本篇文章为大家展示了PHP如何实现爬虫,代码简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
文字信息
我们尝试获取表的信息,这里,我们就用某校的课表来代替:
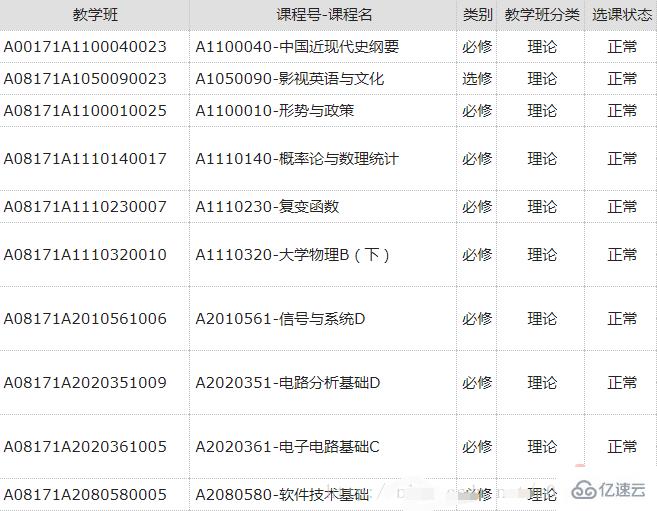
接下来我们就上代码:
a.php
<?php header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init(); $url ="表的链接";
curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch);
preg_match_all("/<td rowspan=\"\d\">(.*?)<\/td>\n<td rowspan=\"\d\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td>(.*?)<\/td>\n<td>(.*?)<\/td><td>(.*?)<\/td>/",$content,$matchs,PREG_SET_ORDER);//匹配该表所用的正则
var_dump($matchs);然后咱们就运行一下:

成功获取到课表;
图片获取
绝对链接
我们以百度图库的首页为例 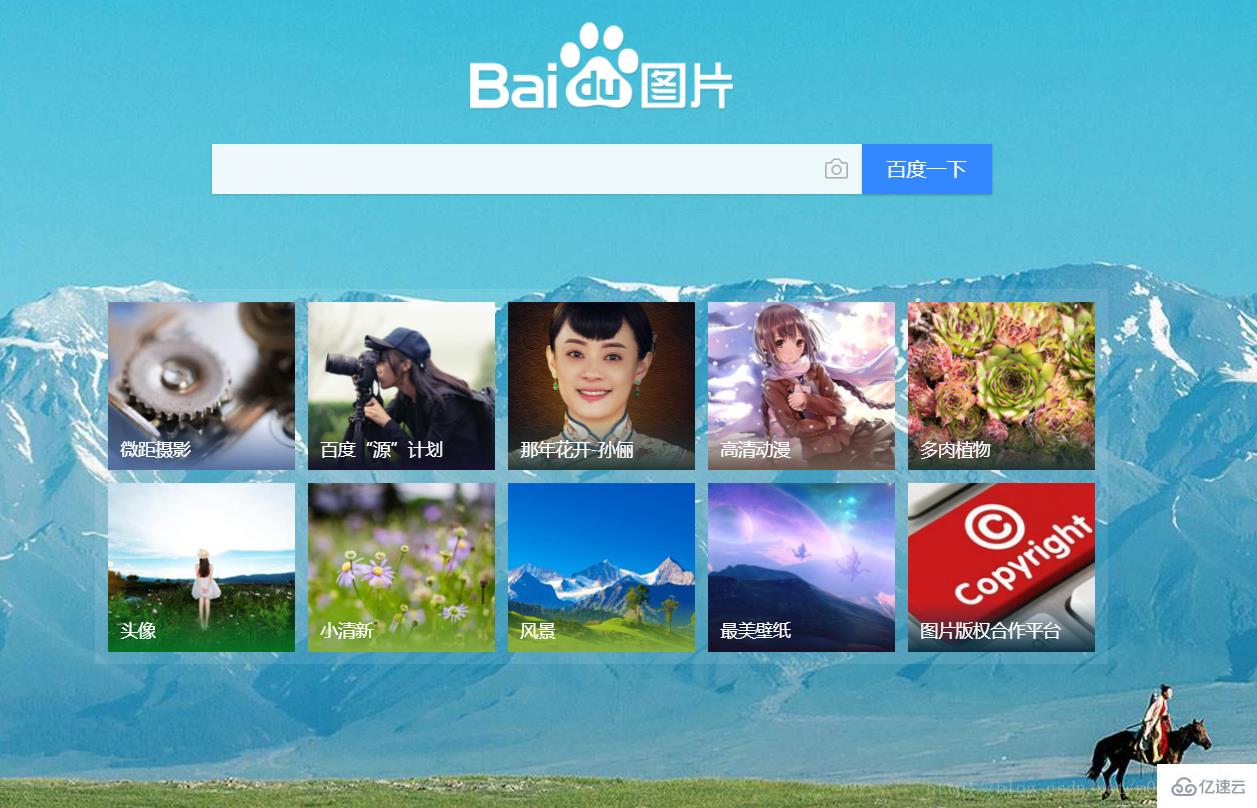
b.php
<?php header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init(); $url="http://image.baidu.com/";
curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); $string=file_get_contents($url);
preg_match_all("/<img([^>]*)\s*src=('|\")([^'\"]+)('|\")/",
$string,$matches); $new_arr=array_unique($matches[3]); foreach($new_arr as $key){
echo "<img src=$key>";
}然后,我们就获得了下面的页面: 
相对链接
百度图库的图片的链接大部分是绝对链接,那么当我们遇到网页图片为相对链接的时候,我们该怎么处理呢?其实很简单,我们只需要将循环那部分改为 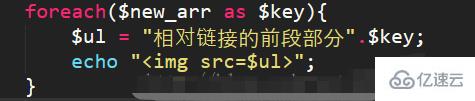
那么我们就可以同样在浏览器中输出图片了;
上述内容就是PHP如何实现爬虫,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





