java中的二叉树是什么?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
定义
树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构,很象自然界中的树那样。树结构在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构都可用树形象表示。树在计算机领域中也得到广泛应用,如在编译源程序如下时,可用树表示源源程序如下的语法结构。又如在数据库系统中,树型结构也是信息的重要组织形式之一。一切具有层次关系的问题都可用树来描述。满二叉树,完全二叉树,排序二叉树。
深度优先遍历
一般我们深度优先遍历二叉树有三种最常见的顺序遍历:前序、中序、后序。
前序的遍历顺序为:访问根结点 -> 遍历左子树 -> 遍历右子树
中序的遍历顺序为:遍历左子树 -> 访问根结点 -> 遍历右子树
后序的遍历顺序为:遍历左子树 -> 遍历右子树 -> 访问根结点
注意这里的左右是整个子树,而不是一个结点,因为我们需要遍历整棵树,所以每次遍历都是按照这个顺序去执行,直到叶子结点。
举个例子,假如有如下二叉树:
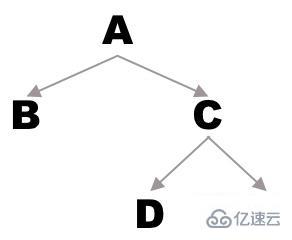
前序遍历得到的序列就是 A - B - C - D - E
中序遍历得到的序列就是 B - A - D - C - E
后序遍历得到的序列就是 B - D - E - C - A
思路我们就用前序遍历来讲(非常不建议去人肉递归,至少我的脑子吃不消三层。。。):
第一层递归:
先访问根结点,所以输出根结点 A,然后遍历左子树(L1),再遍历右子树(R1);
第二层递归:
对于 L1,先访问根结点,所以输出此时的根结点 B,然后发现 B 的左右子树为空,结束递归;
对于 R1,先访问根结点,所以输出此时的根结点 C,然后遍历左子树(L2),再遍历右子树(R2);
第三层递归:
对于 L2,先访问根结点,所以输出此时的根结点 D,然后发现 D 的左右子树为空,结束递归;
对于 R2,先访问根结点,所以输出此时的根结点 E,然后发现 E 的左右子树为空,结束递归;
前中后序特征
根据前中后序的定义,其实我们不难发现有如下特征:
• 前序的第一个一定是 root 节点,后序的最后一个一定是 root 节点
• 每种排序的左子树和右子树分布都是有规律的
• 对于每一个子树都遵循上面两个规律的树

这些特征也就是定义中对顺序的表现。
各种推导
这边列举一下对于二叉树的遍历最基本的几个算法题:
• 给定二叉树得出其前/中/后序遍历的序列;
• 根据前序和中序推导后序(或者推导整颗二叉树);
• 根据后序和中序推导前序(或者推导整颗二叉树);
对于二叉树的遍历,前面也讲过,通常采用递归来做,对于递归,有模版可以直接套用:
public void recur(int level, int param) {
// terminator
if (level > MAX_LEVEL) {
// process result
return;
}
// process current logic
process(level, param);
// drill down
recur(level+1, newParam);
// restore current status
}这个是我这两天看极客时间的算法训练营中超哥(覃超)讲到的比较实用的小技巧(这个模版对于新手特别好),遵循上面的三步骤(如果有局部变量需要释放或者额外处理则第四步去做)能比较有条理的写出递归代码。
这里拿根据前序和中序推导后序来举例:
先初始化两个序列:
int[] preSequence = {1, 2, 3, 4, 5, 6, 7, 8, 9};
int[] inSequence = {2, 3, 1, 6, 7, 8, 5, 9, 4};通过上面说到的几个特征,我们已经可以找到最小重复子问题了,每次递归
根据前序的第一个结点值去匹配中序中该结点值所在的索引 i,这样我们就能得到索引 i 的前后两部份分别对应左右子树,接着分别去遍历这两个左右子树,然后输出当前前序的第一个结点值,也就是根结点。
根据自顶向下的程序设计方法,我们可以先写出如下初始递归调用:
List<Integer> result = new ArrayList<>();
preAndInToPost(0, 0, preSequence.length, preSequence, inSequence, result);第一个参数表示前序序列的第一个元素索引;
第二个参数表示中序序列的第一个元素索引;
第三个参数表示序列长度;
第四个参数表示前序序列;
第五个参数表示后序序列;
第六个参数用于保存结果;
先来考虑终止条件是什么,也就是什么时候结束递归,当我们的根结点为空的时候终止,对应这里就是序列长度为零的时候。
if (length == 0) {
return;
}接着考虑处理逻辑,也就是找到索引 i:
int i = 0;
while (inSequence[inIndex + i] != preSequence[preIndex]) {
i++;
}然后开始向下递归:
preAndInToPost(preIndex + 1, inIndex, i, preSequence, inSequence, result);
preAndInToPost(preIndex + i + 1, inIndex + i + 1, length - i - 1, preSequence, inSequence, result);
result.add(preSequence[preIndex]);因为推导的是后序序列,所以顺序如上,添加根结点的操作是在最后的。前三个参数如何得出来的呢,我们走一下第一次遍历就可以得出来。
前序序列的第一个结点 1 在中序序列中的索引为 2,此时
左子树的中序系列起始索引为总序列的第 1 个索引,长度为 2;
左子树的前序序列起始索引为总序列的第 2 个索引,长度为 2;
右子树的中序系列起始索引为总序列的第 3 个索引,长度为 length - 3;
右子树的前序序列起始索引为总序列的第 3 个索引,长度为 length - 3;
完整代码如下:
/**
* 根据前序和中序推导后序
*
* @param preIndex 前序索引
* @param inIndex 中序索引
* @param length 序列长度
* @param preSequence 前序序列
* @param inSequence 中序序列
* @param result 结果序列
*/
private void preAndInToPost(int preIndex, int inIndex, int length, int[] preSequence, int[] inSequence, List<Integer> result) {
if (length == 0) {
return;
}
int i = 0;
while (inSequence[inIndex + i] != preSequence[preIndex]) {
i++;
}
preAndInToPost(preIndex + 1, inIndex, i, preSequence, inSequence, result);
preAndInToPost(preIndex + i + 1, inIndex + i + 1, length - i - 1, preSequence, inSequence, result);
result.add(preSequence[preIndex]);
}看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



