ZeppelinпјҡдёҖдёӘеҲҶеёғејҸKVеӯҳеӮЁе№іеҸ°д№ӢжҰӮиҝ°
иҝҮеҺ»зҡ„дёҖе№ҙеӨҡзҡ„ж—¶й—ҙдёӯпјҢеӨ§йғЁеҲҶзҡ„е·ҘдҪңйғҪеӣҙз»•зқҖZeppelinиҝҷдёӘйЎ№зӣ®еұ•ејҖпјҢз»ҸеҺҶдәҶZeppelinзҡ„д»Һж— еҲ°жңүпјҢеҶҚеҲ°йҖҗжӯҘе®Ңе–„зЁіе®ҡгҖӮи§ҒиҜҒдәҶZeppelinзҡ„жҲҗй•ҝзҡ„еҗҢж—¶пјҢZeppelinд№ҹи§ҒиҜҒдәҶжҲ‘зҡ„з§ҜзҙҜиҝӣжӯҘгҖӮеҜ№жҲ‘иҖҢиЁҖпјҢZeppelinе°ұеғҸжҳҜеӯ©жҸҗж—¶д»ЈдёҖеҗҢй•ҝеӨ§зҡ„жңӢеҸӢпјҢеңЁж— ж•°ж¬Ўзҡ„жёёжҲҸе’Ңи°ҲиҜқдёӯпјҢдәӨжҚўеҜ№жңӘзҹҘдё–з•Ңзҡ„ж„ҹзҹҘпјҢзў°ж’һеҜ№жңӘжқҘзҡ„жҶ§жҶ¬пјҢ然еҗҺеҲ»з”»еҮәжӣҙеҘҪзҡ„еҪјжӯӨгҖӮиҝҷзҜҮеҚҡе®ўдёӯе°ұеҗ‘еӨ§е®¶д»Ӣз»ҚдёӢжҲ‘зҡ„иҝҷдҪҚиҖҒжңӢеҸӢгҖӮ
е®ҡдҪҚ
ZeppelinжҳҜдёҖдёӘеҲҶеёғејҸзҡ„KVеӯҳеӮЁе№іеҸ°пјҢеңЁи®ҫи®Ўд№ӢеҲқпјҢжҲ‘们еҜ№д»–жңүеҰӮдёӢеҮ дёӘдё»иҰҒжңҹи®ёпјҡ
Zeppelinзҡ„ж•ҙдёӘи®ҫи®Ўе’Ңе®һзҺ°йғҪеӣҙз»•иҝҷдёүдёӘзӣ®ж ҮеҠӘеҠӣпјҢжң¬ж–Үе°Ҷд»ҺAPIгҖҒж•°жҚ®еҲҶеёғгҖҒе…ғдҝЎжҒҜз®ЎзҗҶгҖҒдёҖиҮҙжҖ§гҖҒеүҜжң¬зӯ–з•ҘгҖҒж•°жҚ®еӯҳеӮЁгҖҒж•…йҡңжЈҖжөӢеҮ дёӘж–№йқўжқҘеҲҶеҲ«д»Ӣз»ҚгҖӮ
API
дёәдәҶи®©иҜ»иҖ…еҜ№ZeppelinжңүдёӘж•ҙдҪ“еҚ°иұЎпјҢе…Ҳд»Ӣз»ҚдёӢе…¶жҸҗдҫӣзҡ„жҺҘеҸЈпјҡ
ж•°жҚ®еҲҶеёғ
жңҖдёәдёҖдёӘеҲҶеёғејҸеӯҳеӮЁпјҢйҰ–иҰҒйңҖиҰҒи§ЈеҶізҡ„е°ұжҳҜж•°жҚ®еҲҶеёғзҡ„й—®йўҳгҖӮеҸҰдёҖзҜҮеҚҡе®ўжө…и°ҲеҲҶеёғејҸеӯҳеӮЁзі»з»ҹж•°жҚ®еҲҶеёғж–№жі•дёӯд»Ӣз»ҚдәҶеҸҜиғҪзҡ„ж•°жҚ®еҲҶеёғж–№жЎҲпјҢZeppelinйҖүжӢ©дәҶжҜ”иҫғзҒөжҙ»зҡ„еҲҶзүҮзҡ„ж–№ејҸпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
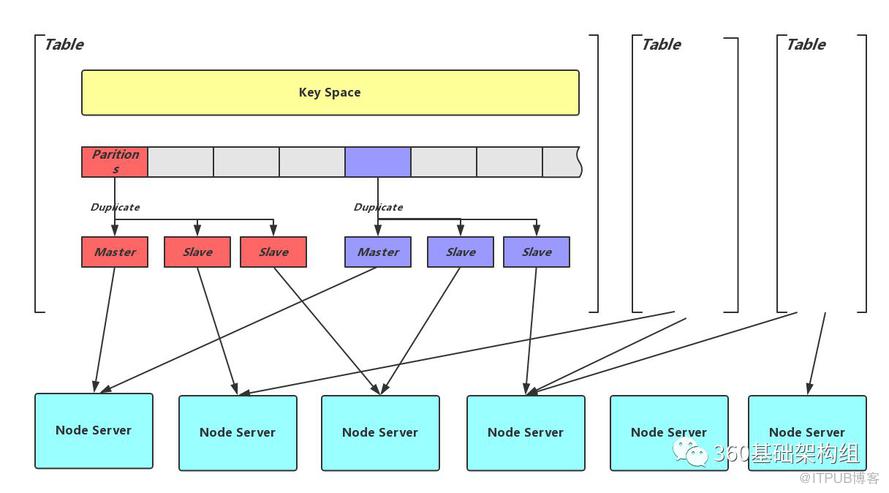
з”ЁйҖ»иҫ‘жҰӮеҝөTableеҢәеҲҶдёҡеҠЎпјҢ并е°ҶTableзҡ„ж•ҙдёӘKey SpaceеҲ’еҲҶдёәзӣёеҗҢеӨ§е°Ҹзҡ„еҲҶзүҮпјҲPartitionпјүпјҢжҜҸдёӘеҲҶзүҮзҡ„еӨҡеүҜжң¬еҲҶеҲ«еӯҳеӮЁеңЁдёҚеҗҢзҡ„еӯҳеӮЁиҠӮзӮ№пјҲNode ServerпјүдёҠпјҢеӣ иҖҢпјҢжҜҸдёӘNode ServerйғҪдјҡжүҝиҪҪеӨҡдёӘPartitionзҡ„дёҚеҗҢеүҜжң¬гҖӮPartitionдёӘж•°еңЁTableеҲӣе»әж—¶зЎ®е®ҡпјҢжӣҙеӨҡзҡ„Partitionж•°дјҡеёҰжқҘжӣҙеҘҪзҡ„ж•°жҚ®еқҮиЎЎж•ҲжһңпјҢжҸҗдҫӣжү©еұ•еҲ°жӣҙеӨ§йӣҶзҫӨзҡ„еҸҜиғҪпјҢдҪҶд№ҹдјҡеёҰжқҘе…ғдҝЎжҒҜиҶЁиғҖзҡ„еҺӢеҠӣгҖӮе®һзҺ°дёҠпјҢPartitionеҸҲжҳҜж•°жҚ®еӨҮд»ҪгҖҒж•°жҚ®иҝҒ移гҖҒж•°жҚ®еҗҢжӯҘзҡ„жңҖе°ҸеҚ•дҪҚпјҢеӣ жӯӨжӣҙеӨҡзҡ„PartitionеҸҜиғҪеёҰжқҘжӣҙеӨҡзҡ„иө„жәҗеҺӢеҠӣгҖӮZeppelinзҡ„и®ҫи®Ўе®һзҺ°дёҠд№ҹдјҡе°ҪйҮҸйҷҚдҪҺиҝҷз§ҚеҪұе“ҚгҖӮ
еҸҜд»ҘзңӢеҮәпјҢеҲҶзүҮзҡ„ж–№ејҸе°Ҷж•°жҚ®еҲҶеёғй—®йўҳжӢҶеҲҶдёәдёӨеұӮйҡҗе°„пјҡд»ҺKeyеҲ°Partitionзҡ„жҳ е°„еҸҜд»Ҙз®ҖеҚ•зҡ„з”ЁHashе®һзҺ°гҖӮиҖҢPartitionеүҜжң¬еҲ°еӯҳеӮЁиҠӮзӮ№зҡ„жҳ е°„зӣёеҜ№жҜ”иҫғеӨҚжқӮпјҢйңҖиҰҒиҖғиҷ‘зЁіе®ҡжҖ§гҖҒеқҮиЎЎжҖ§гҖҒиҠӮзӮ№ејӮжһ„еҸҠж•…йҡңеҹҹйҡ”зҰ»пјҲжӣҙеӨҡи®Ёи®әи§Ғжө…и°ҲеҲҶеёғејҸеӯҳеӮЁзі»з»ҹж•°жҚ®еҲҶеёғж–№жі•пјүгҖӮе…ідәҺиҝҷдёҖеұӮжҳ е°„пјҢZeppelinзҡ„е®һзҺ°еҸӮиҖғдәҶCRUSHеҜ№еүҜжң¬ж•…йҡңеҹҹзҡ„еұӮзә§з»ҙжҠӨж–№ејҸпјҢдҪҶж‘ҲејғдәҶCRUSHеҜ№йҷҚдҪҺе…ғдҝЎжҒҜйҮҸзЁҚжҳҫеҒҸжү§зҡ„иҝҪжұӮгҖӮ
еңЁиҝӣиЎҢеҲӣе»әTableгҖҒжү©е®№гҖҒзј©е®№зӯүйӣҶзҫӨеҸҳеҢ–зҡ„ж“ҚдҪңж—¶пјҢз”ЁжҲ·йңҖиҰҒжҸҗдҫӣж•ҙдёӘпјҡ
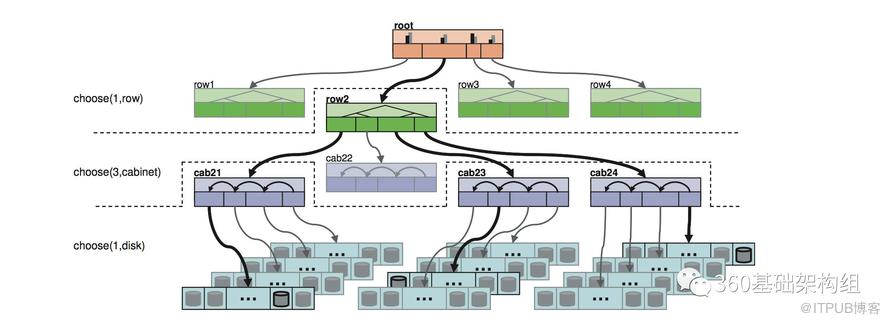
Zeppelinж №жҚ®иҝҷдәӣдҝЎжҒҜеҸҠеҪ“еүҚзҡ„ж•°жҚ®еҲҶеёғзӣҙжҺҘи®Ўз®—еҮәе®Ңж•ҙзҡ„зӣ®ж Үж•°жҚ®еҲҶеёғпјҢиҝҷдёӘиҝҮзЁӢдјҡе°ҪйҮҸдҝқиҜҒж•°жҚ®еқҮиЎЎеҸҠйңҖиҰҒзҡ„еүҜжң¬ж•…йҡңеҹҹгҖӮдёӢеӣҫдёҫдҫӢеұ•зӨәдәҶпјҢеүҜжң¬еңЁжңәжһ¶пјҲcabinetпјүзә§еҲ«йҡ”зҰ»зҡ„规еҲҷеҸҠеҲҶеёғж–№ејҸгҖӮжӣҙиҜҰз»Ҷзҡ„д»Ӣз»Қи§ҒDecentralized Placement of Replicated Data
е…ғдҝЎжҒҜз®ЎзҗҶ
дёҠйқўзЎ®е®ҡдәҶеҲҶзүҮзҡ„ж•°жҚ®еҲҶеёғж–№ејҸпјҢеҸҜд»ҘзңӢеҮәпјҢеҢ…жӢ¬еҗ„дёӘеҲҶзүҮеүҜжң¬зҡ„еҲҶеёғжғ…еҶөеңЁеҶ…зҡ„е…ғдҝЎжҒҜйңҖиҰҒеңЁж•ҙдёӘйӣҶзҫӨй—ҙе…ұдә«пјҢ并且еңЁеҸҳеҢ–ж—¶еҸҠж—¶жү©ж•ЈпјҢиҝҷе°ұж¶үеҸҠеҲ°дәҶе…ғдҝЎжҒҜз®ЎзҗҶзҡ„й—®йўҳпјҢйҖҡеёёжңүдёӨз§Қж–№ејҸпјҡ
жңүдёӯеҝғзҡ„е…ғдҝЎжҒҜз®ЎзҗҶпјҡз”ұдёӯеҝғиҠӮзӮ№жқҘиҙҹиҙЈж•ҙдёӘйӣҶзҫӨе…ғдҝЎжҒҜзҡ„жЈҖжөӢгҖҒжӣҙж–°е’Ңз»ҙжҠӨпјҢиҝҷз§Қж–№ејҸзҡ„дјҳзӮ№жҳҜи®ҫи®Ўз®ҖжҙҒжё…жҷ°пјҢе®№жҳ“е®һзҺ°пјҢдё”е…ғдҝЎжҒҜдј ж’ӯжҖ»йҮҸзӣёеҜ№иҫғе°Ҹ并且еҸҠж—¶гҖӮжңҖеӨ§зҡ„зјәзӮ№е°ұжҳҜдёӯеҝғиҠӮзӮ№зҡ„еҚ•зӮ№ж•…йҡңгҖӮд»ҘBigTableе’ҢCephдёәд»ЈиЎЁгҖӮ
еҜ№зӯүзҡ„е…ғдҝЎжҒҜз®ЎзҗҶпјҡе°ҶйӣҶзҫӨе…ғдҝЎжҒҜзҡ„еӨ„зҗҶиҙҹжӢ…еҲҶж•ЈеҲ°йӣҶзҫӨзҡ„жүҖжңүиҠӮзӮ№дёҠеҺ»пјҢиҠӮзӮ№й—ҙең°дҪҚдёҖиҮҙгҖӮе…ғдҝЎжҒҜеҸҳеҠЁж—¶йңҖиҰҒйҮҮз”ЁGossipзӯүеҚҸи®®жқҘдј ж’ӯпјҢйҷҗеҲ¶дәҶйӣҶзҫӨ规模гҖӮиҖҢж— еҚ•зӮ№ж•…йҡңе’ҢиҫғеҘҪзҡ„ж°ҙе№іжү©еұ•иғҪеҠӣжҳҜе®ғзҡ„дё»иҰҒдјҳзӮ№гҖӮDynamoе’ҢRedis ClusterйҮҮз”Ёзҡ„жҳҜиҝҷз§Қж–№ејҸгҖӮ
иҖғиҷ‘еҲ°еҜ№еӨ§йӣҶзҫӨзӣ®ж Үзҡ„йңҖжұӮпјҢZeppelinйҮҮз”ЁдәҶжңүдёӯеҝғиҠӮзӮ№зҡ„е…ғдҝЎжҒҜз®ЎзҗҶж–№ејҸгҖӮе…¶ж•ҙдҪ“з»“жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡ
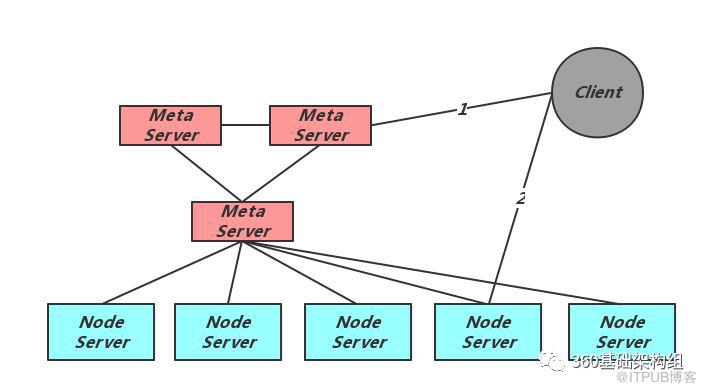
еҸҜд»ҘзңӢеҮәZeppelinжңүдёүдёӘдё»иҰҒзҡ„и§’иүІпјҢе…ғдҝЎжҒҜиҠӮзӮ№Meta ServerгҖҒеӯҳеӮЁиҠӮзӮ№Node ServerеҸҠClientгҖӮMetaиҙҹиҙЈе…ғдҝЎжҒҜзҡ„з»ҙжҠӨгҖҒNodeзҡ„еӯҳжҙ»жЈҖжөӢеҸҠе…ғдҝЎжҒҜеҲҶеҸ‘пјӣNodeиҙҹиҙЈе®һйҷ…зҡ„ж•°жҚ®еӯҳеӮЁпјӣClientзҡ„йҰ–ж¬Ўи®ҝй—®йңҖиҰҒе…Ҳд»ҺMetaиҺ·еҫ—еҪ“еүҚйӣҶзҫӨзҡ„е®Ңж•ҙж•°жҚ®еҲҶеёғдҝЎжҒҜпјҢеҜ№жҜҸдёӘз”ЁжҲ·иҜ·жұӮи®Ўз®—жӯЈзЎ®зҡ„NodeдҪҚзҪ®пјҢ并еҸ‘иө·зӣҙжҺҘиҜ·жұӮгҖӮ
дёәдәҶеҮҸиҪ»дёҠйқўжҸҗеҲ°зҡ„дёӯеҝғиҠӮзӮ№зҡ„еҚ•зӮ№й—®йўҳгҖӮжҲ‘们йҮҮеҸ–дәҶеҰӮдёӢзӯ–з•Ҙпјҡ
Meta Serverд»ҘйӣҶзҫӨзҡ„ж–№ејҸжҸҗдҫӣжңҚеҠЎпјҢд№Ӣй—ҙд»ҘдёҖиҮҙжҖ§з®—жі•жқҘдҝқиҜҒж•°жҚ®жӯЈзЎ®гҖӮ
иүҜеҘҪзҡ„Metaи®ҫи®ЎпјҡеҢ…жӢ¬дёҖиҮҙжҖ§ж•°жҚ®зҡ„延иҝҹжҸҗдәӨпјӣйҖҡиҝҮLeaseи®©FollowerеҲҶжӢ…иҜ»иҜ·жұӮпјӣзІ—зІ’еәҰзҡ„еҲҶеёғејҸй”Ғе®һзҺ°пјӣеҗҲзҗҶзҡ„жҢҒд№…еҢ–еҸҠдёҙж—¶ж•°жҚ®еҲ’еҲҶзӯүгҖӮжӣҙиҜҰз»Ҷзҡ„д»Ӣз»Қи§ҒпјҡZeppelinдёҚжҳҜйЈһиүҮд№Ӣе…ғдҝЎжҒҜиҠӮзӮ№
жҷәиғҪClientпјҡClientжүҝжӢ…жӣҙеӨҡзҡ„иҙЈд»»пјҢжҜ”еҰӮзј“еӯҳе…ғдҝЎжҒҜпјӣз»ҙжҠӨеҲ°Node Serverзҡ„й“ҫжҺҘпјӣи®Ўз®—ж•°жҚ®еҲҶеёғзҡ„еҲқе§ӢеҸҠеҸҳеҢ–гҖӮ
Node ServerеҲҶжӢ…жӣҙеӨҡиҙЈд»»пјҡеҰӮе…ғдҝЎжҒҜжӣҙж–°з”ұеӯҳеӮЁиҠӮзӮ№еҸ‘иө·пјӣйҖҡиҝҮMOVEпјҢWAITзӯүдҝЎжҒҜпјҢе®һзҺ°е…ғдҝЎжҒҜеҸҳеҢ–ж—¶зҡ„е®ўжҲ·з«ҜиҜ·жұӮйҮҚе®ҡеҗ‘пјҢеҮҸиҪ»MetaеҺӢеҠӣгҖӮжӣҙиҜҰз»Ҷзҡ„д»Ӣз»Қи§ҒпјҡZeppelinдёҚжҳҜйЈһиүҮд№ӢеӯҳеӮЁиҠӮзӮ№
йҖҡиҝҮдёҠйқўеҮ дёӘж–№йқўзҡ„зӯ–з•Ҙи®ҫи®ЎпјҢе°ҪйҮҸзҡ„йҷҚдҪҺеҜ№дёӯеҝғиҠӮзӮ№зҡ„дҫқиө–гҖӮеҚідҪҝMetaйӣҶзҫӨж•ҙдёӘејӮеёёж—¶пјҢе·Іжңүзҡ„е®ўжҲ·з«ҜиҜ·жұӮдҫқ然иғҪжӯЈеёёиҝӣиЎҢгҖӮ
дёҖиҮҙжҖ§
дёҠйқўе·Із»ҸжҸҗеҲ°пјҢдёӯеҝғе…ғдҝЎжҒҜMetaиҠӮзӮ№д»ҘйӣҶзҫӨзҡ„ж–№ејҸиҝӣиЎҢжңҚеҠЎгҖӮиҝҷе°ұйңҖиҰҒдёҖиҮҙжҖ§з®—жі•жқҘдҝқиҜҒпјҡ
еҚідҪҝеҸ‘з”ҹзҪ‘з»ңеҲҶеҢәжҲ–иҠӮзӮ№ејӮеёёпјҢж•ҙдёӘйӣҶзҫӨдҫқ然иғҪеӨҹеғҸеҚ•жңәдёҖж ·жҸҗдҫӣдёҖиҮҙзҡ„жңҚеҠЎпјҢеҚідёӢдёҖж¬Ўзҡ„жҲҗеҠҹж“ҚдҪңеҸҜд»ҘзңӢеҲ°д№ӢеүҚзҡ„жүҖжңүжҲҗеҠҹж“ҚдҪңжҢүйЎәеәҸе®ҢжҲҗгҖӮ
ZeppelinдёӯйҮҮз”ЁдәҶжҲ‘们зҡ„дёҖиҮҙжҖ§еә“FloydжқҘе®ҢжҲҗиҝҷдёҖзӣ®ж ҮпјҢFloydжҳҜRaftзҡ„C++е®һзҺ°гҖӮжӣҙеӨҡеҶ…е®№еҸҜд»ҘеҸӮиҖғпјҡRaftе’Ңе®ғзҡ„дёүдёӘеӯҗй—®йўҳгҖӮ
еҲ©з”ЁдёҖиҮҙжҖ§еҚҸи®®пјҢMetaйӣҶзҫӨйңҖиҰҒе®ҢжҲҗNodeиҠӮзӮ№зҡ„еӯҳжҙ»жЈҖжөӢгҖҒе…ғдҝЎжҒҜжӣҙж–°еҸҠе…ғдҝЎжҒҜжү©ж•Јзӯүд»»еҠЎгҖӮиҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢз”ұдәҺдёҖиҮҙжҖ§з®—жі•зҡ„жҖ§иғҪзӣёеҜ№иҫғдҪҺпјҢжҲ‘们йңҖиҰҒжҺ§еҲ¶еҶҷе…ҘдёҖиҮҙжҖ§еә“зҡ„ж•°жҚ®пјҢеҸӘеҶҷе…ҘйҮҚиҰҒгҖҒдёҚжҳ“жҒўеӨҚдё”дҝ®ж”№йў‘еәҰиҫғдҪҺзҡ„ж•°жҚ®гҖӮ
еүҜжң¬зӯ–з•Ҙ
дёәдәҶе®№й”ҷпјҢйҖҡеёёйҮҮз”Ёж•°жҚ®дёүеүҜжң¬зҡ„ж–№ејҸпјҢеҸҲз”ұдәҺеҜ№й«ҳжҖ§иғҪзҡ„е®ҡдҪҚпјҢжҲ‘们йҖүжӢ©дәҶMasterпјҢSlaveзҡ„еүҜжң¬зӯ–з•ҘгҖӮжҜҸдёӘPartitionеҢ…еҗ«иҮіе°‘дёүдёӘеүҜжң¬пјҢе…¶дёӯдёҖдёӘдёәMasterпјҢе…¶дҪҷдёәSlaveгҖӮжүҖжңүзҡ„з”ЁжҲ·иҜ·жұӮз”ұMasterеүҜжң¬иҙҹиҙЈпјҢиҜ»еҶҷеҲҶзҰ»зҡ„еңәжҷҜе…Ғи®ёSlaveд№ҹжҸҗдҫӣиҜ»жңҚеҠЎгҖӮMasterеӨ„зҗҶзҡ„еҶҷиҜ·жұӮдјҡеңЁдҝ®ж”№DBеҗҺеҶҷBinlogпјҢ并ејӮжӯҘзҡ„е°ҶBinlogеҗҢжӯҘз»ҷSlaveгҖӮ

дёҠеӣҫжүҖзӨәзҡ„жҳҜMasterпјҢSlaveд№Ӣй—ҙе»әз«Ӣдё»д»Һе…ізі»зҡ„иҝҮзЁӢпјҢеҸіиҫ№дёәSlaveгҖӮеҪ“е…ғдҝЎжҒҜеҸҳеҢ–ж—¶пјҢNodeд»ҺMetaжӢүеҸ–жңҖж–°зҡ„е…ғдҝЎжҒҜпјҢеҸ‘зҺ°иҮӘе·ұжҳҜжҹҗдёӘPartitionж–°зҡ„Slaveж—¶пјҢе°ҶTrySyncд»»еҠЎйҖҡиҝҮBufferдәӨз»ҷTrySync MoudleпјӣTrySync Moudleеҗ‘Masterзҡ„Command ModuleеҸ‘иө·TrysyncпјӣMasterз”ҹжҲҗBinlog Sendд»»еҠЎеҲ°Send Task PoolпјӣBinlog Send Moduleеҗ‘SlaveеҸ‘йҖҒBinlogпјҢе®ҢжҲҗж•°жҚ®ејӮжӯҘеӨҚеҲ¶гҖӮжӣҙиҜҰз»ҶеҶ…е®№и§ҒпјҡZeppelinдёҚжҳҜйЈһиүҮд№ӢеӯҳеӮЁиҠӮзӮ№гҖӮжңӘжқҘд№ҹиҖғиҷ‘ж”ҜжҢҒQuorumеҸҠECзҡ„еүҜжң¬ж–№ејҸжқҘж»Ўи¶ідёҚеҗҢзҡ„дҪҝз”ЁеңәжҷҜгҖӮ
ж•°жҚ®еӯҳеӮЁ
Node ServerжңҖз»ҲйңҖиҰҒе®ҢжҲҗж•°жҚ®зҡ„еӯҳеӮЁеҸҠжҹҘиҜўзӯүж“ҚдҪңгҖӮZeppelinзӣ®еүҚйҮҮз”ЁдәҶRocksdbдҪңдёәеӯҳеӮЁеј•ж“ҺпјҢжҜҸдёӘPartitionеүҜжң¬йғҪдјҡеҚ жңүзӢ¬з«Ӣзҡ„Rocksdbе®һдҫӢгҖӮйҮҮз”ЁLSMж–№жЎҲд№ҹжҳҜдёәдәҶеҜ№й«ҳжҖ§иғҪзҡ„иҝҪжұӮпјҢзӣёеҜ№дәҺB+TreeпјҢLSMйҖҡиҝҮе°ҶйҡҸжңәеҶҷиҪ¬жҚўдёәйЎәеәҸеҶҷеӨ§е№…жҸҗеҚҮдәҶеҶҷжҖ§иғҪпјҢеҗҢж—¶пјҢйҖҡиҝҮеҶ…еӯҳзј“еӯҳдҝқиҜҒдәҶзӣёеҜ№дёҚй”ҷзҡ„иҜ»жҖ§иғҪгҖӮеә–дёҒи§ЈLevelDBд№ӢжҰӮи§Ҳдёӯд»ҘLevelDBдёәдҫӢд»Ӣз»ҚдәҶLSMзҡ„и®ҫи®Ўе’Ңе®һзҺ°гҖӮ
然иҖҢпјҢеңЁж•°жҚ®ValueиҫғеӨ§зҡ„еңәжҷҜдёӢпјҢLSMеҶҷж”ҫеӨ§й—®йўҳдёҘйҮҚгҖӮдёәдәҶй«ҳжҖ§иғҪпјҢZeppelinеӨ§еӨҡйҮҮз”ЁSSDзӣҳпјҢSSDзҡ„йҡҸжңәеҶҷе’ҢйЎәеәҸеҶҷд№Ӣй—ҙзҡ„е·®и·қ并дёҚеғҸжңәжў°зӣҳйӮЈд№ҲеӨ§пјҢеҗҢж—¶SSDеҸҲжңүж“ҰйҷӨеҜҝе‘Ҫзҡ„й—®йўҳпјҢеӣ жӯӨLSMйҖҡиҝҮеӨҡж¬ЎйҮҚеӨҚеҶҷжҚўжқҘзҡ„й«ҳжҖ§иғҪдјҳеҠҝдёҚеӨӘеҲ’з®—гҖӮиҖҢZeppelinйңҖиҰҒеҜ№дёҠеұӮдёҚеҗҢеҚҸи®®зҡ„ж”Ҝж’‘пјҢеҸҲдёҚеҸҜйҒҝе…Қзҡ„дјҡеҮәзҺ°еӨ§ValueпјҢLSM upon SSDй’ҲеҜ№иҝҷж–№йқўеҒҡдәҶжӣҙеӨҡзҡ„и®Ёи®әпјҢеҢ…жӢ¬иҝҷз§Қж”№иҝӣеңЁеҶ…зҡ„е…¶д»–й’ҲеҜ№дёҚеҗҢеңәжҷҜзҡ„еӯҳеӮЁеј•ж“ҺеҸҠеҸҜжҸ’жӢ”зҡ„и®ҫи®Ўд№ҹжҳҜZeppelinжңӘжқҘзҡ„еҸ‘еұ•ж–№еҗ‘гҖӮ
ж•…йҡңжЈҖжөӢ
дёҖдёӘеҘҪзҡ„ж•…йҡңжЈҖжөӢзҡ„жңәеҲ¶еә”иҜҘиғҪеҒҡеҲ°еҰӮдёӢеҮ зӮ№пјҡ
еҸҠж—¶пјҡиҠӮзӮ№еҸ‘з”ҹејӮеёёеҰӮе®•жңәжҲ–зҪ‘з»ңдёӯж–ӯж—¶пјҢйӣҶзҫӨеҸҜд»ҘеңЁеҸҜжҺҘеҸ—зҡ„ж—¶й—ҙиҢғеӣҙеҶ…ж„ҹзҹҘпјӣ
йҖӮеҪ“зҡ„еҺӢеҠӣпјҡеҢ…жӢ¬еҜ№иҠӮзӮ№зҡ„еҺӢеҠӣпјҢе’ҢеҜ№зҪ‘з»ңзҡ„еҺӢеҠӣпјӣ
е®№еҝҚзҪ‘з»ңжҠ–еҠЁ
жү©ж•ЈжңәеҲ¶пјҡиҠӮзӮ№еӯҳжҙ»зҠ¶жҖҒж”№еҸҳеҜјиҮҙзҡ„е…ғдҝЎжҒҜеҸҳеҢ–йңҖиҰҒйҖҡиҝҮжҹҗз§ҚжңәеҲ¶жү©ж•ЈеҲ°ж•ҙдёӘйӣҶзҫӨпјӣ
Zeppelin дёӯзҡ„ж•…йҡңеҸҜиғҪеҸ‘з”ҹеңЁе…ғдҝЎжҒҜиҠӮзӮ№йӣҶзҫӨжҲ–еӯҳеӮЁиҠӮзӮ№йӣҶзҫӨпјҢе…ғдҝЎжҒҜиҠӮзӮ№йӣҶзҫӨзҡ„ж•…йҡңжЈҖжөӢдҫқиө–дёӢеұӮзҡ„Floydзҡ„Raftе®һзҺ°пјҢ并且еңЁдёҠеұӮйҖҡиҝҮJeopardyйҳ¶ж®өжқҘе®№еҝҚжҠ–еҠЁгҖӮжӣҙиҜҰз»ҶеҶ…е®№и§ҒпјҡZeppelinдёҚжҳҜйЈһиүҮд№Ӣе…ғдҝЎжҒҜиҠӮзӮ№гҖӮ
иҖҢеӯҳеӮЁиҠӮзӮ№зҡ„ж•…йҡңжЈҖжөӢз”ұе…ғдҝЎжҒҜиҠӮзӮ№иҙҹиҙЈпјҢ ж„ҹзҹҘеҲ°ејӮеёёеҗҺпјҢе…ғдҝЎжҒҜиҠӮзӮ№йӣҶзҫӨдҝ®ж”№е…ғдҝЎжҒҜгҖҒжӣҙж–°е…ғдҝЎжҒҜзүҲжң¬еҸ·пјҢ并йҖҡиҝҮеҝғи·ійҖҡзҹҘжүҖжңүеӯҳеӮЁиҠӮзӮ№пјҢеӯҳеӮЁиҠӮзӮ№еҸ‘зҺ°е…ғдҝЎжҒҜеҸҳеҢ–еҗҺпјҢдё»еҠЁжӢүеҺ»жңҖж–°е…ғдҝЎжҒҜ并дҪңеҮәзӣёеә”ж”№еҸҳгҖӮ
жңҖеҗҺпјҢZeppelinиҝҳжҸҗдҫӣдәҶдё°еҜҢзҡ„иҝҗз»ҙгҖҒзӣ‘жҺ§ж•°жҚ®пјҢд»ҘеҸҠзӣёе…іе·Ҙе…·гҖӮж–№дҫҝйҖҡиҝҮPrometheusзӯүе·Ҙе…·зӣ‘жҺ§еұ•зӨәгҖӮ
зӣёе…і
[Zeppelin](https://github.com/Qihoo360/zeppelin)
[Floyd](https://github.com/Qihoo360/floyd)
[Raft](https://raft.github.io/)
[жө…и°ҲеҲҶеёғејҸеӯҳеӮЁзі»з»ҹж•°жҚ®еҲҶеёғж–№жі•](http://catkang.github.io/2017/12/17/data-placement.html)
[Decentralized Placement of Replicated Data](https://whoiami.github.io/DPRD)
[ZeppelinдёҚжҳҜйЈһиүҮд№Ӣе…ғдҝЎжҒҜиҠӮзӮ№](http://catkang.github.io/2018/01/19/zeppelin-meta.html)
[ZeppelinдёҚжҳҜйЈһиүҮд№ӢеӯҳеӮЁиҠӮзӮ№](http://catkang.github.io/2018/01/07/zeppelin-overview.html)
[Raftе’Ңе®ғзҡ„дёүдёӘеӯҗй—®йўҳ](http://catkang.github.io/2017/06/30/raft-subproblem.html)
[еә–дёҒи§ЈLevelDBд№ӢжҰӮи§Ҳ](http://catkang.github.io/2017/01/07/leveldb-summary.html)
[LSM upon SSD](http://catkang.github.io/2017/04/30/lsm-upon-ssd.htmlпјү
еҺҹж–Үй“ҫжҺҘпјҡhttps://mp.weixin.qq.com/s/cfMtQ1YAZiCId3OM7bxXrg





