Kafka Connect如何实现同步RDS binlog数据,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
下面介绍如何在E-MapReduce上使用Kafka Connect实现同步RDS binlog数据
1. 背景
在我们的业务开发中,往往会碰到下面这个场景:
业务更新数据写到数据库中
业务更新数据需要实时传递给下游依赖处理
所以传统的处理架构可能会这样:
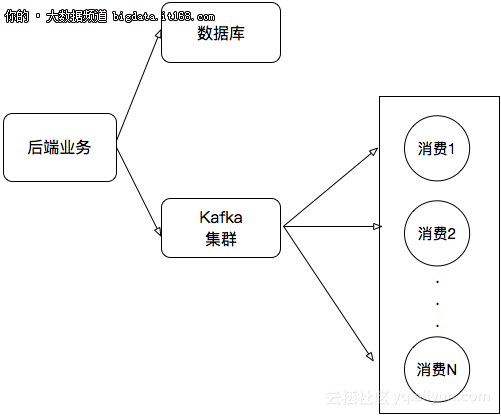
本文将演示如何在E-MapReduce上实现将RDS binlog实时同步到Kafka集群中。
2. 环境准备
实验中使用VPC网络环境,以下实例创建时默认都是在VPC环境下。
2.1 准备一个测试RDS数据库
创建一个RDS实例,版本选择5.7。这里不赘述如何创建RDS,详细流程请参考RDS文档。创建完如图:
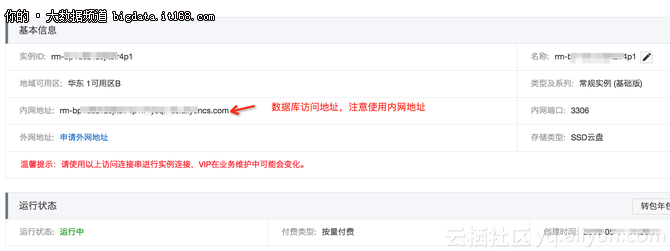
注意:RDS实例和E-MapReduce Kafka集群最好在同一个VPC中,否则需要打通两个VPC之间的网络。
3. Kafka Connect
3.1 Connector
Kafka Connect是一个用于Kafka和其他数据系统之间进行数据传输的工具,它可以实现基于Kafka的数据管道,打通上下游数据源。我们需要做的就是在Kafka Connect服务上运行一个Connector,这个Connector是具体实现如何从/向数据源中读/写数据。Confluent提供了很多Connector实现,你可以在这里下载。不过今天我们使用Debezium提供的一个MySQL Connector插件,下载地址。
下载这个插件,并将解压出来的jar包全部拷贝到kafka lib目录下。注意:需要将这些jar包拷贝到Kafka集群所有机器上。
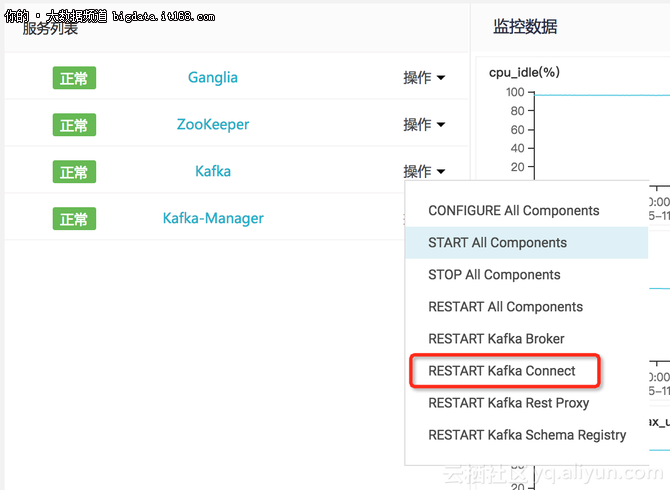
在Kafka集群的服务列表中重启Kafka Connect组件。
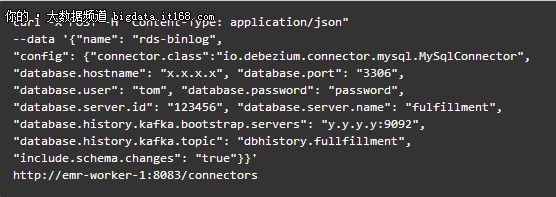
登录到Kafka集群,配置并创建一个connector,命令如下:
3.3 注意事项
server_id是多少?:你可以在RDS执行"SELECT @@server_id;"查到。
创建connector时可能会出现连接失败,请确保RDS的白名单已经授权了Kafka集群机器访问。
4 测试
4.1 创建一张表
插入几条数据

结果如图所示:

看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





