本篇文章为大家展示了基于云CPU和云GPU的TensorFlow是怎样的,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
我一直在Keras和TensorFlow上进行一些个人的深度学习项目,但是使用和等云服务进行深度学习的训练并不是免费的,作为个人项目的研究,我会额外关注开支,降低成本。因为CPU实例比GPU实例更加便宜,而且经过实际操作,我发现在这两者中,我的训练模型姿势慢了一点。因为我深入研究了这两种类型实例的定价机制,来以了解CPU是否更适合我的需求。
Google Compute Engine上的起价为0.745美元/小时。几个月前,Google 在现代英特尔 CPU架构上 CPU实例多达64个vCPU 。更重要的是,它们也可以用在可,这些在GCE上可存在24小时,可以在任何时候终止,但是花费大约是标准实例价格的20%。具有64个vCPU和57.6GB RAM的可抢占n1-highcpu-64实例以及使用Skylake CPU的额外费用为0.509美元/小时,约为GPU实例成本的2/3。
如果64个vCPU的模型训练速度与GPU相当(甚至稍微慢一点),那么使用CPU会更具成本效益。这是假设深度学习软件和GCE平台硬件以100%的效率运行,如果不是100%,那么通过缩减vCPU的数量和成本可能会更加经济实惠。
由于GPU是针对深度学习硬件的刀片解决方案,所以没有深度学习库的基准。得益于Google economies of scale,可抢占实例的存在使得成本出现了巨大的差异,所以相比于使用GPU,使用CPU来进行深度学习模型训练更具经济效益。
建立
我已经有了真实世界的深度学习用例、Docker容器环境的基准测试脚本,以及来自TensorFlow与CNTK文章的结果日志。通过设置CLI参数,可以对CPU和GPU实例做一些小的调整。我还重新构建了Docker容器以支持最新版本的TensorFlow(1.2.1),并创建了一个CPU版本的容器,该容器安装了CPU-appropriate TensorFlow库。
有一个明显的CPU特定的TensorFlow行为,如果从pip(如和教程推荐的)开始安装并开始在TensorFlow中训练模型,则会在控制台中看到以下警告:

为了解决这些警告,并从 / / 优化中受益,我们,并创建了来完成这个任务。在新容器中训练模型时,警告不再显示,而且提高了速度,减少了训练时间。
因此,我们可以使用Google Compute Engine测试三个主要案例:
Tesla K80 GPU实例。
64个Skylake vCPU实例,其中TensorFlow是通过pip安装的(以及8/16/32 vCPU的测试)。
64 Skylake vCPU实例,TensorFlow使用CPU指令来编译,(+ 8/16/32 vCPU)
结果
针对每种模型架构和软/硬件配置,我计算了相对于GPU实例训练的总训练时间,以运行提供的测试脚本的模型训练。在所有情况下,GPU 应该是最快的训练配置,并且具有更多处理器的系统应该比具有更少处理器的系统训练更快。
让我们开始手写加上常见的多层感知器(MLP)架构,以及密集的全连接层。训练时间越短越好。水平虚线下的所有配置都比GPU好; 虚线以上的所有配置都比GPU差。
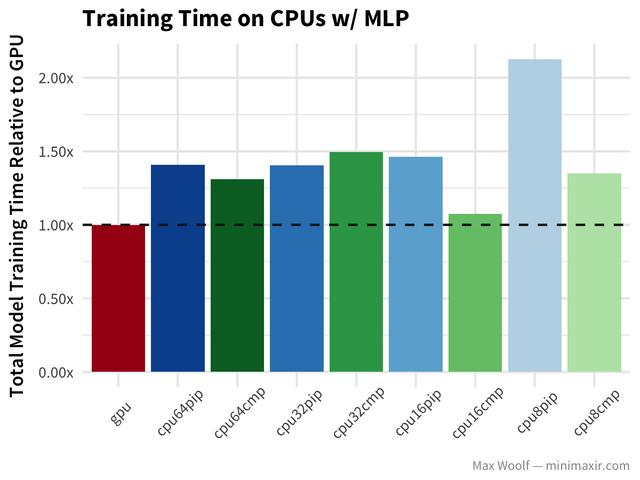
在这里,GPU是所有平台配置中最快的,但这其中还有一些很有趣的现象,例如32 vCPUs 和 64 vCPUs之间的性能相似,在编译TensorFlow库时,比8vCPUs和16 vCPUs的训练速度显著提升。也许在vCPUs之间有过多的协商信息,从而消除了更多vCPUs的性能优势,也许这些开销与编译TensorFlow的CPU指令不同。最后,它是一个黑盒,这就是为什么我喜欢黑盒基准测试所有硬件配置而不是理论制作。
由于不同vCPU计数的训练速度之间的差异是最小的,因此通过缩小vCPU确实具有优势。对于每种模型架构和配置,我计算相对于GPU实例训练成本的规范化训练成本。因为GCE实例成本是按比例分配的(与Amazon EC2不同),所以我们可以简单地通过将实验运行的总秒数乘以实例的成本(每秒)来计算实验成本。理想情况下,我们想要最小化成本。
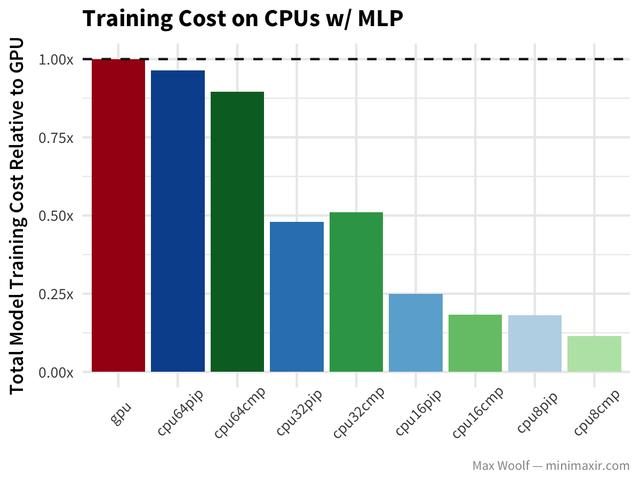
越低越好,较低的CPU数量对于这个问题来说更具成本效益。
现在,让我们看一下卷积神经网络(CNN)数字分类方法相同的数据集:
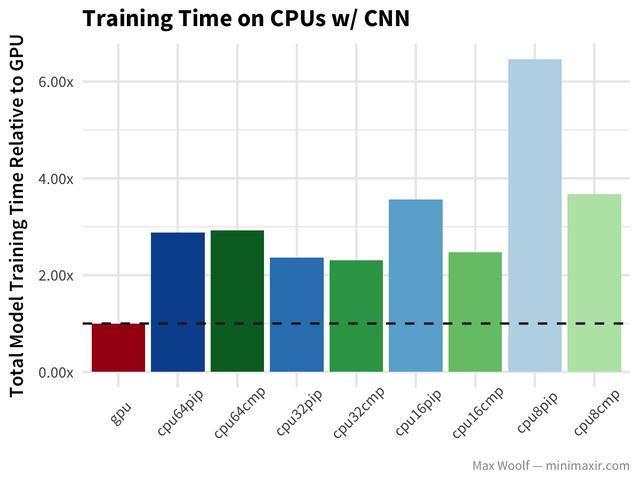
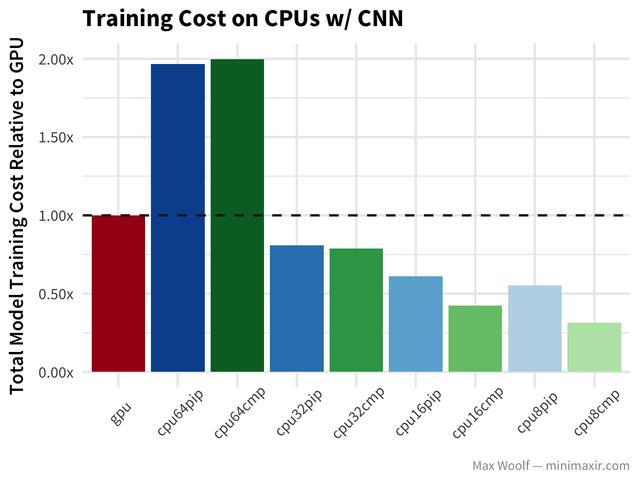
GPU比CNN上任何CPU的速度都要快两倍,但成本结构却相同,除了64 vCPU 的成本比GPU更低。32 vCPU的训练速度要比64vCP快。
让我们深入了解CNNs,看看cifar - 10图像分类数据集,以及利用deep covnet + a multilayer perceptron和理想图像分类的模型(类似于vgg16架构)。
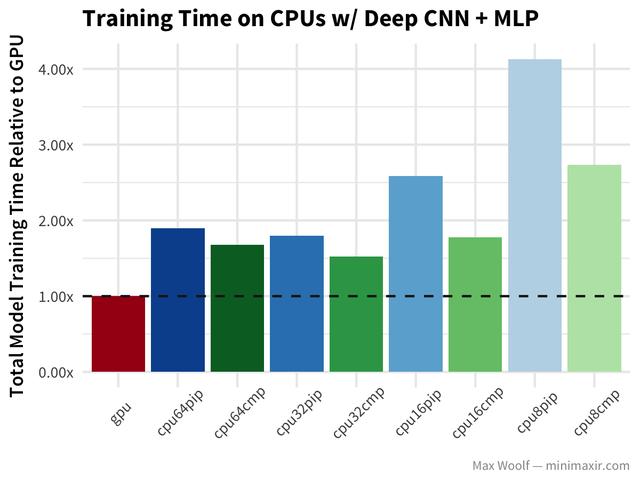
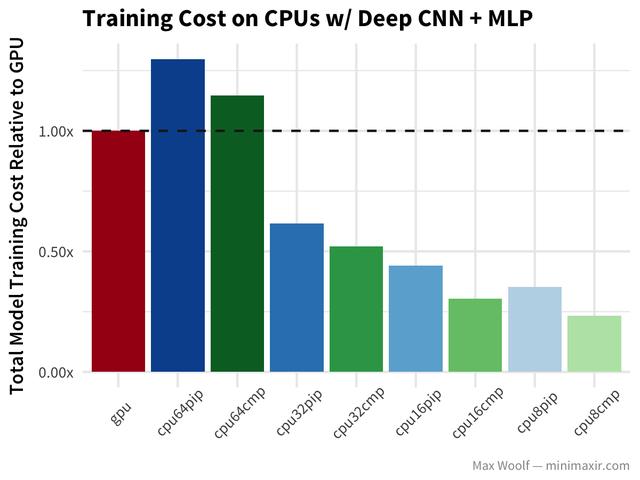
与简单的CNN案例中的类似行为相比,在这个实例中,所有的cpu在编译后的TensorFlow库中执行得更好。
在IMDb reviews dataset上使用的fasttext算法可以判断一个评论是积极的还是消极的,与其他方法相比,它的分类速度非常快。
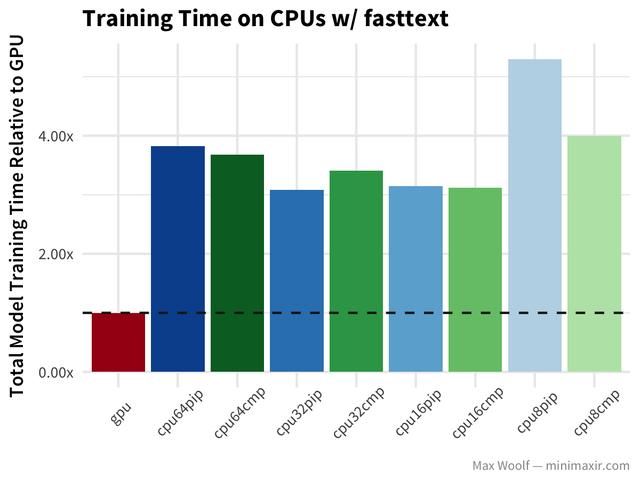
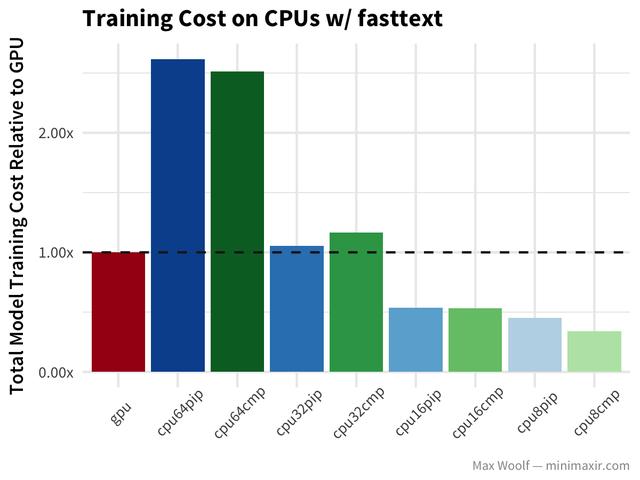
在这种情况下,GPU比CPU要快得多。降低CPU数量的好处并不那么明显。尽管作为一个备用方案,正式的fasttext实现是为大量CPU设计的,并且可以更好地处理并行化。
Bidirectional long-short-term memory(LSTM)架构非常适合处理像IMDb评论这样的文本数据,但是在我之前的基准测试文章之后,注意到TensorFlow在GPU上使用了LSTM的低效实现,所以差异会更加显着。
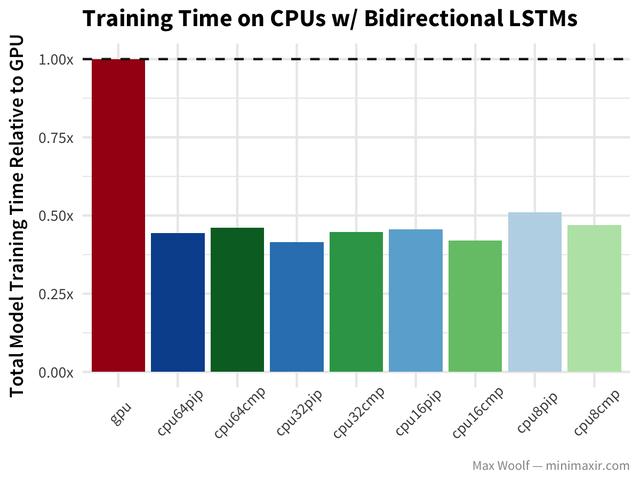
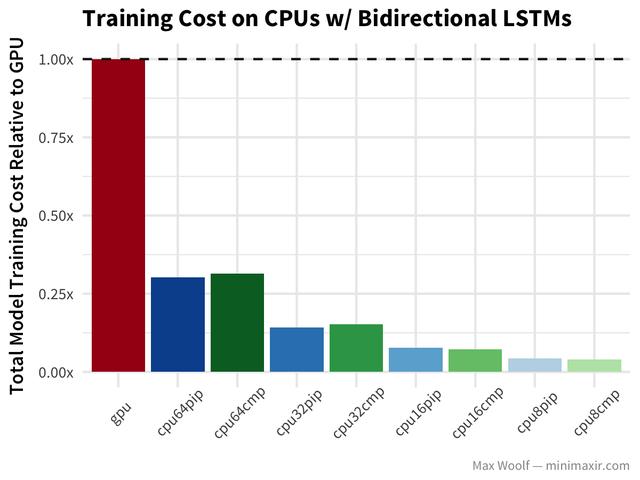
等等,什么?双向LSTMs的GPU训练是CPU配置的两倍。 (公平地说,基准使用Keras LSTM default of implementation=0,CPU表现更好更好,而LSTM default of implementation=2,GPU表现更好,但是双方之间的差距不会很大。)
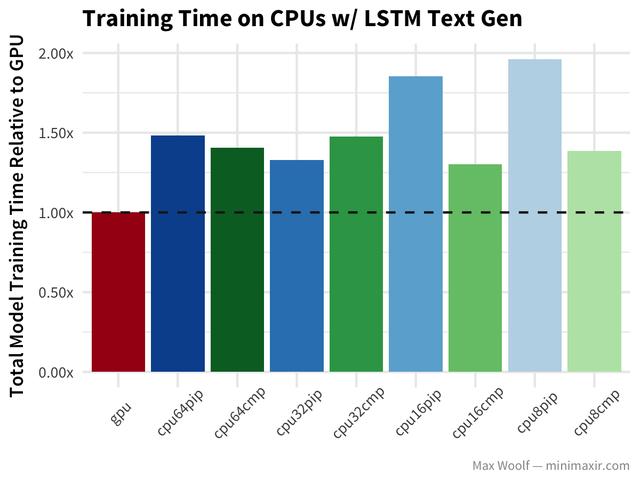
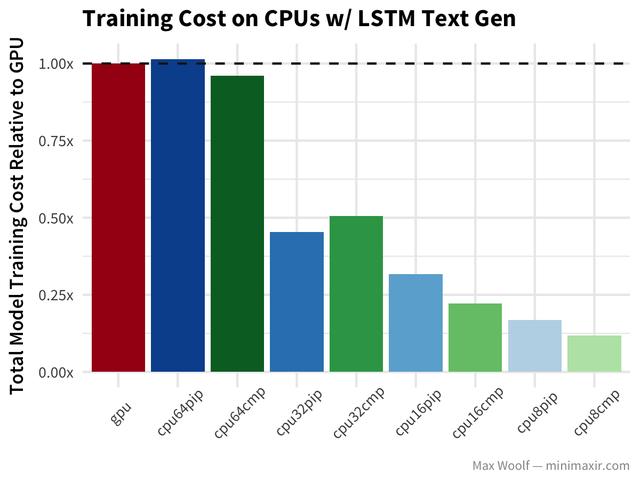
最后,Nietzsche著作的LSTM文本生成遵循与其他体系结构相似的模式,但是没有对GPU的巨大冲击。
结论
事实证明,64vcpu在深度学习的应用中并不具备经济效益,当前的软硬件架构并不能充分利用它们,所以使得64 vCPU总是和32vCPU性能相似,甚至还会更糟。在训练速度和成本方面,使用16vCPUs + compiled TensorFlow的训练模型似乎表现更好。编译后的TensorFlow库有30% - 40%的速度提升是一个意外的惊喜。我很惊讶谷歌竟然没有提供一个预编译版本的TensorFlow。
这里所显示的成本优势,仅在可抢占的情况下是不可能的。谷歌计算引擎的普通高CPU实例的成本大约为5x,因此完全消除了成本效益。
使用云CPU训练方法的一个主要隐含假设是,你不需要ASAP的训练模式。在专业的用例中,可能太浪费时间了,但是在个人用例中,一个人可能一晚上就离开模型训练,这是一个极具成本效益的好选择。
上述内容就是基于云CPU和云GPU的TensorFlow是怎样的,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





