迷惑web服务器,一般会在爬虫发送web请求的时候定义user-agent信息,这里有两种写法。
header的第一种定义:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)可以看到,这种写法中,start_urls定义没有了,转而定义了start_requests函数,开始的url写到了函数里。同时,定义了headers字典,在发送Request请求的时候,将headers字典一并发送。这种写法简单直观,缺点是在一个爬虫项目执行期间,所有请求都是一个User-Agent属性。
header的第二种定义:
start_urls = {
'https://movie.douban.com/top250'
}简单、直接的定义start_urls属性,而Request中的header属性通过其他方法另外定义,容后再说。
parse处理函数
逐句分解说明
1.基于我们定义的DoubanMovieItem类创建item实例
item = DoubanMovieItem()
2.解析页面 - 获取内容框架

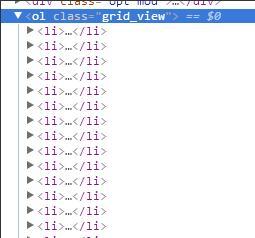
通过分析页面源码,我们能够看到,页面中的电影信息是保存在了<ol>标签中,这个<ol>标签有一个独特的样式表grid_view,而每一个单独的电影信息保存在了<li>标签中,下面代码获取class属性为grid_view的<ol>标签下的所有<li>标签内容。
movies = response.xpath('//ol[@class="grid_view"]/li')
3.解析页面 - 获取分项
在每一个<li>标签中,还有内部结构,通过xpath()解析,将每一项内容解析出来,赋值给item实例中的各个字段。通过查看movie.douban.com/top250页面的源码可以很容易找到这个标签定义的内容。如果我们通过type()函数查看movies的变量类型,可以发现他的类型是<class 'scrapy.selector.unified.SelectorList'>。<ol>标签中的每一个<li>标签都是这个列表中的一项,那么就可以对movies做迭代。
首先看看<li>标签中的页面结构:
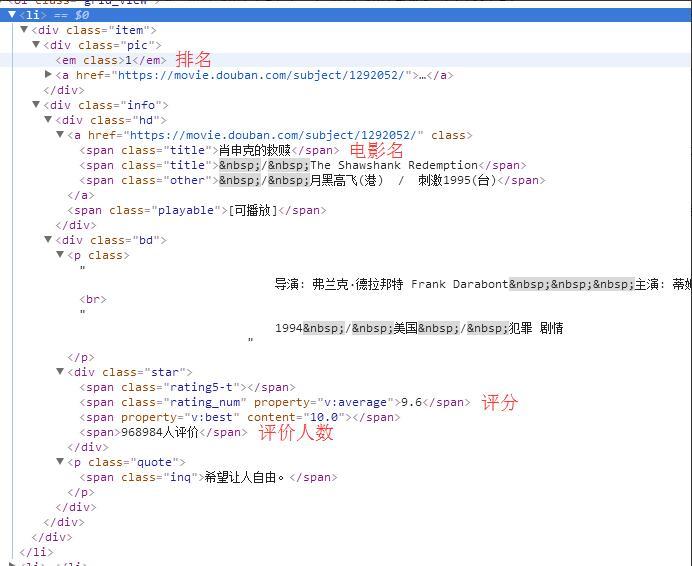
可以看到要提取数据的各部分所在标签位置:
排名:class属性为pic的<div>标签下,,<em>标签中...
电影名:class属性为hd的<div>标签下,<a>标签中的第一个<span>标签...
评分:class属性为star的<div>标签下,class属性为rating_num的<span>标签中...
评论人数:class属性为star的<div>标签下,<span>标签中。由于使用了re正则表达式,所以没有特别指定是哪一个<span>标签。
回到代码部分,对之前定义的movies做迭代,逐项获取要抓取的数据。
for movie in movies:
item['ranking'] = movie.xpath('.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath('.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath('.//div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
item['score_num'] = movie.xpath('.//div[@class="star"]/span/text()').re(r '(\d+)人评价')[0]
yield item4.Url跳转(翻页)
如果到此为止,我们可以将https://movie.douban.com/top250页面中的第一页内容爬取到,但只有25项记录,要爬取全部的250条记录,就要执行下面代码:
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url)首先通过xpath解析了页面中后页的链接,并赋值给next_url变量,如果我们当前在第一页,那么解析后页的链接就是?start=25&filter=。将解析的后页链接与完整url连接形成完整的地址,再次执行Request(),就实现了对全部250条记录的爬取。注意:通过xpath解析出的结果是列表,所以在引用的时候写成next_url[0]。
4.处理随机Head属性(随机User-Agent)
实现随机的head属性发送。主要改两个文件:
settings.py
USER_AGENT_LIST = [
'zspider/0.9-dev http://feedback.redkolibri.com/',
'Xaldon_WebSpider/2.0.b1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) Speedy Spider (http://www.entireweb.com/about/search_tech/speedy_spider/)',
'Mozilla/5.0 (compatible; Speedy Spider; http://www.entireweb.com/about/search_tech/speedy_spider/)',
'Speedy Spider (Entireweb; Beta/1.3; http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (Entireweb; Beta/1.2; http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (Entireweb; Beta/1.1; http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (Entireweb; Beta/1.0; http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (Beta/1.0; www.entireweb.com)',
'Speedy Spider (http://www.entireweb.com/about/search_tech/speedy_spider/)',
'Speedy Spider (http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (http://www.entireweb.com)',
'Sosospider+(+http://help.soso.com/webspider.htm)',
'sogou spider',
'Nusearch Spider (www.nusearch.com)',
'nuSearch Spider (compatible; MSIE 4.01; Windows NT)',
'lmspider (lmspider@scansoft.com)',
'lmspider lmspider@scansoft.com',
'ldspider (http://code.google.com/p/ldspider/wiki/Robots)',
'iaskspider/2.0(+http://iask.com/help/help_index.html)',
'iaskspider',
'hl_ftien_spider_v1.1',
'hl_ftien_spider',
'FyberSpider (+http://www.fybersearch.com/fyberspider.php)',
'FyberSpider',
'everyfeed-spider/2.0 (http://www.everyfeed.com)',
'envolk[ITS]spider/1.6 (+http://www.envolk.com/envolkspider.html)',
'envolk[ITS]spider/1.6 ( http://www.envolk.com/envolkspider.html)',
'Baiduspider+(+http://www.baidu.com/search/spider_jp.html)',
'Baiduspider+(+http://www.baidu.com/search/spider.htm)',
'BaiDuSpider',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0) AddSugarSpiderBot www.idealobserver.com',
]
DOWNLOADER_MIDDLEWARES = {
'spider_douban.middlewares.RandomUserAgentMiddleware': 400,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None,
}USER_AGENT_LIST定义了一些浏览器user-agent属性,网上有很多,可以找来直接加进去,需要注意的是有些user-agent信息是移动设备(手机或平板)的,如果不注意的话,可能请求到的数据与你看到的数据有较大差异;
DOWNLOADER_MIDDLEWARES定义了下载器中间件,它在发送页面请求数据的时候被调用。
middlewares.py
from spider_douban.settings import USER_AGENT_LIST
import random
class RandomUserAgentMiddleware():
def process_request(self, request, spider):
ua = random.choice(USER_AGENT_LIST)
if ua:
request.headers.setdefault('User-Agent', ua)在RandomUserAgentMiddleware()中,每次发送请求数据,会在USER_AGENT_LIST中随机选择一条User-Agent记录。
5.结果保存
编辑pipelines.py文件:
from scrapy import signals
from scrapy.contrib.exporter import CsvItemExporter
class SpiderDoubanPipeline(CsvItemExporter):
def __init__(self):
self.files = {}
@classmethod
def from_crawler(cls, crawler):
print('==========pipeline==========from_crawler==========')
pipeline = cls()
crawler.signals.connect(pipeline.spider_opened, signals.spider_opened)
crawler.signals.connect(pipeline.spider_closed, signals.spider_closed)
return pipeline
def spider_opened(self, spider):
savefile = open('douban_top250_export.csv', 'wb+')
self.files[spider] = savefile
print('==========pipeline==========spider_opened==========')
self.exporter = CsvItemExporter(savefile)
self.exporter.start_exporting()
def spider_closed(self, spider):
print('==========pipeline==========spider_closed==========')
self.exporter.finish_exporting()
savefile = self.files.pop(spider)
savefile.close()
def process_item(self, item, spider):
print('==========pipeline==========process_item==========')
print(type(item))
self.exporter.export_item(item)
return itemSpiderDoubanPipeline类是建立项目的时候自行建立的,为了保存文件,做了修改。
def from_crawler(cls, crawler):
如果存在,则调用此类方法从Crawler创建pipeline实例。它必须返回一个新的pipeline实例。抓取对象提供对所有Scrapy核心组件的访问,如settings和signals; 这是pipeline访问它们并将其功能挂接到Scrapy的一种方式。
在此方法中,定义了一个数据收集器(cls)的实例:‘pipeline’。
signals:Scrapy使用信号来通知事情发生。您可以在您的Scrapy项目中捕捉一些信号(使用 extension)来完成额外的工作或添加额外的功能,扩展Scrapy。虽然信号提供了一些参数,不过处理函数不用接收所有的参数 - 信号分发机制(singal dispatching mechanism)仅仅提供处理器(handler)接受的参数。您可以通过 信号(Signals) API 来连接(或发送您自己的)信号。
connect:链接一个接收器函数(receiver function) 到一个信号(signal)。signal可以是任何对象,虽然Scrapy提供了一些预先定义好的信号。
def spider_opened(self, spider):
当spider开始爬取时发送该信号。该信号一般用来分配spider的资源,不过其也能做任何事。该信号支持返回deferreds。
此方法中,创建了一个文件对象实例:savefile。
CsvItemExporter(savefile):输出 csv 文件格式. 如果添加 fields_to_export 属性, 它会按顺序定义CSV的列名.
def spider_closed(self, spider):
当某个spider被关闭时,该信号被发送。该信号可以用来释放每个spider在 spider_opened 时占用的资源。该信号支持返回deferreds。
def process_item(self, item, spider):
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的item将不会被之后的pipeline组件所处理。
启用pipeline
为了让我们定义的pipeline生效,要在settings.py文件中,打开ITEM_PIPELINES注释:
ITEM_PIPELINES = {
'spider_douban.pipelines.SpiderDoubanPipeline': 300,
}6.执行爬虫
scrapy crawl douban_movie_top250
执行爬虫能够看到爬取到的数据。。。
如果之前pipeline部分代码没有写,也可以用下面的命令,在爬虫执行的时候直接导出数据:
scrapy crawl douban_movie_top250 -o douban.csv
增加-o参数,可以将爬取到的数据保存到douban.csv文件中。。
7.文件编码的问题
我在linux服务器执行爬虫,生成csv文件后,在win7系统中用excel打开变成乱码。在网上找了一些文章,有的文章直接改变linux文件默认编码,但是感觉这么做会对其他项目产生影响。最后选择一个相对简单的方式。按这几步执行就可以:
不要直接用excel打开csv文件。先打开excel,建立空白工作表。
选择数据选项卡,打开获取外部数据中的自文本。
在导入文本文件对话框中选择要导入的csv文件。
在文本导入向导 - 第1步中,设置文件原始格式为65001 : Unicode (UTF-8)
继续下一步选择逗号分隔,就可以导入正常文本了。
看完了这篇文章,相信你对scrapy爬取豆瓣电影数据的方法有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





