这篇文章主要介绍关于MongoDB数据库中索引的简介,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
为什么需要索引?
当你抱怨MongoDB集合查询效率低的时候,可能你就需要考虑使用索引了,为了方便后续介绍,先科普下MongoDB里的索引机制(同样适用于其他的数据库比如mysql)。
mongo-9552:PRIMARY> db.person.find()
{ "_id" : ObjectId("571b5da31b0d530a03b3ce82"), "name" : "jack", "age" : 19 }
{ "_id" : ObjectId("571b5dae1b0d530a03b3ce83"), "name" : "rose", "age" : 20 }
{ "_id" : ObjectId("571b5db81b0d530a03b3ce84"), "name" : "jack", "age" : 18 }
{ "_id" : ObjectId("571b5dc21b0d530a03b3ce85"), "name" : "tony", "age" : 21 }
{ "_id" : ObjectId("571b5dc21b0d530a03b3ce86"), "name" : "adam", "age" : 18 }当你往某各个集合插入多个文档后,每个文档在经过底层的存储引擎持久化后,会有一个位置信息,通过这个位置信息,就能从存储引擎里读出该文档。比如mmapv1引擎里,位置信息是『文件id + 文件内offset 』, 在wiredtiger存储引擎(一个KV存储引擎)里,位置信息是wiredtiger在存储文档时生成的一个key,通过这个key能访问到对应的文档;为方便介绍,统一用pos(position的缩写)来代表位置信息。
比如上面的例子里,person集合里包含插入了4个文档,假设其存储后位置信息如下(为方便描述,文档省去_id字段)
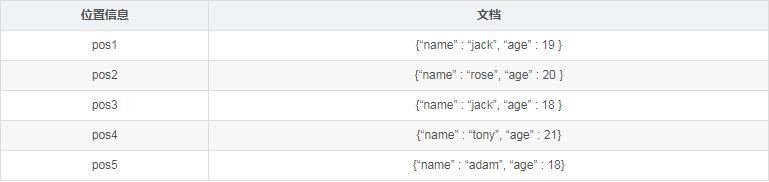
假设现在有个查询 db.person.find( {age: 18} ), 查询所有年龄为18岁的人,这时需要遍历所有的文档(『全表扫描』),根据位置信息读出文档,对比age字段是否为18。当然如果只有4个文档,全表扫描的开销并不大,但如果集合文档数量到百万、甚至千万上亿的时候,对集合进行全表扫描开销是非常大的,一个查询耗费数十秒甚至几分钟都有可能。
如果想加速 db.person.find( {age: 18} ),就可以考虑对person表的age字段建立索引。
db.person.createIndex( {age: 1} ) // 按age字段创建升序索引建立索引后,MongoDB会额外存储一份按age字段升序排序的索引数据,索引结构类似如下,索引通常采用类似btree的结构持久化存储,以保证从索引里快速(O(logN)的时间复杂度)找出某个age值对应的位置信息,然后根据位置信息就能读取出对应的文档。
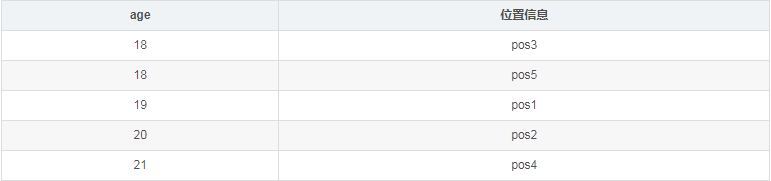
简单的说,索引就是将文档按照某个(或某些)字段顺序组织起来,以便能根据该字段高效的查询。有了索引,至少能优化如下场景的效率:
·查询,比如查询年龄为18的所有人
·更新/删除,将年龄为18的所有人的信息更新或删除,因为更新或删除时,需要根据条件先查询出所有符合条件的文档,所以本质上还是在优化查询
·排序,将所有人的信息按年龄排序,如果没有索引,需要全表扫描文档,然后再对扫描的结果进行排序
众所周知,MongoDB默认会为插入的文档生成_id字段(如果应用本身没有指定该字段),_id是文档唯一的标识,为了保证能根据文档id快递查询文档,MongoDB默认会为集合创建_id字段的索引。
mongo-9552:PRIMARY> db.person.getIndexes() // 查询集合的索引信息
[
{
"ns" : "test.person", // 集合名
"v" : 1, // 索引版本
"key" : { // 索引的字段及排序方向
"_id" : 1 // 根据_id字段升序索引
},
"name" : "_id_" // 索引的名称
}
]MongoDB索引类型
MongoDB支持多种类型的索引,包括单字段索引、复合索引、多key索引、文本索引等,每种类型的索引有不同的使用场合。
单字段索引 (Single Field Index)
db.person.createIndex( {age: 1} )上述语句针对age创建了单字段索引,其能加速对age字段的各种查询请求,是最常见的索引形式,MongoDB默认创建的id索引也是这种类型。
{age: 1} 代表升序索引,也可以通过{age: -1}来指定降序索引,对于单字段索引,升序/降序效果是一样的。
复合索引 (Compound Index)
复合索引是Single Field Index的升级版本,它针对多个字段联合创建索引,先按第一个字段排序,第一个字段相同的文档按第二个字段排序,依次类推,如下针对age, name这2个字段创建一个复合索引。
db.person.createIndex( {age: 1, name: 1} )上述索引对应的数据组织类似下表,与{age: 1}索引不同的时,当age字段相同时,在根据name字段进行排序,所以pos5对应的文档排在pos3之前。
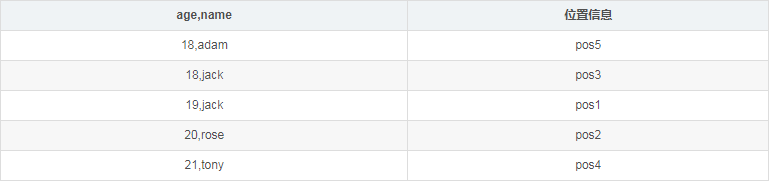
复合索引能满足的查询场景比单字段索引更丰富,不光能满足多个字段组合起来的查询,比如db.person.find( {age: 18, name: "jack"} ),也能满足所以能匹配符合索引前缀的查询,这里{age: 1}即为{age: 1, name: 1}的前缀,所以类似db.person.find( {age: 18} )的查询也能通过该索引来加速;但db.person.find( {name: "jack"} )则无法使用该复合索引。如果经常需要根据『name字段』以及『name和age字段组合』来查询,则应该创建如下的复合索引
db.person.createIndex( {name: 1, age: 1} )除了查询的需求能够影响索引的顺序,字段的值分布也是一个重要的考量因素,即使person集合所有的查询都是『name和age字段组合』(指定特定的name和age),字段的顺序也是有影响的。
age字段的取值很有限,即拥有相同age字段的文档会有很多;而name字段的取值则丰富很多,拥有相同name字段的文档很少;显然先按name字段查找,再在相同name的文档里查找age字段更为高效。
多key索引 (Multikey Index)
当索引的字段为数组时,创建出的索引称为多key索引,多key索引会为数组的每个元素建立一条索引,比如person表加入一个habbit字段(数组)用于描述兴趣爱好,需要查询有相同兴趣爱好的人就可以利用habbit字段的多key索引。
{"name" : "jack", "age" : 19, habbit: ["football, runnning"]}
db.person.createIndex( {habbit: 1} ) // 自动创建多key索引
db.person.find( {habbit: "football"} )其他类型索引
哈希索引(Hashed Index)是指按照某个字段的hash值来建立索引,目前主要用于MongoDB Sharded Cluster的Hash分片,hash索引只能满足字段完全匹配的查询,不能满足范围查询等。
地理位置索引(Geospatial Index)能很好的解决O2O的应用场景,比如『查找附近的美食』、『查找某个区域内的车站』等。
文本索引(Text Index)能解决快速文本查找的需求,比如有一个博客文章集合,需要根据博客的内容来快速查找,则可以针对博客内容建立文本索引。
索引额外属性
MongoDB除了支持多种不同类型的索引,还能对索引定制一些特殊的属性。
·唯一索引 (unique index):保证索引对应的字段不会出现相同的值,比如_id索引就是唯一索引
·TTL索引:可以针对某个时间字段,指定文档的过期时间(经过指定时间后过期 或 在某个时间点过期)
·部分索引 (partial index): 只针对符合某个特定条件的文档建立索引,3.2版本才支持该特性
·稀疏索引(sparse index): 只针对存在索引字段的文档建立索引,可看做是部分索引的一种特殊情况
索引优化
db profiling
MongoDB支持对DB的请求进行profiling,目前支持3种级别的profiling。
·0:不开启profiling
·1:将处理时间超过某个阈值(默认100ms)的请求都记录到DB下的system.profile集合 (类似于mysql、redis的slowlog)
·2:将所有的请求都记录到DB下的system.profile集合(生产环境慎用)
通常,生产环境建议使用1级别的profiling,并根据自身需求配置合理的阈值,用于监测慢请求的情况,并及时的做索引优化。
如果能在集合创建的时候就能『根据业务查询需求决定应该创建哪些索引』,当然是最佳的选择;但由于业务需求多变,要根据实际情况不断的进行优化。索引并不是越多越好,集合的索引太多,会影响写入、更新的性能,每次写入都需要更新所有索引的数据;所以你system.profile里的慢请求可能是索引建立的不够导致,也可能是索引过多导致。
查询计划
索引已经建立了,但查询还是很慢怎么破?这时就得深入的分析下索引的使用情况了,可通过查看下详细的查询计划来决定如何优化。通过执行计划可以看出如下问题:
(1)根据某个/些字段查询,但没有建立索引。
(2)根据某个/些字段查询,但建立了多个索引,执行查询时没有使用预期的索引。
建立索引前,db.person.find( {age: 18} )必须执行COLLSCAN,即全表扫描。
mongo-9552:PRIMARY> db.person.find({age: 18}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "test.person",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$eq" : 18
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"age" : {
"$eq" : 18
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "localhost",
"port" : 9552,
"version" : "3.2.3",
"gitVersion" : "b326ba837cf6f49d65c2f85e1b70f6f31ece7937"
},
"ok" : 1
}建立索引后,通过查询计划可以看出,先进行[IXSCAN]((https://docs.mongodb.org/manual/reference/explain-results/#queryplanner)(从索引中查找),然后FETCH,读取出满足条件的文档。
mongo-9552:PRIMARY> db.person.find({age: 18}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "test.person",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$eq" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "age_1",
"isMultiKey" : false,
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 1,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "localhost",
"port" : 9552,
"version" : "3.2.3",
"gitVersion" : "b326ba837cf6f49d65c2f85e1b70f6f31ece7937"
},
"ok" : 1
}以上是关于MongoDB数据库中索引的简介的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



