小编给大家分享一下python爬虫系列之xpath是什么,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
一、说到信息筛选我们立马就会想到正则表达式,不过今天我们不讲正则表达式。因为对于爬虫来讲,正则表达式太复杂对新手十分不友好,而且正则表达式的容错率差,网页有稍微的改动就得重新写匹配表达式,另外正则表达式可读性几乎没有。
当然,这并不是说正则不好,只是正则不适合爬虫和新手。其实正则是十分强大的,在后面的数据清洗里我们会用到正则。
既然正则不能用,那该用什么呢?别担心,python为我们提供了很多解析 html页面的库,其中常用的有:
bs4中的 BeautifulSoup
lxml中的 etree(一个 xpath解析库)
BeautifulSoup类似 jQuery的选择器,通过 id、css选择器和标签来查找元素,xpath主要通过 html节点的嵌套关系来查找元素,和文件的路径有点像,比如:
#获取 id为 tab的 table标签下所有 tr标签 path = '//table[@id="tab"]//tr' #和文件路径对比 path = 'D:\Github\hexo\source\_posts'
BeautifulSoup和 xpath没有好坏优劣之分,讲 xpath是因为个人觉得 xpath更好用一些,后面如果时间允许的话再讲 BeautifulSoup。
现在,让我们先从 xpath开始!
二、xpath的安装和使用
安装 lxml库
pip install lxml
简单的使用
在使用 xpath之前,先导入 etree类,对原始的 html页面进行处理获得一个_Element对象
我们可以通过_Element对象来使用 xpath
#导入 etree类
from lxml import etree
#作为示例的 html文本
html = '''<div class="container">
<div class="row">
<div class="col">
<div class="card">
<div class="card-content">
<a href="#123333" class="box">
点击我
</a>
</div>
</div>
</div>
</div>
</div>'''
#对 html文本进行处理 获得一个_Element对象
dom = etree.HTML(html)
#获取 a标签下的文本
a_text = dom.xpath('//div/div/div/div/div/a/text()')
print(a_text)打印结果

熟悉 html的朋友都知道在 html中所有的标签都是节点。一个 html文档是一个文档节点,一个文档节点包含一个节点树,也叫做 dom树。
节点树中的节点彼此拥有层级关系。
父(parent)、子(child)和同胞(sibling)等术语用于描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
在节点树中,顶端节点被称为根(root)
每个节点都有父节点、除了根(它没有父节点)
一个节点可拥有任意数量的子
同胞是拥有相同父节点的节点
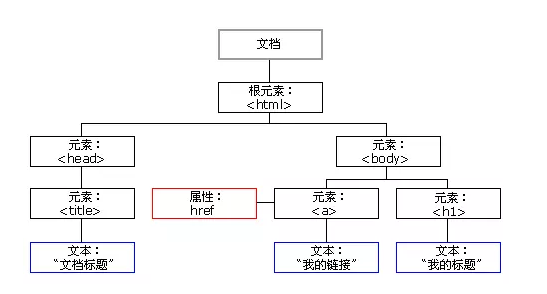
另外,我们把距离某个节点最近的子节点叫做它的直接子节点,如下图所示的 body和 head就是 html的直接子节点。
了解了 html结构之后我们再来看 xpath的使用。
首先,我们通过 etree.HTML( )来生成一个_Element对象,etree.HTML() 会将传入的文本处理成一个 html文档节点。这样就能保证我们总是能获得一个包含文档节点的_Element对象。
xpath语法
a / b :‘/’在 xpath里表示层级关系,左边的 a是父节点,右边的 b是子节点,这里的 b是 a的直接子节点
a // b:两个 / 表示选择所有 a节点下的 b节点(可以是直接子节点,也可以不是),在上面的例子中我们要选择 a标签是这样写的
a_text = dom.xpath('//div/div/div/div/div/a/text()')
#用 //
a_text = dom.xpath('//div//a/text()')
#如果 div标签下有两个 a标签,那么这两个 a标签都会被选择(注意两个 a标签并不一定是兄弟节点)
#比如下面的例子中的两个 a标签都会被选择 因为这两个 a标签都是 div的子节点
'''<div class="container">
<div class="row">
<div class="col">
<div class="card">
<a href="#123332" class="box">
点击我
</a>
<div class="card-content">
<a href="#123333" class="box">
点击我
</a>
</div>
</div>
</div>
</div>
</div>'''[@]:选择具有某个属性的节点
//div[@classs], //a[@x]:选择具有 class属性的 div节点、选择具有 x属性的 a节点
//div[@class="container"]:选择具有 class属性的值为 container的 div节点
//a[contains(text(), "点")]:选择文本内容里含有 “点” 的 a标签,比如上面例子中的两个 a标签
//a[contains(@id, "abc")]:选择 id属性里有 abc的 a标签,如
//a[contains(@y, "x")]:选择有 y属性且 y属性包含 x值的 a标签
#这两条 xpath规则都可以选取到例子中的两个 a标签 path = '//a[contains(@href, "#123")]' path = '//a[contains(@href, "#1233")]'
总结
使用 xpath之前必须先对 html文档进行处理
html dom树中所有的对象都是节点,包括文本,所以 text()其实就是获取某个标签下的文本节点
通过_Element对象的 xpath方法来使用 xpath
注意!!!_Element.xpath( path) 总是返回一个列表
以上是“python爬虫系列之xpath是什么”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





