HA(High Available)即由两台计算机组成并对外提供一组相同的服务,也叫做一主一备模式。正常情况下由主服务器提供服务,备服务器处于待机备用,备机可以随时接替主服务器的工作。也就是当主服务器宕机或所提供的服务不可用时,备用服务器会主动激活并且替换主服务器继续提供服务,这时主服务器上的服务资源包括网络(IP)、存储、服务(Web/数据库)就会转移到备机接管,从而提供不间断的服务。基于此,便可以将服务器的宕机时间减少到最低,对业务实现不中断或短暂中断。
由一组计算机(多台)组成一个整体并向用户提供相同的网络资源或服务,这种模式叫做HA集群(High Available Cluster)。
Oracle HA高可用,又叫做双机热备,一般用于关键性业务。
Oracle双机热备模式
常用的有Data Guard、RAC(Real Application Clusters)、基于HA软件实现的双机热备。
l Data Guard采用重做日志复制技术,对主业务数据进行实时的异步同步备份,有一主一备、一主多备模式,一般常用于容灾(异地备份、灾难恢复);存储独立、数据完整备份;备机可以做数据分析、报表统计等;主备自由切换,能实现自动快速故障转移;备用角色强制转换为主用角色会破环Data Guard架构;设计复杂、维护难度大
l RAC多个实例同时运行,无主备概念,有集群负载功能,其中某一台down机,不影响整体服务,不存在故障切换时间,可以提供高性能服务;存储共享,由ASM管理存储;硬件成本低;设计简单、维护难度大
l HA双机热备可以提供高可用性,保证业务的持续稳定运行,可以实现自动快速故障转移,存在短暂的切换时间(10-30s)。一般用于关键性业务;存储共享;有商业的HA方案,也可以使用开源的高可用软件keepalved、heartbeat搭建实现HA方案;设计复杂、维护难度小
l HA双机和Data Guard
l Data Guard和RAC
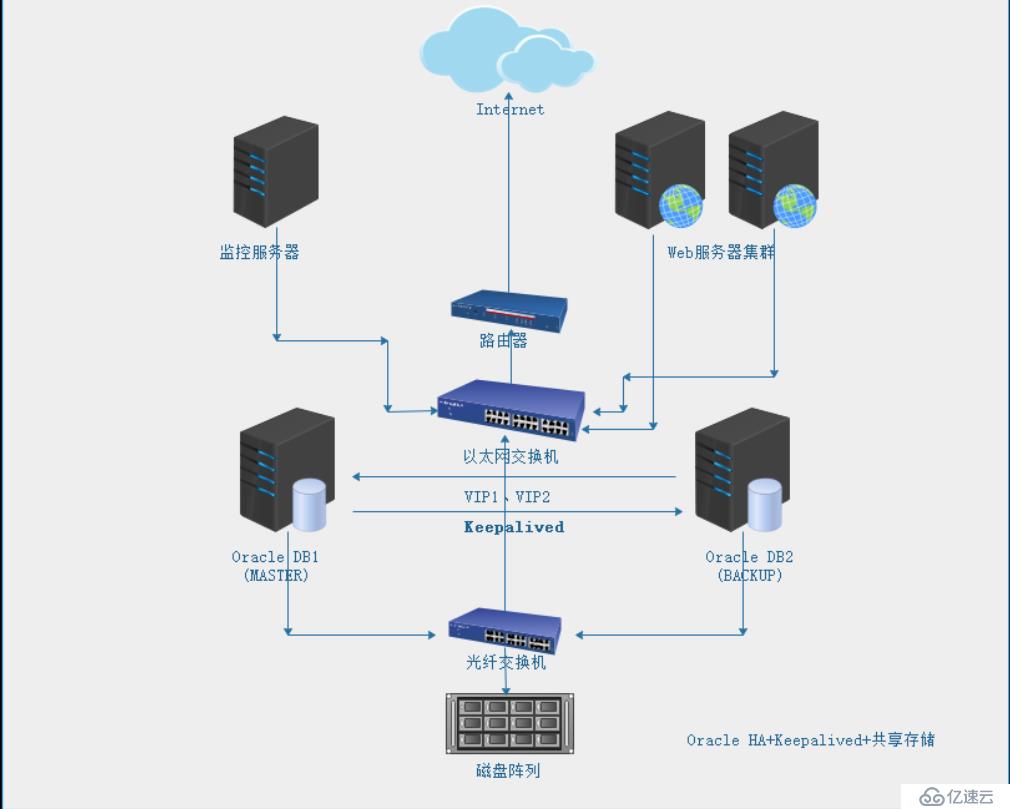
l Oracle HA双机热备+Keepalived
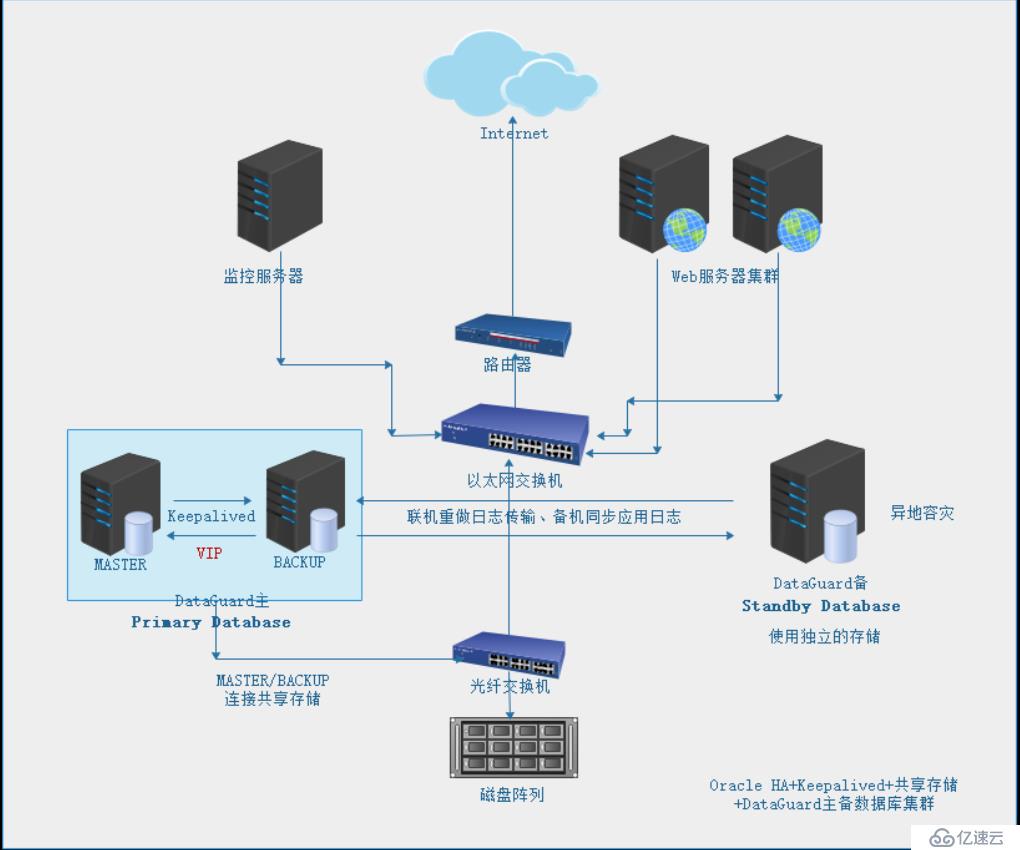
l Oracle HA双机+DataGuard+Keepalived集群
软件版本:
Orace 11g R2
Keepalived 1.3.2
主服务器: DB1
备服务器: DB2
Hostname | IP | OS | Role |
hmdg-db1 | 172.16.10.25 | CentOS6.9 | MASTER |
hmdg-db2 | 172.16.10.26 | CentOS6.9 | BACKUP |
VIP | 172.16.10.130、172.16.10.131 | ||
Share Disk | /dev/sdb1 mount on /oradata | ||
ORACLE_BASE | /u01/app/oracle | ||
ORACLE_HOME | /u01/app/oracle/product/11.2.0/db_1 | ||
ORACLE_SID | HMODB | ||
Datadir | /oradata/HMODB | ||
Controlfiles | /oradata/HMODB/control01.ctl, /u01/app/oracle/flash_recovery_area/HMODB/control02.ctl, /home/oracle/rman/HMODB/control03.ctl | ||
1、 同时在主备上安装Oracle数据库软件,数据库的安装目录和环境变量保持一致
2、 仅在主服务器上建立数据库实例(主服务器上挂载共享存储并使用DBCA新建库)
3、 主服务创建数据库实例后,将主库上的控制文件、参数文件(SPFILE)、以及密码文件传输到备用服务器上相应的目录
l 备用服务器DB2
##创建对应的数据库文件目录
[root@hmdg-db2 ~]# su - oracle
[oracle@hmdg-db2 ~]$ mkdir /u01/app/oracle/admin/HMODB
[oracle@hmdg-db2 ~]$ mkdir /u01/app/oracle/admin/HMODB/{adump,dpdump,pfile}
[oracle@hmdg-db2 ~]$ mkdir /u01/app/oracle/flash_recovery_area/HMODB
##密码文件
[oracle@hmdg-db2 ~]$ scp oracle@hmdg-db1:/u01/app/oracle/product/11.2.0/db_1/dbs/orapwHMODB /u01/app/oracle/product/11.2.0/db_1/dbs/orapwHMODB
##SPFILE参数文件
[oracle@hmdg-db2 ~]$ scp oracle@hmdg-db1:/u01/app/oracle/product/11.2.0/db_1/dbs/spfileHMODB.ora /u01/app/oracle/product/11.2.0/db_1/dbs/spfileHMODB.ora
##控制文件,仅需要将位于非共享存储的数据目录下的控制文件传输到其他磁盘或目录位置下
[oracle@hmdg-db2 ~]$ scp oracle@hmdg-db1:/u01/app/oracle/flash_recovery_area/HMODB/control02.ctl /u01/app/oracle/flash_recovery_area/HMODB/control02.ctl
[oracle@hmdg-db2 ~]$cp /u01/app/oracle/flash_recovery_area/HMODB/control02.ctl /home/oracle/rman/HMODB/control03.ctl1、 主服务器上关闭数据库实例
2、 主服务器上卸载共享存储
3、 备服务器上挂载共享存储
4、 备服务器上启动监听
5、 备服务器上启动数据库实例
注意:不要同时挂载共享存储启动数据库实例,否则会导致数据不一致
l 主服务器DB1
##关闭数据库实例 [oracle@hmdg-db1 ~]$ sqlplus / as sysdba SQL> shutdown immediate ##关闭数据库监听 [oracle@hmdg-db1 ~]$ lsnrctl stop ##卸载共享存储 [oracle@hmdg-db1 ~]$ umount /oradata
l 备服务器DB2
##挂载/dev/sdb1共享存储到/oradta下 [root@hmdg-db2 ~]# mount /dev/sdb1 /oradata/ ##启动数据库监听 [oracle@hmdg-db2 ~]$ lsnrctl start [oracle@hmdg-db2 ~]$ export ORACLE_SID=HMODB ##启动数据库实例 [oracle@hmdg-db2 ~]$ sqlplus / as sysdba SQL> startup ORACLE instance started. Total System Global Area 1603411968 bytes Fixed Size 2213776 bytes Variable Size 1056966768 bytes Database Buffers 536870912 bytes Redo Buffers 7360512 bytes Database mounted. Database opened. SQL> ##检验数据库 SQL> SHOW PARAMETER DB_NAME NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_name string HMODB SQL> SELECT OPEN_MODE,NAME,DATABASE_ROLE FROM V$DATABASE; OPEN_MODE NAME DATABASE_ROLE -------------------- --------- ---------------- READ WRITE HMODB PRIMARY
由于安装数据库实例时,创建了多个控制文件,并且这些控制文件都保存在不同的磁盘上,在主备进行切换的时,位于非共享存储的控制文件需要手动进行同步。这是由于在关闭数据库实例时Oracle同时将当前数据库状态信息记录到控制文件中,在没有启动数据库实例的备机就无法同步自身的其他的控制文件。这时就需要使用共享存储里的控制文件进行恢复。
1、 在DB2关闭正在运行数据库实例
##DB2: [oracle@hmdg-db2 ~]$ sqlplus / as sysdba SQL> shutdown immediate [root@hmdg-db2 ~]# umount /oradata/
2、在DB1上进行恢复启动数据库实例
##DB1: [root@hmdg-db1 ~]# mount /dev/sdb1 /oradata/ [oracle@hmdg-db1 ~]$ export ORACLE_SID=HMODB [oracle@hmdg-db1 ~]$ sqlpus / as sysdba SQL> startup nomount SQL> alter database mount; SQL> alter database open;
如果控制文件在不同的磁盘目录,那么就需要执行这一步恢复控制文件
[oracle@hmdg-db1 ~]$ rman target / RMAN> restore controlfile from '/oradata/HMODB/control01.ctl';
启动数据库监听
[oracle@hmdg-db1 ~]$ lsnrctl start
或者直接只有操作系统的cp、scp等命令进行拷贝恢复
[oracle@hmdg-db1 ~]$ cp /oradata/HMODB/control01.ctl /u01/app/oracle/flash_recovery_area/HMODB/control02.ctl SQL> SELECT NAME,OPEN_MODE,NAME,DATABASE_ROLE FROM V$DATABASE; NAME OPEN_MODE NAME DATABASE_ROLE --------- -------------------- --------- ---------------- HMODB READ WRITE HMODB PRIMARY
配置oracle用户的ssh密钥,用于主备通过oracle身份自动检测对方的数据共享存储状态。在keepalived脚本管理中自动检查对方的挂载状态,并在主备切换的过程中,待接管的服务器等待对方umount共享存储之后,正常启动数据库实例。(如果主服务异常关机或网络中断,不需要等待对方umount存储,主服务器异常关机时keepalived会即时检测到并自动切换到备机上)
[oracle@hmdg-db1 ~]$ ssh-keygen -t rsa -b 2048 [oracle@hmdg-db1 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub oracle@hmdg-db2 [oracle@hmdg-db2 ~]$ ssh-keygen -t rsa -b 2048 [oracle@hmdg-db2 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub oracle@hmdg-db1
添加主备防火墙互通规则
# iptables -I INPUT -p tcp -s 172.16.10.0/24 -j ACCEPT # iptables -I INPUT -p udp -s 172.16.10.0/24 -j ACCEPT
主服务器的keepalived配置,备用服务器需要做相应的修改
! Configuration File for keepalived
global_defs {
notification_email {
mail@huangming.org
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id ORACLE_HA_MASTER #backup为ORACLE_HA_BACKUP
!vrrp_skip_check_adv_addr
}
vrrp_sync_group ORACLE_HA_GROUP {
group {
Oracle_HA_1 #定义一个vrrp实例组
}
}
vrrp_script monitor_oracle_status { #oracle数据库服务器状态检查脚本
script "/usr/local/keepalived/scripts/monitor.sh"
interval 10 #脚本执行时间间隔
fall 3 #脚本执行的最大失败次数
rise 1 #脚本执行成功一次则返回正常状态
weight 20 #脚本执行成功时的附加权值
}
vrrp_script change_monitor_status { #服务器状态监控并修改主备检查脚本
script "/usr/local/keepalived/scripts/change_monitor_status.sh"
interval 2
}
vrrp_instance Oracle_HA_1 {
state BACKUP #主备都设置为BACKUP
interface eth2 #绑定vip的网络接口
virtual_router_id 200 #主备保存一致
priority 100 #备为90
advert_int 2 #主备状态同步时间间隔
nopreempt #主设置为不抢占模式
authentication {
auth_type PASS
auth_pass 11112222
}
virtual_ipaddress {
172.16.10.130/24 dev eth2 #需要绑定的VIP
172.16.10.131/24 dev eth2
}
track_script {
monitor_oracle_status
change_monitor_status
}
track_interface {
eth0 #同时监控检测其他的网接口
}
notify_master "/usr/local/keepalived/scripts/keepalived_notify.sh master"
notify_backup "/usr/local/keepalived/scripts/keepalived_notify.sh backup"
notify_fault "/usr/local/keepalived/scripts/keepalived_notify.sh fault"
notify_stop "/usr/local/keepalived/scripts/keepalived_notify.sh stop"
! notify管理脚本的定义
! 分别对应keepalived转换为master、backup、fault、stop状态时执行的脚本
! 在oracle的双机管理中主要是依赖这些脚本实现资源的接管
}[root@hmdg-db1 scripts]# ls -l /usr/local/keepalived/scripts/ -rwxr-xr-x 1 root root 818 Apr 14 20:13 change_monitor_status.sh -rw-r--r-- 1 root root 57 Apr 14 20:13 Controlfile.sql -rw-r--r-- 1 root root 1308 Apr 14 20:13 keepalived -rwxr-xr-x 1 root root 10549 Apr 14 23:18 keepalived_notify.sh -rwxr-xr-x 1 root root 926 Apr 14 23:12 monitor_primary_oracle.sh -rwxr-xr-x 1 root root 895 Apr 15 16:46 monitor.sh -rwxr-xr-x 1 root root 895 Apr 14 20:13 monitor_standby_oracle.sh -rw-r--r-- 1 root root 1657 Apr 15 15:13 oracle_init.sh -rwxr-xr-x 1 root root 8441 Apr 14 20:13 notify.sh_20180413
关于这些keepalived脚本,由于篇幅有限我没有全部贴到本文中,大家可以访问我的Github仓库找到:https://github.com/hmlinux/oracle-keepalived
l keepalived_notify.sh #keepalived的notify脚本,用于实现主备的资源自动切换
l monitor.sh #keepalved的监控脚本,监控oracle数据库运行状态、共享存储状态
l change_monitor_status.sh #异常或正常检测脚本,当备服务器处于正常运行状态,并且处于keepalived的BACKUP状态时,将自身的监控脚本修改为在备机就绪时执行都返回正常结果,主要作用时让正常的备机可以随时接管主服务器的资源
l monitor_primary_oracle.sh #处于MASTER状态时的服务器监控脚本
l monitor_standby_oracle.sh #处于BACKUP状态时的服务器监控脚本
l oracle_init.sh #notify脚本调用oracle启动、停止、状态检测命令
keepalived_notify.sh
#!/bin/bash # author: hm@huangming.org # keepalived notify script #bind vip interface interface="eth2" #keepalived virtual_ipaddress virtual_ipaddress="172.16.10.130","172.16.10.131" MASTER_HOSTNAME="hmdg-db1" #DB1 BACKUP_HOSTNAME="hmdg-db2" #DB2 LOGDIR="/usr/local/keepalived/log" LOGFILE="$LOGDIR/keepalived_haswitch.log" TMPLOG=/tmp/notify_.log sharedisk="/dev/sdb1" sharedisk_mount_point="/oradata" # oracle_datadir="/oradata/path/HMODB" oracle_datadir="/oradata" # Source oracle database instance startup/shutdown script . /usr/local/keepalived/scripts/oracle_init.sh control_files="/$oracle_datadir/$ORACLE_SID/control01.ctl","/u01/app/oracle/flash_recovery_area/$ORACLE_SID/control02.ctl","/home/oracle/rman/$ORACLE_SID/control03.ctl" RETVAL=0 OLD_IFS="$IFS" IFS="," [ -d $LOGDIR ] || mkdir $LOGDIR controlfile_backpath="/backup/oracle/control" controlfile_back=$controlfile_backpath/control_$(date '+%Y%d%m%H%M%S') [ -d $controlfile_backpath ] || mkdir -p $controlfile_backpath && chown -R oracle:oinstall $controlfile_backpath info_log() { printf "$(date '+%b %d %T %a') $HOSTNAME [keepalived_notify]: $1" } control01_ctl=`printf ${control_files[0]}` backup_controlfile() { su - oracle << EOF export ORACLE_SID=$ORACLE_SID $ORACLE_HOME/bin/sqlplus -S "/ as sysdba" alter database backup controlfile to '$controlfile_back'; exit EOF } #runuser -l oracle -c "export ORACLE_SID=$ORACLE_SID;rman target / cmdfile=/usr/scripts/ControlfileRestore.sql" restore_controlfile() { su - oracle << EOF export ORACLE_SID=$ORACLE_SID $ORACLE_HOME/bin/rman target / nocatalog RESTORE CONTROLFILE FROM '$control01_ctl'; exit EOF } ssh_p=$(netstat -ntp | awk '/sshd/{print $4}' | awk -F':' '{print $2}' | head -1) chk_remote_node_sharedisk() { if [ $(hostname) == $MASTER_HOSTNAME ];then if ping -c1 -w2 $BACKUP_HOSTNAME &>/dev/null;then runuser -l oracle -c "ssh -p$ssh_p $BACKUP_HOSTNAME 2>/dev/null df | grep $sharedisk | wc -l" fi fi if [ $(hostname) == $BACKUP_HOSTNAME ];then if ping -c1 -w2 $MASTER_HOSTNAME &>/dev/null;then runuser -l oracle -c "ssh -p$ssh_p $MASTER_HOSTNAME 2>/dev/null df | grep $sharedisk | wc -l" fi fi } master() { info_log "Database Switchover To MASTER\n" info_log "Check remote node sharedisk mounted.\n" i=1 while (($i<=30)) do chk_status=$(chk_remote_node_sharedisk) if [ $chk_status -ge 1 ];then info_log "$sharedisk is already mounted on remote node or busy. checking [$i]...\n" else info_log "$sharedisk check passed.\n" break fi if [ $i -eq 20 ];then info_log "Disk status abnormal.\n" exit 1 fi sleep 1 i=$(($i+1)) done ismount=$(df -h | grep $sharedisk | grep $sharedisk_mount_point | wc -l) if [ $ismount -eq 0 ];then info_log "mount $sharedisk on $sharedisk_mount_point\n" mount $sharedisk $sharedisk_mount_point RETVAL=$? if [ $RETVAL -eq 0 ];then #shutdown_instance info_log "restore controlfile 1\n" startup_nomount restore_controlfile else info_log "Error: $sharedisk cannot mount or $sharedisk_mount_point busy\n" exit $RETVAL fi else disk=$(df -h | grep $sharedisk_mount_point | awk '{print $1}') if [ $disk == $sharedisk ];then info_log "mount: $sharedisk is already mounted on $sharedisk_mount_point\n" else info_log "Warning: $sharedisk already mounted on $disk\n" fi fi status=$(check_instance_status | grep -Eio -e "\bOPEN\b" -e "\bMOUNTED\b" -e "\bSTARTED\b") if [ "$status" == "OPEN" ];then info_log "a database already open by the instance.\n" elif [ "$status" == "MOUNTED" ];then info_log "re-open database instance\n" open_instance | tee $TMPLOG opened=$(cat $TMPLOG | grep -Eio "\bDatabase altered\b") if [ "$opened" != "Database altered" ];then info_log "Error: database instance open fail!\n" exit 2 fi elif [ "$status" == "STARTED" ];then info_log "alter database to mount\n" mount_instance | tee $TMPLOG mounted=$(cat $TMPLOG | grep -Eio "\bDatabase altered\b") if [ "$mounted" == "Database altered" ];then info_log "alter database to open\n" open_instance | tee $TMPLOG opened=$(cat $TMPLOG | grep -Eio "\bDatabase altered\b") if [ "$opened" == "Database altered" ];then info_log "Database opened.\n" else info_log "Database open failed\n" exit 4 fi else info_log "Database mount failed\n" exit 3 fi else info_log "Startup database and open instance\n" shutdown_instance &>/dev/null startup_instance | tee $TMPLOG started=$(cat $TMPLOG | grep -Eio "\bDatabase opened\b") if [ "$started" != "Database opened" ];then info_log "Database instance open fail.\n" info_log "restore controlfile 2\n" shutdown_instance | tee $TMPLOG startup_nomount | tee $TMPLOG restore_controlfile shutdown_instance | tee $TMPLOG startup_instance | tee $TMPLOG started=$(cat $TMPLOG | grep -Eio "\bDatabase opened\b") if [ "$started" != "Database opened" ];then info_log "Database restore fail!\n" exit 5 else info_log "Database opened.\n" fi else info_log "Database opened.\n" fi fi info_log "Startup listener\n" runuser -l oracle -c "lsnrctl status &>/dev/null" if [ $? -eq 0 ];then info_log "listener already started.\n" else info_log "starting listener...\n" runuser -l oracle -c "lsnrctl start &>/dev/null" if [ $? -eq 0 ];then info_log "The listener startup successfully\n" else info_log "Listener start failure!\n" fi fi echo } backup() { info_log "Database Switchover To BACKUP\n" ismount=$(df -h | grep $sharedisk | grep $sharedisk_mount_point | wc -l) if [ $ismount -ge 1 ];then disk=$(df -h | grep $sharedisk_mount_point | awk '{print $1}') if [ $disk == $sharedisk ];then status=$(check_instance_status | grep -Eio -e "\bOPEN\b" -e "\bMOUNTED\b" -e "\bSTARTED\b") if [ "$status" == "OPEN" -o "$status" == "MOUNTED" ];then info_log "Database instance state is mounted\n" info_log "Backup current controlfile.\n" echo -e "\nSQL> alter database backup controlfile to '$controlfile_back';\n" backup_controlfile info_log "Shutdown database instance, please wait...\n" shutdown_instance | tee $TMPLOG shuted=$(cat $TMPLOG | grep -Eio "\binstance shut down\b") if [ "$shuted" == "instance shut down" ];then info_log "Database instance shutdown successfully.\n" else info_log "Database instance shutdown failed.\n" info_log "shutdown abort.\n" shutdown_abort fi elif [ "$status" == "STARTED" ];then info_log "Database instance state is STARTED\n" info_log "Shutdown database instance, please wait...\n" shutdown_instance | tee $TMPLOG shuted=$(cat $TMPLOG | grep -Eio "\binstance shut down\b") if [ "$shuted" == "instance shut down" ];then info_log "Database instance shutdown successfully.\n" else info_log "Database instance shutdown failed.\n" info_log "shutdown abort.\n" shutdown_abort fi else shutdown_instance | tee $TMPLOG info_log "Database instance not available.\n" fi echo info_log "umount sharedisk\n" echo umount $sharedisk_mount_point && RETVAL=$? if [ $RETVAL -eq 0 ];then info_log "umount $sharedisk_mount_point success.\n" else info_log "umount $sharedisk_mount_point fail!\n" fi else info_log "$sharedisk is not mount on $sharedisk_mount_point or busy.\n" fi else info_log "$sharedisk_mount_point is no mount\n" fi info_log "stopping listener...\n" runuser -l oracle -c "lsnrctl status" &>/dev/null RETVAL=$? if [ $RETVAL -eq 0 ];then runuser -l oracle -c "lsnrctl stop" &>/dev/null RETVAL=$? if [ $RETVAL -eq 0 ];then info_log "The listener stop successfully\n" else info_log "Listener stop failure!\n" fi else info_log "listener is not started.\n" fi echo } notify_master() { echo -e "\n-------------------------------------------------------------------------------" echo "`date '+%b %d %T %a'` $(hostname) [keepalived_notify]: Transition to $1 STATE"; echo "`date '+%b %d %T %a'` $(hostname) [keepalived_notify]: Setup the VIP on $interface $virtual_ipaddress"; } notify_backup() { echo -e "\n-------------------------------------------------------------------------------" echo "`date '+%b %d %T %a'` $HOSTNAME [keepalived_notify]: Transition to $1 STATE"; echo "`date '+%b %d %T %a'` $HOSTNAME [keepalived_notify]: removing the VIP on $interface for $virtual_ipaddress"; } case $1 in master) notify_master MASTER | tee -a $LOGFILE master | tee -a $LOGFILE ;; backup) notify_backup BACKUP | tee -a $LOGFILE backup | tee -a $LOGFILE ;; fault) notify_backup FAULT | tee -a $LOGFILE backup | tee -a $LOGFILE ;; stop) notify_backup STOP | tee -a $LOGFILE /etc/init.d/keepalived start #sleep 6 && backup | tee -a $LOGFILE ;; *) echo "Usage: `basename $0` {master|backup|fault|stop}" RETVAL=1 ;; esac exit $RETVAL
l 将主服务器切换为BACKUP状态
执行./keepalived_notify.sh backup
[root@hmdg-db1 scripts]# ./keepalived_notify.sh backup ------------------------------------------------------------------------------- Apr 15 17:23:05 Sun hmdg-db1 [keepalived_notify]: Transition to BACKUP STATE Apr 15 17:23:05 Sun hmdg-db1 [keepalived_notify]: removing the VIP on eth2 for 172.16.10.130,172.16.10.131 Apr 15 17:23:05 Sun hmdg-db1 [keepalived_notify]: Database Switchover To BACKUP Apr 15 17:23:05 Sun hmdg-db1 [keepalived_notify]: /oradata is no mount Apr 15 17:23:05 Sun hmdg-db1 [keepalived_notify]: stopping listener... Apr 15 17:23:05 Sun hmdg-db1 [keepalived_notify]: listener is not started.
观察执行脚本的输出结果,这是由于在本机上并没有启动oracle实例,所以脚本最终提示本机并没有启动oracle数据库实例
l 将主服务器切换为MASTER状态
执行./keepalived_notify.sh master
[root@hmdg-db1 scripts]# ./keepalived_notify.sh master ------------------------------------------------------------------------------- Apr 15 17:23:43 Sun hmdg-db1 [keepalived_notify]: Transition to MASTER STATE Apr 15 17:23:43 Sun hmdg-db1 [keepalived_notify]: Setup the VIP on eth2 172.16.10.130,172.16.10.131 Apr 15 17:23:43 Sun hmdg-db1 [keepalived_notify]: Database Switchover To MASTER Apr 15 17:23:43 Sun hmdg-db1 [keepalived_notify]: Check remote node sharedisk mounted. Apr 15 17:23:43 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 check passed. Apr 15 17:23:43 Sun hmdg-db1 [keepalived_notify]: mount /dev/sdb1 on /oradata Apr 15 17:23:43 Sun hmdg-db1 [keepalived_notify]: restore controlfile 1 ORACLE instance started. Total System Global Area 1603411968 bytes Fixed Size 2213776 bytes Variable Size 1056966768 bytes Database Buffers 536870912 bytes Redo Buffers 7360512 bytes Recovery Manager: Release 11.2.0.1.0 - Production on Sun Apr 15 17:23:44 2018 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. connected to target database: HMODB (not mounted) using target database control file instead of recovery catalog RMAN> Starting restore at 15-APR-18 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=572 device type=DISK channel ORA_DISK_1: copied control file copy output file name=/oradata/HMODB/control01.ctl output file name=/u01/app/oracle/flash_recovery_area/HMODB/control02.ctl output file name=/home/oracle/rman/HMODB/control03.ctl Finished restore at 15-APR-18 RMAN> Recovery Manager complete. Apr 15 17:23:46 Sun hmdg-db1 [keepalived_notify]: alter database to mount Database altered. Apr 15 17:23:50 Sun hmdg-db1 [keepalived_notify]: alter database to open Database altered. Apr 15 17:23:57 Sun hmdg-db1 [keepalived_notify]: Database opened. Apr 15 17:23:57 Sun hmdg-db1 [keepalived_notify]: Startup listener Apr 15 17:23:57 Sun hmdg-db1 [keepalived_notify]: starting listener... Apr 15 17:23:57 Sun hmdg-db1 [keepalived_notify]: The listener startup successfully
观察执行脚本的输出结果
1、脚本接收转换到MASTER信息
2、首先提示绑定的VIP
3、然后检测远程备用节点的磁盘是否挂载,或本机是否挂载了磁盘,检测成功则把磁盘挂载
4、启动数据库到nomount状态,并恢复控制文件
5、启动数据库实例到open状态
6、启动数据库监听,切换完成
注意:如果使用系统命令手动切换,应该要保证正在运行oracle服务的主节点先正常关闭,并且卸载共享存储之后,再启动备用节点的oracle服务(即不能同时挂载共享存储)
l 再次将主服务器切换到BACKUP状态
执行./keepalived_notify.sh backup
[root@hmdg-db1 scripts]# ./keepalived_notify.sh backup ------------------------------------------------------------------------------- Apr 15 17:34:54 Sun hmdg-db1 [keepalived_notify]: Transition to BACKUP STATE Apr 15 17:34:54 Sun hmdg-db1 [keepalived_notify]: removing the VIP on eth2 for 172.16.10.130,172.16.10.131 Apr 15 17:34:54 Sun hmdg-db1 [keepalived_notify]: Database Switchover To BACKUP Apr 15 17:34:55 Sun hmdg-db1 [keepalived_notify]: Database instance state is mounted Apr 15 17:34:55 Sun hmdg-db1 [keepalived_notify]: Backup current controlfile. SQL> alter database backup controlfile to '/backup/oracle/control/control_20181504173454'; Database altered. Apr 15 17:34:55 Sun hmdg-db1 [keepalived_notify]: Shutdown database instance, please wait... Database closed. Database dismounted. ORACLE instance shut down. Apr 15 17:35:04 Sun hmdg-db1 [keepalived_notify]: Database instance shutdown successfully. Apr 15 17:35:04 Sun hmdg-db1 [keepalived_notify]: umount sharedisk Apr 15 17:35:05 Sun hmdg-db1 [keepalived_notify]: umount /oradata success. Apr 15 17:35:05 Sun hmdg-db1 [keepalived_notify]: stopping listener... Apr 15 17:35:08 Sun hmdg-db1 [keepalived_notify]: The listener stop successfully
观察执行脚本的输出结果
1、 脚本接收转换到BACKUP信息
2、 首先移除VIP(由keepalived绑定到主机上浮动IP地址,同时也是对外提供服务的IP地址),实际上是由keepalived检测到异常或本身的服务器不可用时自动剔除VIP
3、 备份控制文件到/backup/oracle/control/目录下
4、 正常关闭数据库实例
5、 卸载共享存储
6、 关闭数据库监听程序
l notify脚本切换演示
如果备机主动切换到MASTER状态时,脚本首先或检测对方磁盘是否umount,如果没有则最多等待20秒,提示异常并正常推出切换到MASTER的请求
[root@hmdg-db1 scripts]# ./keepalived_notify.sh master ------------------------------------------------------------------------------- Apr 15 17:40:08 Sun hmdg-db1 [keepalived_notify]: Transition to MASTER STATE Apr 15 17:40:08 Sun hmdg-db1 [keepalived_notify]: Setup the VIP on eth2 172.16.10.130,172.16.10.131 Apr 15 17:40:08 Sun hmdg-db1 [keepalived_notify]: Database Switchover To MASTER Apr 15 17:40:08 Sun hmdg-db1 [keepalived_notify]: Check remote node sharedisk mounted. Apr 15 17:40:08 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [1]... Apr 15 17:40:09 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [2]... Apr 15 17:40:10 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [3]... Apr 15 17:40:12 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [4]... Apr 15 17:40:13 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [5]... Apr 15 17:40:14 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [6]... Apr 15 17:40:15 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [7]... Apr 15 17:40:16 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [8]... Apr 15 17:40:17 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [9]... Apr 15 17:40:18 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [10]... Apr 15 17:40:20 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [11]... Apr 15 17:40:21 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [12]... Apr 15 17:40:22 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [13]... Apr 15 17:40:23 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [14]... Apr 15 17:40:24 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [15]... Apr 15 17:40:25 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [16]... Apr 15 17:40:26 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [17]... Apr 15 17:40:27 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [18]... Apr 15 17:40:29 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [19]... Apr 15 17:40:30 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [20]... Apr 15 17:40:30 Sun hmdg-db1 [keepalived_notify]: Disk status abnormal.
这时如果需要手动切换,则需要先将远程备用节点的服务关闭并umount存储之后,才能正常切换
[root@hmdg-db1 scripts]# ./keepalived_notify.sh master ------------------------------------------------------------------------------- Apr 15 17:45:29 Sun hmdg-db1 [keepalived_notify]: Transition to MASTER STATE Apr 15 17:45:29 Sun hmdg-db1 [keepalived_notify]: Setup the VIP on eth2 172.16.10.130,172.16.10.131 Apr 15 17:45:29 Sun hmdg-db1 [keepalived_notify]: Database Switchover To MASTER Apr 15 17:45:29 Sun hmdg-db1 [keepalived_notify]: Check remote node sharedisk mounted. Apr 15 17:45:29 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [1]... Apr 15 17:45:30 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [2]... Apr 15 17:45:31 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [3]... Apr 15 17:45:32 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [4]... Apr 15 17:45:33 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [5]... Apr 15 17:45:35 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [6]... Apr 15 17:45:36 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [7]... Apr 15 17:45:37 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [8]... Apr 15 17:45:38 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [9]... Apr 15 17:45:39 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [10]... Apr 15 17:45:40 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [11]... Apr 15 17:45:41 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [12]... Apr 15 17:45:42 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [13]... Apr 15 17:45:44 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 check passed. Apr 15 17:45:44 Sun hmdg-db1 [keepalived_notify]: mount /dev/sdb1 on /oradata Apr 15 17:45:44 Sun hmdg-db1 [keepalived_notify]: restore controlfile 1 ORACLE instance started. Total System Global Area 1603411968 bytes Fixed Size 2213776 bytes Variable Size 1056966768 bytes Database Buffers 536870912 bytes Redo Buffers 7360512 bytes Recovery Manager: Release 11.2.0.1.0 - Production on Sun Apr 15 17:45:45 2018 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. connected to target database: HMODB (not mounted) using target database control file instead of recovery catalog RMAN> Starting restore at 15-APR-18 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=572 device type=DISK channel ORA_DISK_1: copied control file copy output file name=/oradata/HMODB/control01.ctl output file name=/u01/app/oracle/flash_recovery_area/HMODB/control02.ctl output file name=/home/oracle/rman/HMODB/control03.ctl Finished restore at 15-APR-18 RMAN> Recovery Manager complete. Apr 15 17:45:46 Sun hmdg-db1 [keepalived_notify]: alter database to mount Database altered. Apr 15 17:45:51 Sun hmdg-db1 [keepalived_notify]: alter database to open Database altered. Apr 15 17:45:58 Sun hmdg-db1 [keepalived_notify]: Database opened. Apr 15 17:45:58 Sun hmdg-db1 [keepalived_notify]: Startup listener Apr 15 17:45:58 Sun hmdg-db1 [keepalived_notify]: starting listener... Apr 15 17:45:58 Sun hmdg-db1 [keepalived_notify]: The listener startup successfully
启动keepalived服务时,keepalived首先进行资源检测,并根据权值设定MASTER角色
keepalived接管的资源:Oracle实例、存储、VIP
1、启动主服务器DB1的keepalived
##启动keepalived [root@hmdg-db1 scripts]# /etc/init.d/keepalived start ##设置开机启动 [root@hmdg-db1 scripts]# chkconfig keepalived on
2、查看主服务器的keepalived系统日志
[root@hmdg-db1 scripts]# tail -f /var/log/messages Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: Registering Kernel netlink reflector Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: Registering Kernel netlink command channel Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: Registering gratuitous ARP shared channel Apr 15 17:51:25 hmdg-db1 Keepalived_healthcheckers[82071]: Using LinkWatch kernel netlink reflector... Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: Opening file '/usr/local/keepalived/etc/keepalived/keepalived.conf'. Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Instance(Oracle_HA_1) removing protocol VIPs. Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: SECURITY VIOLATION - scripts are being executed but script_security not enabled. Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: Sync group ORACLE_HA_GROUP has only 1 virtual router(s) - removing Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: Using LinkWatch kernel netlink reflector... Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Instance(Oracle_HA_1) Entering BACKUP STATE Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Script(change_monitor_status) succeeded Apr 15 17:51:25 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Script(monitor_oracle_status) succeeded Apr 15 17:51:27 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Instance(Oracle_HA_1) Changing effective priority from 100 to 120 Apr 15 17:51:31 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Instance(Oracle_HA_1) Transition to MASTER STATE Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Instance(Oracle_HA_1) Entering MASTER STATE Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Instance(Oracle_HA_1) setting protocol VIPs. Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 17:51:33 hmdg-db1 Keepalived_healthcheckers[82071]: Netlink reflector reports IP 172.16.10.130 added Apr 15 17:51:33 hmdg-db1 Keepalived_healthcheckers[82071]: Netlink reflector reports IP 172.16.10.131 added Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.130 Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.131 Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 17:51:33 hmdg-db1 Keepalived_vrrp[82072]: Sending gratuitous ARP on eth2 for 172.16.10.131
3、启动备服务器DB2的keepalived
##启动keepalived [root@hmdg-db2 scripts]# /etc/init.d/keepalived start ##设置开机启动 [root@hmdg-db2 scripts]# chkconfig keepalived on
4、查看备服务器的keepalived系统日志
Apr 15 17:51:41 hmdg-db2 Keepalived[71709]: Starting Keepalived v1.3.2 (04/14,2018) Apr 15 17:51:41 hmdg-db2 Keepalived[71709]: WARNING - default user 'keepalived_script' for script execution does not exist - please create. Apr 15 17:51:41 hmdg-db2 Keepalived[71709]: Opening file '/usr/local/keepalived/etc/keepalived/keepalived.conf'. Apr 15 17:51:41 hmdg-db2 Keepalived[71710]: Starting Healthcheck child process, pid=71711 Apr 15 17:51:41 hmdg-db2 Keepalived[71710]: Starting VRRP child process, pid=71712 Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Netlink reflector reports IP 192.168.6.26 added Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Netlink reflector reports IP 172.16.10.26 added Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Netlink reflector reports IP fe80::20c:29ff:fedd:d175 added Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Netlink reflector reports IP 192.168.6.26 added Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Netlink reflector reports IP fe80::20c:29ff:fedd:d17f added Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Netlink reflector reports IP fe80::20c:29ff:fedd:d189 added Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Netlink reflector reports IP 172.16.10.26 added Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Netlink reflector reports IP fe80::20c:29ff:fedd:d193 added Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Registering Kernel netlink reflector Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Netlink reflector reports IP fe80::20c:29ff:fedd:d175 added Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Netlink reflector reports IP fe80::20c:29ff:fedd:d17f added Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Netlink reflector reports IP fe80::20c:29ff:fedd:d189 added Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Netlink reflector reports IP fe80::20c:29ff:fedd:d193 added Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Registering Kernel netlink reflector Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Registering Kernel netlink command channel Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Registering gratuitous ARP shared channel Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Opening file '/usr/local/keepalived/etc/keepalived/keepalived.conf'. Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: VRRP_Instance(Oracle_HA_1) removing protocol VIPs. Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: SECURITY VIOLATION - scripts are being executed but script_security not enabled. Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Sync group ORACLE_HA_GROUP has only 1 virtual router(s) - removing Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Registering Kernel netlink command channel Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Opening file '/usr/local/keepalived/etc/keepalived/keepalived.conf'. Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: Using LinkWatch kernel netlink reflector... Apr 15 17:51:41 hmdg-db2 Keepalived_healthcheckers[71711]: Using LinkWatch kernel netlink reflector... Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: VRRP_Instance(Oracle_HA_1) Entering BACKUP STATE Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: pid 71721 exited with status 1 Apr 15 17:51:41 hmdg-db2 Keepalived_vrrp[71712]: VRRP_Script(change_monitor_status) succeeded Apr 15 17:52:01 hmdg-db2 Keepalived_vrrp[71712]: VRRP_Script(monitor_oracle_status) succeeded Apr 15 17:52:01 hmdg-db2 Keepalived_vrrp[71712]: VRRP_Instance(Oracle_HA_1) Changing effective priority from 90 to 110
5、主备Oracle、VIP、磁盘服务状态检查
##DB1 [root@hmdg-db1 scripts]# ps -ef | grep ora_ oracle 82439 1 0 17:51 ? 00:00:00 ora_pmon_HMODB oracle 82441 1 0 17:51 ? 00:00:00 ora_vktm_HMODB oracle 82445 1 0 17:51 ? 00:00:00 ora_gen0_HMODB oracle 82447 1 0 17:51 ? 00:00:00 ora_diag_HMODB oracle 82449 1 0 17:51 ? 00:00:00 ora_dbrm_HMODB oracle 82451 1 0 17:51 ? 00:00:00 ora_psp0_HMODB oracle 82453 1 0 17:51 ? 00:00:00 ora_dia0_HMODB oracle 82455 1 0 17:51 ? 00:00:00 ora_mman_HMODB oracle 82457 1 0 17:51 ? 00:00:00 ora_dbw0_HMODB oracle 82459 1 0 17:51 ? 00:00:00 ora_lgwr_HMODB oracle 82461 1 0 17:51 ? 00:00:00 ora_ckpt_HMODB oracle 82463 1 0 17:51 ? 00:00:00 ora_smon_HMODB oracle 82465 1 0 17:51 ? 00:00:00 ora_reco_HMODB oracle 82467 1 0 17:51 ? 00:00:00 ora_mmon_HMODB oracle 82469 1 0 17:51 ? 00:00:00 ora_mmnl_HMODB oracle 82471 1 0 17:51 ? 00:00:00 ora_d000_HMODB oracle 82473 1 0 17:51 ? 00:00:00 ora_s000_HMODB oracle 82638 1 0 17:51 ? 00:00:00 ora_arc0_HMODB oracle 82653 1 0 17:51 ? 00:00:00 ora_arc1_HMODB oracle 82655 1 0 17:51 ? 00:00:00 ora_arc2_HMODB oracle 82657 1 0 17:51 ? 00:00:00 ora_arc3_HMODB oracle 82755 1 0 17:51 ? 00:00:00 ora_qmnc_HMODB oracle 82807 1 0 17:51 ? 00:00:00 ora_cjq0_HMODB oracle 82835 1 0 17:51 ? 00:00:00 ora_vkrm_HMODB oracle 82863 1 0 17:51 ? 00:00:00 ora_q000_HMODB oracle 82865 1 0 17:51 ? 00:00:00 ora_q001_HMODB oracle 84099 1 1 17:54 ? 00:00:00 ora_j000_HMODB oracle 84101 1 0 17:54 ? 00:00:00 ora_j001_HMODB root 84268 3823 0 17:54 pts/2 00:00:00 grep ora_ [root@hmdg-db1 scripts]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/sda3 ext4 50G 19G 29G 40% / tmpfs tmpfs 3.9G 909M 3.0G 24% /dev/shm /dev/sda1 ext4 190M 40M 141M 22% /boot /dev/sdb1 ext4 30G 6.0G 22G 22% /oradata [root@hmdg-db1 scripts]# ip addr show dev eth2 3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:59:d5:91 brd ff:ff:ff:ff:ff:ff inet 172.16.10.25/24 brd 172.16.10.255 scope global eth2 inet 172.16.10.130/24 scope global secondary eth2 inet 172.16.10.131/24 scope global secondary eth2 inet6 fe80::20c:29ff:fe59:d591/64 scope link valid_lft forever preferred_lft forever ##DB2 [root@hmdg-db2 scripts]# ps -ef | grep ora_ root 73251 31390 0 17:55 pts/2 00:00:00 grep ora_ [root@hmdg-db2 scripts]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/sda3 ext4 50G 18G 30G 37% / tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/sda1 ext4 190M 40M 141M 22% /boot [root@hmdg-db2 scripts]# ip addr show dev eth2 3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:dd:d1:7f brd ff:ff:ff:ff:ff:ff inet 172.16.10.26/24 brd 172.16.10.255 scope global eth2 inet6 fe80::20c:29ff:fedd:d17f/64 scope link valid_lft forever preferred_lft forever
停止或重启主服务器的keepalibed服务
主服务器DB1
##系统日志 Apr 15 18:08:02 hmdg-db1 Keepalived[89311]: Stopping Apr 15 18:08:02 hmdg-db1 Keepalived_healthcheckers[89313]: Stopped Apr 15 18:08:02 hmdg-db1 Keepalived_vrrp[89314]: VRRP_Instance(Oracle_HA_1) sent 0 priority Apr 15 18:08:02 hmdg-db1 Keepalived_vrrp[89314]: VRRP_Instance(Oracle_HA_1) removing protocol VIPs. Apr 15 18:08:03 hmdg-db1 Keepalived_vrrp[89314]: Stopped Apr 15 18:08:03 hmdg-db1 Keepalived[89311]: Stopped Keepalived v1.3.2 (04/14,2018) ##nitify脚本的输出日志 ------------------------------------------------------------------------------- Apr 15 18:08:03 Sun hmdg-db1 [keepalived_notify]: Transition to STOP STATE Apr 15 18:08:03 Sun hmdg-db1 [keepalived_notify]: removing the VIP on eth2 for 172.16.10.130,172.16.10.131 Apr 15 18:08:09 Sun hmdg-db1 [keepalived_notify]: Database Switchover To BACKUP Apr 15 18:08:09 Sun hmdg-db1 [keepalived_notify]: Database instance state is mounted Apr 15 18:08:09 Sun hmdg-db1 [keepalived_notify]: Backup current controlfile. SQL> alter database backup controlfile to '/backup/oracle/control/control_20181504180803'; Database altered. Apr 15 18:08:09 Sun hmdg-db1 [keepalived_notify]: Shutdown database instance, please wait... Database closed. Database dismounted. ORACLE instance shut down. Apr 15 18:08:18 Sun hmdg-db1 [keepalived_notify]: Database instance shutdown successfully. Apr 15 18:08:18 Sun hmdg-db1 [keepalived_notify]: umount sharedisk Apr 15 18:08:18 Sun hmdg-db1 [keepalived_notify]: umount /oradata success. Apr 15 18:08:18 Sun hmdg-db1 [keepalived_notify]: stopping listener... Apr 15 18:08:19 Sun hmdg-db1 [keepalived_notify]: The listener stop successfully ##服务资源检查 [root@hmdg-db1 scripts]# ps -ef | grep ora_ root 90758 2451 0 18:09 pts/0 00:00:00 grep ora_ [root@hmdg-db1 scripts]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/sda3 ext4 50G 19G 29G 40% / tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/sda1 ext4 190M 40M 141M 22% /boot [root@hmdg-db1 scripts]# ip addr show dev eth2 3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:59:d5:91 brd ff:ff:ff:ff:ff:ff inet 172.16.10.25/24 brd 172.16.10.255 scope global eth2 inet6 fe80::20c:29ff:fe59:d591/64 scope link valid_lft forever preferred_lft forever
由于主服务的keepalived异常,keepalived实例组将会重新分配MASTER角色,并将资源转移到BACKUP上(即重新选举后新的MASTER)
备服务器DB2
##系统日志 Apr 15 18:08:03 hmdg-db2 Keepalived_vrrp[77811]: VRRP_Instance(Oracle_HA_1) Transition to MASTER STATE Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: VRRP_Instance(Oracle_HA_1) Entering MASTER STATE Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: VRRP_Instance(Oracle_HA_1) setting protocol VIPs. Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.130 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.131 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:05 hmdg-db2 Keepalived_healthcheckers[77810]: Netlink reflector reports IP 172.16.10.130 added Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:05 hmdg-db2 Keepalived_healthcheckers[77810]: Netlink reflector reports IP 172.16.10.131 added Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:05 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.130 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.131 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:08:10 hmdg-db2 Keepalived_vrrp[77811]: Sending gratuitous ARP on eth2 for 172.16.10.131 ##notify脚本日志 ------------------------------------------------------------------------------- Apr 15 18:08:05 Sun hmdg-db2 [keepalived_notify]: Transition to MASTER STATE Apr 15 18:08:05 Sun hmdg-db2 [keepalived_notify]: Setup the VIP on eth2 172.16.10.130,172.16.10.131 Apr 15 18:08:05 Sun hmdg-db2 [keepalived_notify]: Database Switchover To MASTER Apr 15 18:08:05 Sun hmdg-db2 [keepalived_notify]: Check remote node sharedisk mounted. Apr 15 18:08:05 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [1]... Apr 15 18:08:06 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [2]... Apr 15 18:08:08 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [3]... Apr 15 18:08:09 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [4]... Apr 15 18:08:10 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [5]... Apr 15 18:08:11 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [6]... Apr 15 18:08:12 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [7]... Apr 15 18:08:13 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [8]... Apr 15 18:08:14 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [9]... Apr 15 18:08:15 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [10]... Apr 15 18:08:17 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [11]... Apr 15 18:08:18 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [12]... Apr 15 18:08:19 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 check passed. Apr 15 18:08:19 Sun hmdg-db2 [keepalived_notify]: mount /dev/sdb1 on /oradata Apr 15 18:08:19 Sun hmdg-db2 [keepalived_notify]: restore controlfile 1 ORACLE instance started. Total System Global Area 1603411968 bytes Fixed Size 2213776 bytes Variable Size 1056966768 bytes Database Buffers 536870912 bytes Redo Buffers 7360512 bytes Recovery Manager: Release 11.2.0.1.0 - Production on Sun Apr 15 18:08:20 2018 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. connected to target database: HMODB (not mounted) using target database control file instead of recovery catalog RMAN> Starting restore at 15-APR-18 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=572 device type=DISK channel ORA_DISK_1: copied control file copy output file name=/oradata/HMODB/control01.ctl output file name=/u01/app/oracle/flash_recovery_area/HMODB/control02.ctl output file name=/home/oracle/rman/HMODB/control03.ctl Finished restore at 15-APR-18 RMAN> Recovery Manager complete. Apr 15 18:08:22 Sun hmdg-db2 [keepalived_notify]: alter database to mount Database altered. Apr 15 18:08:26 Sun hmdg-db2 [keepalived_notify]: alter database to open Database altered. Apr 15 18:08:33 Sun hmdg-db2 [keepalived_notify]: Database opened. Apr 15 18:08:33 Sun hmdg-db2 [keepalived_notify]: Startup listener Apr 15 18:08:33 Sun hmdg-db2 [keepalived_notify]: starting listener... Apr 15 18:08:33 Sun hmdg-db2 [keepalived_notify]: The listener startup successfully ##服务检查 [root@hmdg-db2 scripts]# ps -ef | grep ora_ oracle 78632 1 0 18:08 ? 00:00:00 ora_pmon_HMODB oracle 78634 1 0 18:08 ? 00:00:00 ora_vktm_HMODB oracle 78638 1 0 18:08 ? 00:00:00 ora_gen0_HMODB oracle 78640 1 0 18:08 ? 00:00:00 ora_diag_HMODB oracle 78642 1 0 18:08 ? 00:00:00 ora_dbrm_HMODB oracle 78644 1 0 18:08 ? 00:00:00 ora_psp0_HMODB oracle 78646 1 0 18:08 ? 00:00:00 ora_dia0_HMODB oracle 78648 1 0 18:08 ? 00:00:00 ora_mman_HMODB oracle 78650 1 0 18:08 ? 00:00:00 ora_dbw0_HMODB oracle 78652 1 0 18:08 ? 00:00:00 ora_lgwr_HMODB oracle 78654 1 0 18:08 ? 00:00:00 ora_ckpt_HMODB oracle 78656 1 0 18:08 ? 00:00:00 ora_smon_HMODB oracle 78658 1 0 18:08 ? 00:00:00 ora_reco_HMODB oracle 78660 1 0 18:08 ? 00:00:00 ora_mmon_HMODB oracle 78662 1 0 18:08 ? 00:00:00 ora_mmnl_HMODB oracle 78664 1 0 18:08 ? 00:00:00 ora_d000_HMODB oracle 78666 1 0 18:08 ? 00:00:00 ora_s000_HMODB oracle 78844 1 0 18:08 ? 00:00:00 ora_arc0_HMODB oracle 78847 1 0 18:08 ? 00:00:00 ora_arc1_HMODB oracle 78849 1 0 18:08 ? 00:00:00 ora_arc2_HMODB oracle 78851 1 0 18:08 ? 00:00:00 ora_arc3_HMODB oracle 78879 1 0 18:08 ? 00:00:00 ora_qmnc_HMODB oracle 78968 1 0 18:08 ? 00:00:00 ora_cjq0_HMODB oracle 79031 1 0 18:08 ? 00:00:00 ora_vkrm_HMODB oracle 79059 1 0 18:08 ? 00:00:00 ora_q000_HMODB oracle 79061 1 0 18:08 ? 00:00:00 ora_q001_HMODB oracle 81652 1 0 18:13 ? 00:00:00 ora_smco_HMODB oracle 81667 1 0 18:13 ? 00:00:00 ora_w000_HMODB root 81808 31390 0 18:13 pts/2 00:00:00 grep ora_ [root@hmdg-db2 scripts]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/sda3 ext4 50G 18G 30G 37% / tmpfs tmpfs 3.9G 909M 3.0G 24% /dev/shm /dev/sda1 ext4 190M 40M 141M 22% /boot /dev/sdb1 ext4 30G 6.0G 22G 22% /oradata [root@hmdg-db2 scripts]# ip addr show dev eth2 3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:dd:d1:7f brd ff:ff:ff:ff:ff:ff inet 172.16.10.26/24 brd 172.16.10.255 scope global eth2 inet 172.16.10.130/24 scope global secondary eth2 inet 172.16.10.131/24 scope global secondary eth2 inet6 fe80::20c:29ff:fedd:d17f/64 scope link valid_lft forever preferred_lft forever
首先将DB1的Keepalived服务启动
Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: Opening file '/usr/local/keepalived/etc/keepalived/keepalived.conf'. Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) removing protocol VIPs. Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: SECURITY VIOLATION - scripts are being executed but script_security not enabled. Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: Sync group ORACLE_HA_GROUP has only 1 virtual router(s) - removing Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: Using LinkWatch kernel netlink reflector... Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Entering BACKUP STATE Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: pid 90794 exited with status 1 Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Script(change_monitor_status) succeeded Apr 15 18:15:34 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Script(monitor_oracle_status) succeeded Apr 15 18:15:34 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Changing effective priority from 100 to 120
停止备服务器的keepalived服务
##系统日志 Apr 15 18:16:24 hmdg-db2 Keepalived_vrrp[83304]: VRRP_Instance(Oracle_HA_1) Entering BACKUP STATE Apr 15 18:16:24 hmdg-db2 Keepalived_vrrp[83304]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Apr 15 18:16:24 hmdg-db2 Keepalived_vrrp[83304]: VRRP_Script(change_monitor_status) succeeded Apr 15 18:16:25 hmdg-db2 Keepalived_vrrp[83304]: VRRP_Script(monitor_oracle_status) succeeded Apr 15 18:16:26 hmdg-db2 Keepalived_vrrp[83304]: VRRP_Instance(Oracle_HA_1) Changing effective priority from 90 to 110 ##notify日志 ------------------------------------------------------------------------------- Apr 15 18:16:24 Sun hmdg-db2 [keepalived_notify]: Transition to STOP STATE Apr 15 18:16:24 Sun hmdg-db2 [keepalived_notify]: removing the VIP on eth2 for 172.16.10.130,172.16.10.131 ------------------------------------------------------------------------------- Apr 15 18:16:24 Sun hmdg-db2 [keepalived_notify]: Transition to BACKUP STATE Apr 15 18:16:24 Sun hmdg-db2 [keepalived_notify]: removing the VIP on eth2 for 172.16.10.130,172.16.10.131 Apr 15 18:16:24 Sun hmdg-db2 [keepalived_notify]: Database Switchover To BACKUP Apr 15 18:16:24 Sun hmdg-db2 [keepalived_notify]: Database instance state is mounted Apr 15 18:16:25 Sun hmdg-db2 [keepalived_notify]: Backup current controlfile. SQL> alter database backup controlfile to '/backup/oracle/control/control_20181504181624'; Database altered. Apr 15 18:16:25 Sun hmdg-db2 [keepalived_notify]: Shutdown database instance, please wait... Database closed. Database dismounted. ORACLE instance shut down. Apr 15 18:16:34 Sun hmdg-db2 [keepalived_notify]: Database instance shutdown successfully. Apr 15 18:16:34 Sun hmdg-db2 [keepalived_notify]: umount sharedisk Apr 15 18:16:34 Sun hmdg-db2 [keepalived_notify]: umount /oradata success. Apr 15 18:16:34 Sun hmdg-db2 [keepalived_notify]: stopping listener... Apr 15 18:16:38 Sun hmdg-db2 [keepalived_notify]: The listener stop successfully ##服务状态 [root@hmdg-db2 scripts]# ps -ef | grep ora_ root 84619 31390 0 18:18 pts/2 00:00:00 grep ora_ [root@hmdg-db2 scripts]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/sda3 ext4 50G 18G 30G 37% / tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/sda1 ext4 190M 40M 141M 22% /boot [root@hmdg-db2 scripts]# ip addr show dev eth2 3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:dd:d1:7f brd ff:ff:ff:ff:ff:ff inet 172.16.10.26/24 brd 172.16.10.255 scope global eth2 inet6 fe80::20c:29ff:fedd:d17f/64 scope link valid_lft forever preferred_lft forever
检查DB1是否转换为MASTER并接管服务资源
##DB1的系统日志 Apr 15 18:15:14 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Script(change_monitor_status) succeeded Apr 15 18:15:34 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Script(monitor_oracle_status) succeeded Apr 15 18:15:34 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Changing effective priority from 100 to 120 Apr 15 18:16:23 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Transition to MASTER STATE Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Entering MASTER STATE Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) setting protocol VIPs. Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.130 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:16:25 hmdg-db1 Keepalived_healthcheckers[90790]: Netlink reflector reports IP 172.16.10.130 added Apr 15 18:16:25 hmdg-db1 Keepalived_healthcheckers[90790]: Netlink reflector reports IP 172.16.10.131 added Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.131 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:16:25 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:16:30 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:16:30 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.130 Apr 15 18:16:30 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:16:30 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.131 Apr 15 18:16:30 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:16:30 hmdg-db1 Keepalived_vrrp[90792]: Sending gratuitous ARP on eth2 for 172.16.10.131 ##DB1的notify脚本日志 ------------------------------------------------------------------------------- Apr 15 18:16:25 Sun hmdg-db1 [keepalived_notify]: Transition to MASTER STATE Apr 15 18:16:25 Sun hmdg-db1 [keepalived_notify]: Setup the VIP on eth2 172.16.10.130,172.16.10.131 Apr 15 18:16:25 Sun hmdg-db1 [keepalived_notify]: Database Switchover To MASTER Apr 15 18:16:25 Sun hmdg-db1 [keepalived_notify]: Check remote node sharedisk mounted. Apr 15 18:16:26 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [1]... Apr 15 18:16:27 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [2]... Apr 15 18:16:28 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [3]... Apr 15 18:16:29 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [4]... Apr 15 18:16:30 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [5]... Apr 15 18:16:31 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [6]... Apr 15 18:16:32 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [7]... Apr 15 18:16:34 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [8]... Apr 15 18:16:35 Sun hmdg-db1 [keepalived_notify]: /dev/sdb1 check passed. Apr 15 18:16:35 Sun hmdg-db1 [keepalived_notify]: mount /dev/sdb1 on /oradata Apr 15 18:16:35 Sun hmdg-db1 [keepalived_notify]: restore controlfile 1 ORACLE instance started. Total System Global Area 1603411968 bytes Fixed Size 2213776 bytes Variable Size 1056966768 bytes Database Buffers 536870912 bytes Redo Buffers 7360512 bytes Recovery Manager: Release 11.2.0.1.0 - Production on Sun Apr 15 18:16:38 2018 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. connected to target database: HMODB (not mounted) using target database control file instead of recovery catalog RMAN> Starting restore at 15-APR-18 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=572 device type=DISK channel ORA_DISK_1: copied control file copy output file name=/oradata/HMODB/control01.ctl output file name=/u01/app/oracle/flash_recovery_area/HMODB/control02.ctl output file name=/home/oracle/rman/HMODB/control03.ctl Finished restore at 15-APR-18 RMAN> Recovery Manager complete. Apr 15 18:16:40 Sun hmdg-db1 [keepalived_notify]: alter database to mount Database altered. Apr 15 18:16:44 Sun hmdg-db1 [keepalived_notify]: alter database to open Database altered. Apr 15 18:16:50 Sun hmdg-db1 [keepalived_notify]: Database opened. Apr 15 18:16:50 Sun hmdg-db1 [keepalived_notify]: Startup listener Apr 15 18:16:50 Sun hmdg-db1 [keepalived_notify]: starting listener... Apr 15 18:16:50 Sun hmdg-db1 [keepalived_notify]: The listener startup successfully ##服务状态 [root@hmdg-db1 scripts]# ps -ef | grep ora_ oracle 91765 1 0 18:16 ? 00:00:00 ora_pmon_HMODB oracle 91767 1 0 18:16 ? 00:00:00 ora_vktm_HMODB oracle 91771 1 0 18:16 ? 00:00:00 ora_gen0_HMODB oracle 91773 1 0 18:16 ? 00:00:00 ora_diag_HMODB oracle 91775 1 0 18:16 ? 00:00:00 ora_dbrm_HMODB oracle 91777 1 0 18:16 ? 00:00:00 ora_psp0_HMODB oracle 91779 1 0 18:16 ? 00:00:00 ora_dia0_HMODB oracle 91781 1 0 18:16 ? 00:00:00 ora_mman_HMODB oracle 91783 1 0 18:16 ? 00:00:00 ora_dbw0_HMODB oracle 91785 1 0 18:16 ? 00:00:00 ora_lgwr_HMODB oracle 91787 1 0 18:16 ? 00:00:00 ora_ckpt_HMODB oracle 91789 1 0 18:16 ? 00:00:00 ora_smon_HMODB oracle 91791 1 0 18:16 ? 00:00:00 ora_reco_HMODB oracle 91793 1 0 18:16 ? 00:00:00 ora_mmon_HMODB oracle 91795 1 0 18:16 ? 00:00:00 ora_mmnl_HMODB oracle 91797 1 0 18:16 ? 00:00:00 ora_d000_HMODB oracle 91799 1 0 18:16 ? 00:00:00 ora_s000_HMODB oracle 91965 1 0 18:16 ? 00:00:00 ora_arc0_HMODB oracle 91967 1 0 18:16 ? 00:00:00 ora_arc1_HMODB oracle 91969 1 0 18:16 ? 00:00:00 ora_arc2_HMODB oracle 91971 1 0 18:16 ? 00:00:00 ora_arc3_HMODB oracle 91999 1 0 18:16 ? 00:00:00 ora_qmnc_HMODB oracle 92090 1 0 18:16 ? 00:00:00 ora_cjq0_HMODB oracle 92105 1 0 18:16 ? 00:00:00 ora_vkrm_HMODB oracle 92181 1 0 18:16 ? 00:00:00 ora_q000_HMODB oracle 92183 1 0 18:16 ? 00:00:00 ora_q001_HMODB oracle 93817 1 0 18:20 ? 00:00:00 ora_j000_HMODB oracle 93819 1 0 18:20 ? 00:00:00 ora_j001_HMODB root 94030 2451 0 18:20 pts/0 00:00:00 grep ora_ [root@hmdg-db1 scripts]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/sda3 ext4 50G 19G 29G 40% / tmpfs tmpfs 3.9G 909M 3.0G 24% /dev/shm /dev/sda1 ext4 190M 40M 141M 22% /boot /dev/sdb1 ext4 30G 6.0G 22G 22% /oradata [root@hmdg-db1 scripts]# ip addr show dev eth2 3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:59:d5:91 brd ff:ff:ff:ff:ff:ff inet 172.16.10.25/24 brd 172.16.10.255 scope global eth2 inet 172.16.10.130/24 scope global secondary eth2 inet 172.16.10.131/24 scope global secondary eth2 inet6 fe80::20c:29ff:fe59:d591/64 scope link valid_lft forever preferred_lft forever
1、手动关闭DB1的数据库实例
[oracle@hmdg-db1 ~]$ export ORACLE_SID=HMODB [oracle@hmdg-db1 ~]$ sqlplus / as sysdba SQL*Plus: Release 11.2.0.1.0 Production on Sun Apr 15 18:21:52 2018 Copyright (c) 1982, 2009, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options SQL> SELECT OPEN_MODE,NAME,DATABASE_ROLE FROM V$DATABASE; OPEN_MODE NAME DATABASE_ROLE -------------------- --------- ---------------- READ WRITE HMODB PRIMARY SQL> shutdown immediate Database closed. Database dismounted. ORACLE instance shut down.
2、查看keepalived日志
## Apr 15 18:23:34 hmdg-db1 Keepalived_vrrp[90792]: pid 96098 exited with status 2 Apr 15 18:23:48 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Received advert with higher priority 110, ours 100 Apr 15 18:23:48 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Entering BACKUP STATE Apr 15 18:23:48 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) removing protocol VIPs. Apr 15 18:23:48 hmdg-db1 Keepalived_healthcheckers[90790]: Netlink reflector reports IP 172.16.10.130 removed Apr 15 18:23:48 hmdg-db1 Keepalived_healthcheckers[90790]: Netlink reflector reports IP 172.16.10.131 removed Apr 15 18:23:54 hmdg-db1 Keepalived_vrrp[90792]: pid 96486 exited with status 2 Apr 15 18:24:14 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Script(monitor_oracle_status) succeeded Apr 15 18:24:15 hmdg-db1 Keepalived_vrrp[90792]: VRRP_Instance(Oracle_HA_1) Changing effective priority from 100 to 120 ------------------------------------------------------------------------------- Apr 15 18:23:48 Sun hmdg-db1 [keepalived_notify]: Transition to BACKUP STATE Apr 15 18:23:48 Sun hmdg-db1 [keepalived_notify]: removing the VIP on eth2 for 172.16.10.130,172.16.10.131 Apr 15 18:23:48 Sun hmdg-db1 [keepalived_notify]: Database Switchover To BACKUP Apr 15 18:23:49 Sun hmdg-db1 [keepalived_notify]: Database instance state is mounted Apr 15 18:23:49 Sun hmdg-db1 [keepalived_notify]: Backup current controlfile. SQL> alter database backup controlfile to '/backup/oracle/control/control_20181504182348'; Database altered. Apr 15 18:23:49 Sun hmdg-db1 [keepalived_notify]: Shutdown database instance, please wait... Database closed. Database dismounted. ORACLE instance shut down. Apr 15 18:23:55 Sun hmdg-db1 [keepalived_notify]: Database instance shutdown successfully. Apr 15 18:23:55 Sun hmdg-db1 [keepalived_notify]: umount sharedisk Apr 15 18:23:55 Sun hmdg-db1 [keepalived_notify]: umount /oradata success. Apr 15 18:23:55 Sun hmdg-db1 [keepalived_notify]: stopping listener... Apr 15 18:23:56 Sun hmdg-db1 [keepalived_notify]: The listener stop successfully [root@hmdg-db1 scripts]# ps -ef | grep ora_ root 97520 2451 0 18:26 pts/0 00:00:00 grep ora_ [root@hmdg-db1 scripts]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/sda3 ext4 50G 19G 29G 40% / tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/sda1 ext4 190M 40M 141M 22% /boot [root@hmdg-db1 scripts]# ip addr show dev eth2 3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:59:d5:91 brd ff:ff:ff:ff:ff:ff inet 172.16.10.25/24 brd 172.16.10.255 scope global eth2 inet6 fe80::20c:29ff:fe59:d591/64 scope link valid_lft forever preferred_lft forever
3、查看DB2是否转换为MASTER并接管服务
##系统日志 Apr 15 18:23:49 hmdg-db2 Keepalived_vrrp[88134]: VRRP_Instance(Oracle_HA_1) forcing a new MASTER election Apr 15 18:23:51 hmdg-db2 Keepalived_vrrp[88134]: VRRP_Instance(Oracle_HA_1) Transition to MASTER STATE Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: VRRP_Instance(Oracle_HA_1) Entering MASTER STATE Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: VRRP_Instance(Oracle_HA_1) setting protocol VIPs. Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.130 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:53 hmdg-db2 Keepalived_healthcheckers[88133]: Netlink reflector reports IP 172.16.10.130 added Apr 15 18:23:53 hmdg-db2 Keepalived_healthcheckers[88133]: Netlink reflector reports IP 172.16.10.131 added Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.131 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:53 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:57 hmdg-db2 kernel: EXT4-fs (sdb1): warning: maximal mount count reached, running e2fsck is recommended Apr 15 18:23:57 hmdg-db2 kernel: EXT4-fs (sdb1): mounted filesystem with ordered data mode. Opts: Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.130 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: VRRP_Instance(Oracle_HA_1) Sending/queueing gratuitous ARPs on eth2 for 172.16.10.131 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.130 Apr 15 18:23:58 hmdg-db2 Keepalived_vrrp[88134]: Sending gratuitous ARP on eth2 for 172.16.10.131 ##notify脚本日志 ------------------------------------------------------------------------------- Apr 15 18:23:53 Sun hmdg-db2 [keepalived_notify]: Transition to MASTER STATE Apr 15 18:23:53 Sun hmdg-db2 [keepalived_notify]: Setup the VIP on eth2 172.16.10.130,172.16.10.131 Apr 15 18:23:53 Sun hmdg-db2 [keepalived_notify]: Database Switchover To MASTER Apr 15 18:23:53 Sun hmdg-db2 [keepalived_notify]: Check remote node sharedisk mounted. Apr 15 18:23:53 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [1]... Apr 15 18:23:54 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [2]... Apr 15 18:23:56 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 is already mounted on remote node or busy. checking [3]... Apr 15 18:23:57 Sun hmdg-db2 [keepalived_notify]: /dev/sdb1 check passed. Apr 15 18:23:57 Sun hmdg-db2 [keepalived_notify]: mount /dev/sdb1 on /oradata Apr 15 18:23:57 Sun hmdg-db2 [keepalived_notify]: restore controlfile 1 ORACLE instance started. Total System Global Area 1603411968 bytes Fixed Size 2213776 bytes Variable Size 1056966768 bytes Database Buffers 536870912 bytes Redo Buffers 7360512 bytes Recovery Manager: Release 11.2.0.1.0 - Production on Sun Apr 15 18:23:58 2018 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. connected to target database: HMODB (not mounted) using target database control file instead of recovery catalog RMAN> Starting restore at 15-APR-18 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=572 device type=DISK channel ORA_DISK_1: copied control file copy output file name=/oradata/HMODB/control01.ctl output file name=/u01/app/oracle/flash_recovery_area/HMODB/control02.ctl output file name=/home/oracle/rman/HMODB/control03.ctl Finished restore at 15-APR-18 RMAN> Recovery Manager complete. Apr 15 18:23:59 Sun hmdg-db2 [keepalived_notify]: alter database to mount Database altered. Apr 15 18:24:04 Sun hmdg-db2 [keepalived_notify]: alter database to open Database altered. Apr 15 18:24:11 Sun hmdg-db2 [keepalived_notify]: Database opened. Apr 15 18:24:11 Sun hmdg-db2 [keepalived_notify]: Startup listener Apr 15 18:24:11 Sun hmdg-db2 [keepalived_notify]: listener already started. ##服务状态检查(Oracle进程、磁盘、VIP状态) [root@hmdg-db2 scripts]# ps -ef | grep ora_ oracle 88629 1 0 18:23 ? 00:00:00 ora_pmon_HMODB oracle 88631 1 0 18:23 ? 00:00:00 ora_vktm_HMODB oracle 88635 1 0 18:23 ? 00:00:00 ora_gen0_HMODB oracle 88637 1 0 18:23 ? 00:00:00 ora_diag_HMODB oracle 88639 1 0 18:23 ? 00:00:00 ora_dbrm_HMODB oracle 88641 1 0 18:23 ? 00:00:00 ora_psp0_HMODB oracle 88643 1 0 18:23 ? 00:00:00 ora_dia0_HMODB oracle 88645 1 0 18:23 ? 00:00:00 ora_mman_HMODB oracle 88647 1 0 18:23 ? 00:00:00 ora_dbw0_HMODB oracle 88649 1 0 18:23 ? 00:00:00 ora_lgwr_HMODB oracle 88651 1 0 18:23 ? 00:00:00 ora_ckpt_HMODB oracle 88653 1 0 18:23 ? 00:00:00 ora_smon_HMODB oracle 88655 1 0 18:23 ? 00:00:00 ora_reco_HMODB oracle 88657 1 0 18:23 ? 00:00:00 ora_mmon_HMODB oracle 88659 1 0 18:23 ? 00:00:00 ora_mmnl_HMODB oracle 88661 1 0 18:23 ? 00:00:00 ora_d000_HMODB oracle 88663 1 0 18:23 ? 00:00:00 ora_s000_HMODB oracle 88828 1 0 18:24 ? 00:00:00 ora_arc0_HMODB oracle 88843 1 0 18:24 ? 00:00:00 ora_arc1_HMODB oracle 88845 1 0 18:24 ? 00:00:00 ora_arc2_HMODB oracle 88847 1 0 18:24 ? 00:00:00 ora_arc3_HMODB oracle 88944 1 0 18:24 ? 00:00:00 ora_qmnc_HMODB oracle 89011 1 0 18:24 ? 00:00:00 ora_cjq0_HMODB oracle 89026 1 0 18:24 ? 00:00:00 ora_vkrm_HMODB oracle 89054 1 0 18:24 ? 00:00:00 ora_q000_HMODB oracle 89056 1 0 18:24 ? 00:00:00 ora_q001_HMODB root 90790 31390 0 18:27 pts/2 00:00:00 grep ora_ [root@hmdg-db2 scripts]# df -Th Filesystem Type Size Used Avail Use% Mounted on /dev/sda3 ext4 50G 18G 30G 37% / tmpfs tmpfs 3.9G 909M 3.0G 24% /dev/shm /dev/sda1 ext4 190M 40M 141M 22% /boot /dev/sdb1 ext4 30G 6.0G 22G 22% /oradata [root@hmdg-db2 scripts]# ip addr show dev eth2 3: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:dd:d1:7f brd ff:ff:ff:ff:ff:ff inet 172.16.10.26/24 brd 172.16.10.255 scope global eth2 inet 172.16.10.130/24 scope global secondary eth2 inet 172.16.10.131/24 scope global secondary eth2 inet6 fe80::20c:29ff:fedd:d17f/64 scope link valid_lft forever preferred_lft forever
结尾
本篇中主要的重点再在于测试部分。关于如何设计数据库高可用集群方案可作为参考
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





