这篇文章将为大家详细讲解有关如何用Python进行金融市场文本数据的情感计算,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
一、tushare介绍
tushare库是目前比较流行的开源免费的经济数据库,tushare有普通版和高级版,其中普通版无需积分就可以使用,而高级版需要使用积分才可使用。
tushare基础班提供了包括:
交易数据,如历史行情、复权数据、实时行情等
投资参考数据,如分配的方案、业绩预告、限售股解禁、基金持股、新浪数据、融资融券
股票分类数据、行业、概念、地域、中小板、创业板、封校警示板生
基本面数据、股票列表、业绩报告(主表)、盈利能力、营运能力、偿债能力等
宏观经济数据,如存款利率、贷款利率、GDP数据、工业品出场价格指数、居民消费节各直属
新闻事件数据,如新浪股吧
龙虎榜数据
银行间同业拆放理论
电影票房
安装
!pip3 install tushare
Run
Collecting tushare [? 25l Downloading https: //files.pythonhosted.org/packages/a9/8b/2695ad38548d474f4ffb9c95548df126e82adb24e56e2c4f7ce1ef9fbd01/tushare-1.2.43.tar.gz (168kB) [K 100 % |████████████████████████████████| 174kB 162kB /s ta : 00 : 01 [? 25hBuilding wheels for collected packages: tushare Running setup.py bdist_wheel for tushare ... [? 25ldone [? 25h Stored in directory: /Users/ thunderhit/ Library / Caches /pip/wheels/ 4b / 28 / 7b / 62d7a4155b34be251c1840e7cecfa4c374812819c59edba760 Successfully built tushare Installing collected packages: tushare Successfully installed tushare- 1.2 . 43 [ 33mYou are using pip version 18.1 , however version 19.2 . 3 is available. You should consider upgrading via the 'pip install --upgrade pip' command.[ 0m
二、新闻数据
新闻事件接口主要提供国内财经、证券、港股和期货方面的滚动新闻,以及个股的信息地lei数据。但目前只有新浪股吧api的接口可用,其他的需要使用tushare高级版。
获取sina财经股吧首页的重点消息。股吧数据目前获取大概17条重点数据,可根据参数设置是否显示消息内容,默认情况是不显示。
参数说明:
show_content:boolean,是否显示内容,默认False
返回值说明:
title, 消息标题
content, 消息内容(show_content=True的情况下)
ptime, 发布时间
rcounts,阅读次数
调用方法
import tushare as ts #显示详细内容 newsdata = ts.guba_sina(show_content= True ) newsdata.head( 10 )

三、读取词典
之前制作的中文金融情感词典是csv文件格式,我们使用pandas读取
import pandas as pd df = pd.read_csv( 'CFSD/pos.csv' , encoding= 'gbk' ) df.head()

我们将读取词典定义成函数
def read_dict(file, header): """ file: 词典路径 header: csv文件内字段名,如postive 读取csv词典,返回词语列表 """ df = pd.read_csv(file, encoding= 'gbk' ) return list(df[header]) poswords = read_dict(file= 'CFSD/pos.csv' , header = 'postive' ) negwords = read_dict(file= 'CFSD/neg.csv' , header = 'negative' ) negwords[: 5 ]
run
[ '闭门造车' , '闭塞' , '云里雾里' , '拖累' , '过热' ]
三、情感分析方法
这里我们对新闻content内容进行情感分析,分析的思路是统计content中正、负词的占比。我们会用到pandas的 df.agg(func)方法对content列进行文本计算。这需要先定义一个待调用的情感计算函数,注意有可能出现分母为0,所以定义的函数使用了try except捕捉0除异常,返回0.
import jieba def pos_senti(content): """ content: 待分析文本内容 返回正面词占文本总词语数的比例 """ try : pos_word_num = words = jieba.lcut(content) for kw in poswords: pos_word_num += words.count(kw) return pos_word_num/len(words) except : return def neg_senti(content): """ content: 待分析文本内容 返回负面词占文本总词语数的比例 """ try : neg_word_num = words = jieba.lcut(content) for kw in negwords: neg_word_num += words.count(kw) return neg_word_num/len(words) except : return 0
对content列分别施行情感计算函数possenti,negsenti,将得到的得分赋值给pos、neg列
newsdata[ 'pos' ]=newsdata[ 'content' ].agg(pos_senti) newsdata[ 'neg' ]=newsdata[ 'content' ].agg(neg_senti) newsdata.head( 10 )

我们的数据中出现了pos和neg两个得分,我们还可以定义一个判断函数,判断文本的情绪分类。
当pos比neg大,判断为'正'
当pos比neg小,判断为'负'
这里不严谨,为了教程简单,没考虑相等的情况
newsdata[
'senti_classification'
] = newsdata[
'pos'
]>newsdata[
'neg'
]
newsdata[
'senti_classification'
] = newsdata[
'senti_classification'
].map({
True
:
"正"
,
False
:
"负"
})
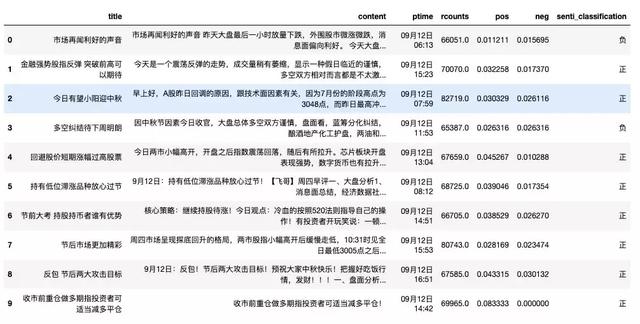
newsdata.head(
10
)
总结
其实到这儿,简单的情感计算就实现了。
另外,大家在使用本文时,一定要注意:
本篇Python学习教程使用的情感词典是CFSD中文金融情感词典,大家可以用自己领域的词典,得到poswords和negwords
还有要注意的是情感计算函数(possenti和negsenti),有不同的算法就有不同的结果
正负面倾向判断,我这里比较粗糙,没有考虑相等的中性问题。
注意以上几点,本篇Python学习教程代码就可复用。不过再好的代码,前提是得会python,会懂编程思维,知道如何写代码改代码,不然大家用起来也比较困难。
关于如何用Python进行金融市场文本数据的情感计算就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





