如何进行Prometheus的数据库监控,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
传统监控系统,会面临哪些问题?
以zabbix为例 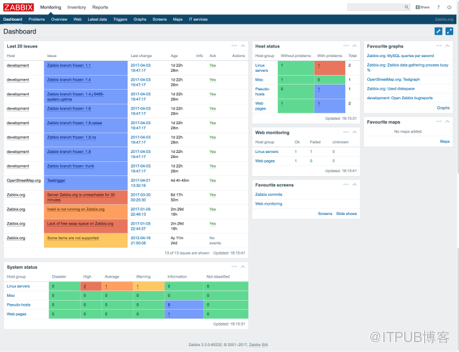
初次使用需要配置大量管理功能,随着服务器和业务的增长会发现zabbix,这种传统监控面临很多问题
DB性能瓶颈,由于zabbix会将采集到的性能指标都存储到数据库中,当服务器数量和业务增长很快时数据库性能首先成为瓶颈。
多套部署,管理成本高,当数据库性能成为瓶颈时首先想到的办法可能时分多套zabbix部署,但是又会带来管理很维护成本很高的问题。
易用性差,zabbix的配置和管理非常复杂,很难精通。
邮件风暴,邮件配置各种规则相当复杂,一不小心可能就容易造成邮件风暴的问题。
随着容器技术的发展,传统监控系统面临更多问题
容器如何监控?
微服务如何监控?
集群性能如何进行分析计算?
如何管理agent端大量配置脚本?
我们可以看到传统监控系统无法满足,当前IT环境下的监控需求
2015年Google发表了一篇论文《Google使用Borg进行大规模集群的管理》

这篇论文也描述了Google集群的规模和面临的挑战
单集群上万服务器
几千个不同的应用
几十万个以上的jobs,而且动态增加或者减少
每个数据中心数百个集群
基于这样一个规模,Google的监控系统也面临巨大挑战,而Borg中的Borgmon监控系统就是为了应对这些挑战而生。
那么我们来看一下Google如何做大规模集群的监控系统
首先,Borg集群中运行的所有应用都需要暴露出特定的URL,http://<app>:80/varz 通过这个URL我们就可以获取到应用所暴露的全部监控指标。

然而这样的应用有数千万个,而且可能会动态增加或者减少,Borgmon中如何发现这些应用呢?Borg中的应用启动时会自动注册到Borg内部的域名服务器BNS中,Borgmon通过读取BNS中应用列表信息,收集到应用列表,从而发现有哪些应用服务需要监控。当获取到应用列表后,就会将应用的全部监控变量值拉取到Borgmon系统中。 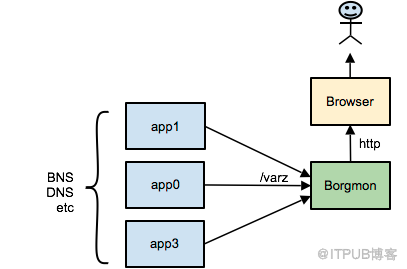
当监控指标收集到Borgmon中,就可以进行展现或者提供给告警使用,另外由于一个集群实在是太过庞大了,一个Borgmon可能无法满足整个集群的监控采集和展现需求,所以一般会在一些复杂的环境下,一个数据中心可能部署多个Borgmon,分为数据收集层和汇总层,数据收集层会有多个Borgmon专门用来到应用中收集数据,汇总层Borgmon则从数据收集层Borgmon中获取数据。 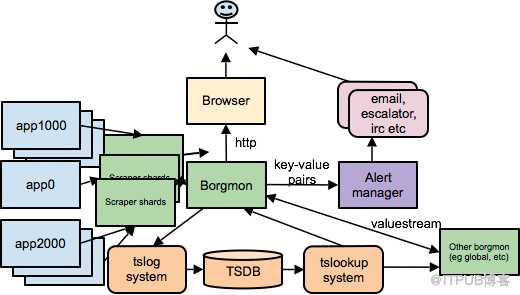
Borgmon收集到了性能指标数据后,会把所有的数据存储在内存数据库里,定时checkpoint到磁盘上,并且会周期性的打包到外部的系统TSDB。通常情况下,数据中心和全局Borgmon中一般至少会存放12小时左右的数据量,以便渲染图表使用。每个数据点大概占用24字节的内存,所以存放100万个time-series,每个time-series每分钟一个数据点,同时保存12小时数据,仅需17GB内存。 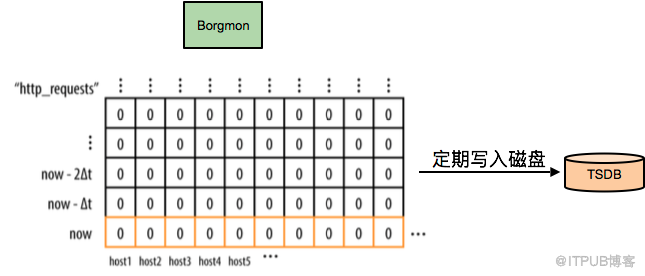
Borgmon中通过标签的方式查询指标,基于标签过滤我们可以查询到某个应用的具体指标,也可以查询更高维度的信息
基于标签过滤信息,比如我们基于一组过滤信息查询到host0:80这个app的http_requests 
我们也可以查询到整个美国西部,job为webserver的http_requests 
那么这个时候拿到的就是所有符合条件的实例的列表 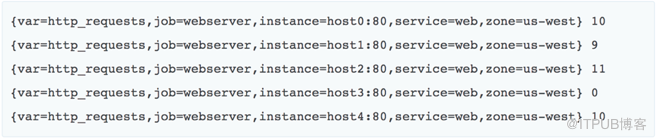
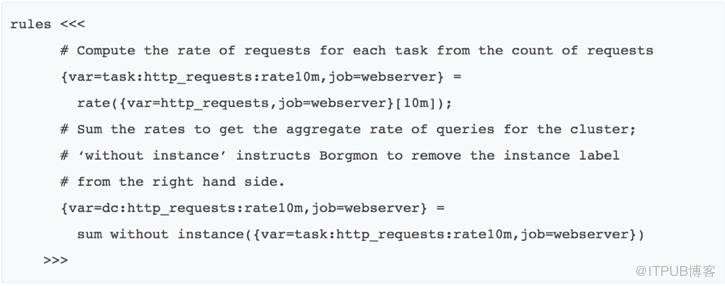
在数据收集和存储的基础之上,我们可以通过规则计算得到进一步的数据。
比如,我们想在web server报错超过一定比例的时候报警,或者说在非200返回码,占总请求的比例超过某个值的时候报警。 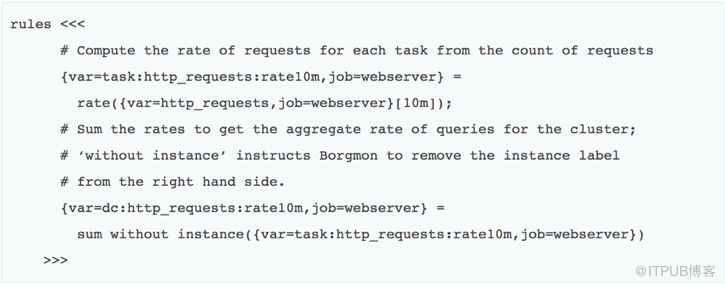
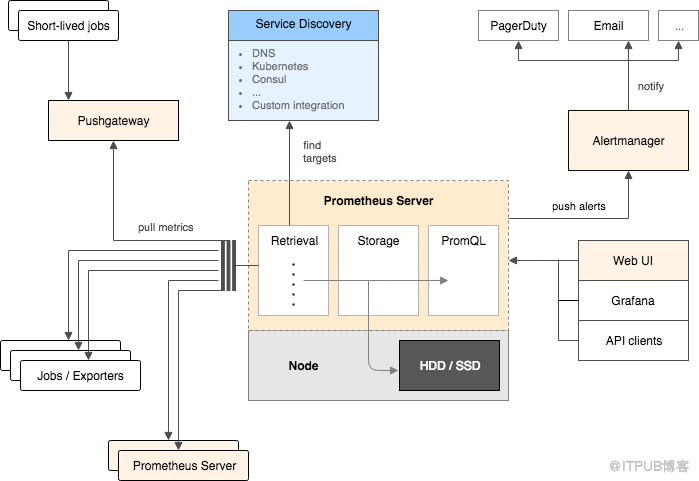
Borgmon是Google内部的系统,那么在Google之外如何使用它呢?这里就提到我们所描述的Prometheus这套监控系统。Google内部SRE工程师的著作《Google SRE》这本书中,直接就提到了Prometheus相当于就是开源版本的Borgmon。目前Prometheus在开源社区也是相当火爆,由Google发起Linux基金会旗下的原生云基金会(CNCF)就将Prometheus纳入其下第二大开源项目(第一项目为Kubernetes,为Borg的开源版本)。
Prometheus整体架构和Borgmon类似,组件如下,有些组件是可选的:
Prometheus主服务器,用来收集和存储时间序列数据
应用程序client代码库
短时jobs的push gateway
特殊用途的exporter(包括HAProxy、StatsD、Ganglia等)
用于报警的alertmanager
命令行工具查询
另外Grafana是作为Prometheus Dashboard展现的绝佳工具
基于Prometheus的数据库指标采集,我们以MySQL为例,由于MySQL没有暴露采集性能指标的接口,我们可以单独启动一个mysql_exporter,通过mysql_exporter到MySQL数据库上抓去性能指标,并暴露出性能采集接口提供给Prometheus,另外我们可以启动node_exporter用于抓取主机的性能指标。 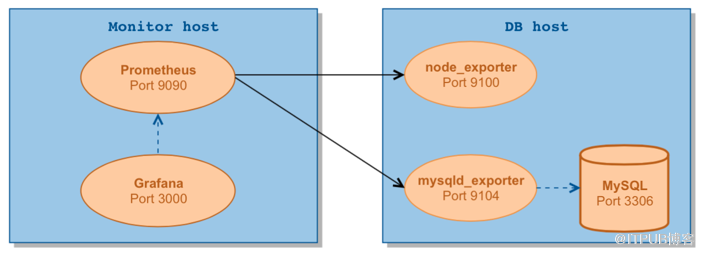
对于服务端配置非常简单,由于Prometheus全部基于Go语言开发,而Go语言程序在安装方面非常方便,安装服务端程序只需要下载,解压并运行即可。可以看到服务端常用程序也比较少,只需要包含prometheus这个主服务程序和alertmanager这个告警系统程序。 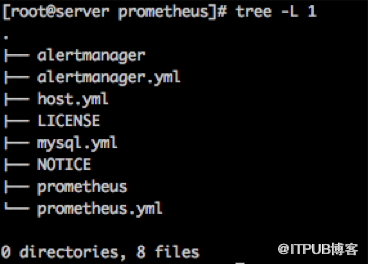
服务端配置也非常简单,常用配置包含拉取时间和具体采集方式,就我们监控mysql数据库来讲,只需要填入mysql_exporter地址即可。 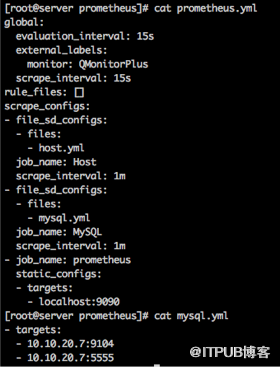
对于mysql采集只需要配置连接信息,并启动mysql_exporter即可 
完成配置之后即可通过mysql_exporter采集mysql性能指标 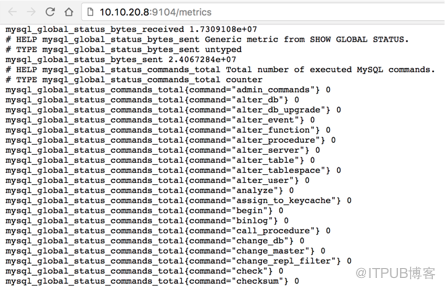
然后我们在prometheus服务端也可以查询到采集的mysql性能指标 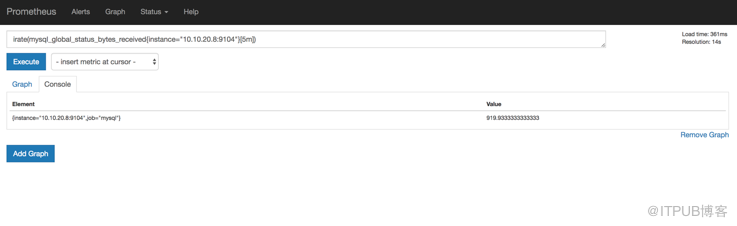
基于这些采集指标和Prometheus提供的规则计算语句,我们可以实现一些高纬度的查询需求,比如,increase(mysql_global_status_bytes_received{instance="$host"}[1h])
我们可以查询MySQL每小时接受到的字节数,然后我们将这个查询放到Grafana中,就可以展现非常酷炫的性能图表。
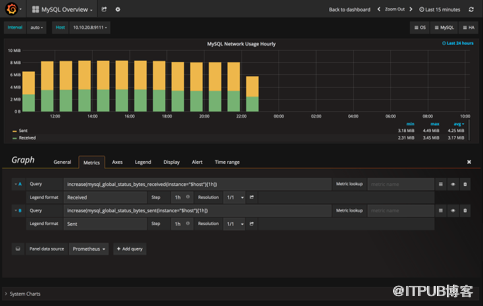
而目前结合Prometheus和Grafana的MySQL监控方案已经有开源实现,我们很轻松可以搭建一套基于Prometheus的监控系统 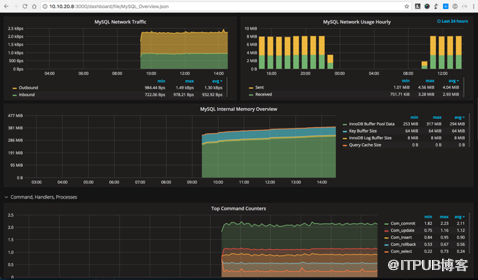
对于告警方面我们也可以基于Prometheus丰富的查询语句实现复杂告警逻辑
比如我们要对MySQL备库进行监控,如果复制IO线程未运行或者复制SQL线程未运行并且持续2分钟就发送告警我们可以使用如下这条告警规则。
# Alert: The replication IO or SQL threads are stopped. ALERT MySQLReplicationNotRunning IF mysql_slave_status_slave_io_running == 0 OR mysql_slave_status_slave_sql_running == 0 FOR 2m LABELS { severity = "critical" } ANNOTATIONS { summary = "Slave replication is not running", description = "Slave replication (IO or SQL) has been down for more than 2 minutes.", }在比如,我们要监控MySQL备库延迟大于30秒并且预测在未来2分钟之后大于0秒持续1分钟,则告警
# Alert: The replicaiton lag is non-zero and it predicted to not recover within
# 2 minutes. This allows for a small amount of replication lag. ALERT MySQLReplicationLag
IF (mysql_slave_lag_seconds > 30) AND on (instance) (predict_linear(mysql_slave_lag_seconds[5m], 60*2) > 0) FOR 1m LABELS { severity = "critical" } ANNOTATIONS { summary = "MySQL slave replication is lagging", description = "The mysql slave replication has fallen behind and is not recovering", }当然在数据库方面不只是有MySQL的监控实现,目前业界也有很多其他开源实现,所以在数据库监控方面也能实现开箱即用的效果
看完上述内容,你们掌握如何进行Prometheus的数据库监控的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





