这篇文章主要讲解了Django在不停机的情况下创建索引的方法,内容清晰明了,对此有兴趣的小伙伴可以学习一下,相信大家阅读完之后会有帮助。
该框架在管理数据库更改方面非常强大和有用,但是该框架提供的灵活性受到了一定的限制。为了理解Django迁移的局限性,你将处理一个众所周知的问题:在不停机的情况下,在Django中创建一个索引。
在本教程中,你将学习:
Django如何以及何时生成新的迁移;
如何检查Django生成的执行迁移的命令;
如何安全地修改迁移以满足你的需求。
本中级教程是为已经熟悉Django迁移(Migration)的读者设计的。
在Django迁移中创建索引的问题
当应用程序存储的数据增长时,通常需要进行的一个常见更改就是添加索引。索引可以用来加快查询速度,并使你的应用程序运行和响应更快。
在大多数数据库中,添加索引时需要对表使用独占锁。在创建索引时,独占锁会防止数据修改(DML)操作,如UPDATE,INSERT,和DELETE。
数据库在执行某些操作时会隐式地获取锁。例如,当用一个户登录到你的应用程序时,Django将更新auth_user表中的last_login字段。要执行更新,数据库首先必须在这个行上获得一个锁。如果该行当前被另一个连接锁定,那么你会得到一个数据库异常。
当需要在迁移期间保持系统可用时,锁定表可能会造成问题。表越大,创建索引所需的时间就越长。创建索引所需的时间越长,系统不可用或对用户无响应的时间就越长。
一些数据库供应商提供了一种创建索引而不锁定表的方法。例如,要在PostgreSQL中创建索引而不锁定表,你可以使用CONCURRENTLY关键字:

在Oracle中,有一个ONLINE选项允许在创建索引时对表执行DML操作:

在生成迁移时,Django不会使用这些特殊的关键字。按原样运行迁移将使数据库获得表上的独占锁,并在创建索引时防止DML操作。
并发创建索引有一些注意事项。提前了解特定于数据库后端的问题是很重要的。例如,PostgreSQL中的一个警告是并发创建索引需要更长的时间,因为它需要进行额外的表扫描。
在本教程中,你将使用Django迁移在一个大型表上创建索引,而不会导致任何停机。
注意:要学习本教程,建议你使用PostgreSQL后端,Django2.x和python3。
也可以使用其他数据库后端。在使用PostgreSQL特有的SQL特性的地方,更改SQL以匹配你的数据库后端。
设置
你将在一个名为app的应用中使用一个虚构的Sale模型。在现实生活中,Sale等模型是数据库中的主要表,它们通常会非常大,并存储大量数据:
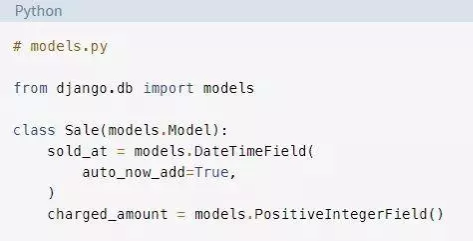
创建表,生成初始迁移并应用它:
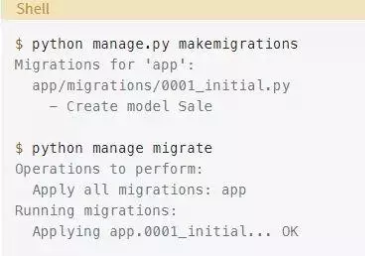
一段时间之后,sales表变得非常大,用户开始抱怨速度太慢。在监视数据库时,你注意到许多查询使用sold_at列。为了加快速度,你决定在列上需要一个索引。
要在sold_at上添加索引,你需要对模型进行以下更改:
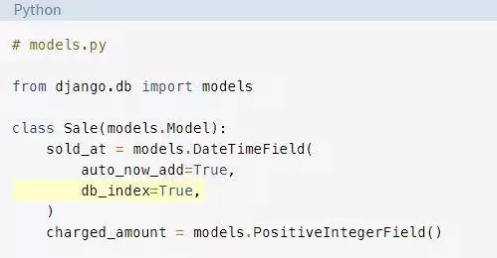
如果按原样运行这个迁移,那么Django将在表上创建索引,并且它将被锁定,直到索引完成。在非常大的表上创建索引可能需要一段时间,你希望避免停机。
在具有小数据集和很少连接的本地开发环境中,这种迁移可能是瞬间完成的。然而,对于具有许多并发连接的大型数据集,获取锁并创建索引可能需要一段时间。
在接下来的步骤中,你将修改Django创建的迁移,以便在不引起任何停机的情况下创建索引。
伪造迁移
第一种方法是手动创建索引。你将生成迁移,但实际上并不会让Django应用它。相反,你将在数据库中手动运行SQL,然后让Django认为迁移已经完成。
首先,生成迁移:
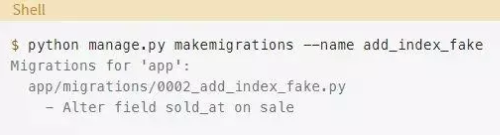
使用sqlmigrate命令来查看Django将用于执行此迁移的SQL:
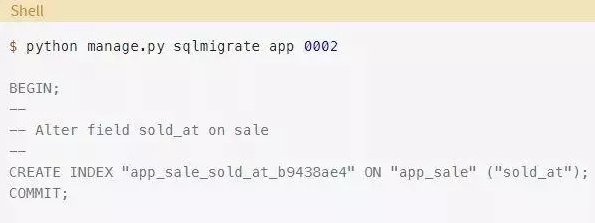
你希望在不锁定表的情况下创建索引,因此你需要修改命令。添加CONCURRENTLY关键字并在数据库中执行:
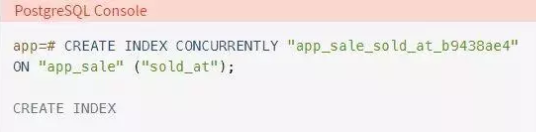
注意,你在执行命令的过程中没有BEGIN和COMMIT部分。省略这些关键字会在没有数据库事务的情况下执行命令。我们将在本文后面讨论数据库事务。
执行命令后,如果你尝试应用迁移,会出现以下错误:
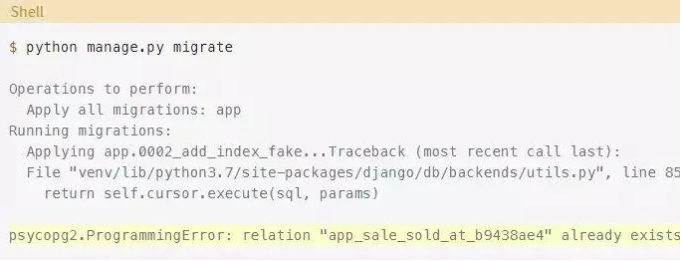
Django会提示你该索引已经存在,因此无法继续迁移。你刚刚在数据库中直接创建了索引,所以现在需要让Django认为已经应用了迁移。
如何伪造一个迁移
Django提供了一种内置的方法,可以将迁移标记为已执行,而不需要实际执行它们。要使用这个选项,你需要在应用迁移时设置—fake标志:
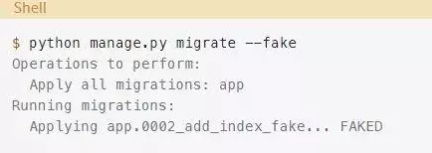
这一次Django没有抛出错误。实际上,Django并没有真正应用任何迁移。它只是将其标记为已执行(或FAKED)。
以下是在伪造迁移时需要考虑的一些问题:
手动命令必须与Django生成的SQL等价: 你需要确保所执行的命令与Django生成的SQL等价。使用sqlmigrate来生成SQL命令。如果命令不匹配,则可能导致数据库和模型状态之间的不一致。
其他未应用的迁移也将被伪造:当你有多个未应用的迁移时,它们都将被伪造。在应用迁移之前,重要的是确保只有你想要伪造的迁移没有应用。否则,你可能会得到不一致的结果。另一个选项是指定要伪造的确切迁移。
需要直接访问数据库:你需要在数据库中运行SQL命令,这有时也不是必需的。此外,在生产数据库中直接执行命令是危险的,应该尽可能避免。
自动化部署流程可能需要调整:如果你自动化了部署流程(使用CI、CD或其他自动化工具),那么你可能需要将流程更改为伪迁移。这并不总是可取的。
清理
在继续下一节之前,你需要将数据库恢复到它在初始迁移之后的状态。要做到这一点,请迁移回初始迁移:
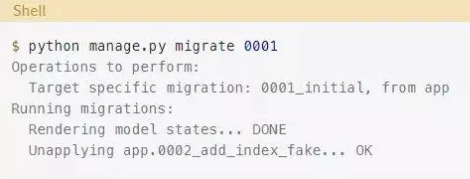
Django没有应用在第二次迁移中所做的更改,所以现在可以安全地删除文件:

为了确保你做的一切都是正确的,检查一下迁移:
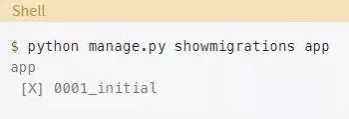
应用了初始迁移之后,就没有未应用的迁移了。
在迁移(Migration)中执行原始SQL
在上一节中,你直接在数据库中执行SQL并伪造迁移。这样就完成了任务,但是还有一个更好的解决方案。
Django提供了一种使用RunSQL在迁移中执行原始SQL的方法。我们来尝试使用它代替直接在数据库中执行命令。
首先,生成一个新的空迁移:

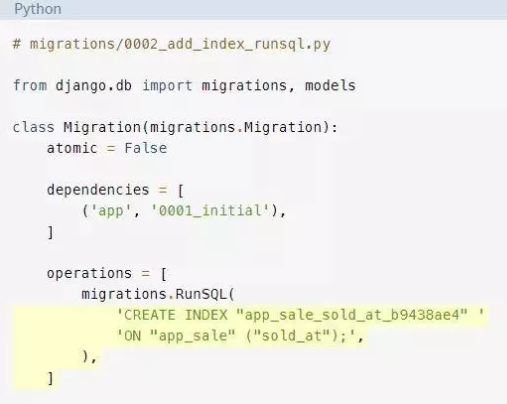
接下来,编辑迁移文件并添加RunSQL操作:
当你运行迁移时,你将获得以下输出:
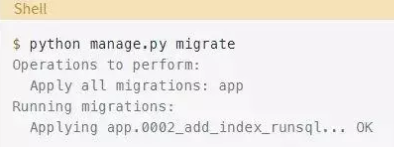
这看起来不错,但有一个问题。我们再次来尝试生成迁移:
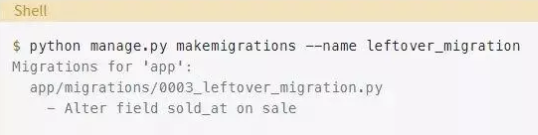
Django再次生成了相同的迁移。为什么会这样?
清理
在回答这个问题之前,你需要清理并撤消对数据库所做的更改。首先删除最后一次迁移。它没有被应用,所以可以安全删除:

接下来,列出app应用程序的迁移:
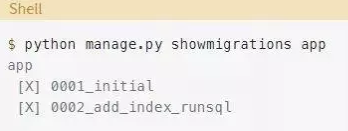
第三次迁移已经结束,但是只应用了第二次迁移。你希望回到初始迁移之后的状态。试着像你在上一节所做的那样迁移回初始迁移状态:
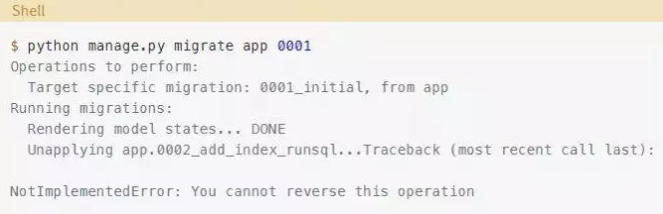
Django无法进行逆向迁移。
逆向迁移操作
要进行一次逆向迁移,Django会对每个操作执行相反的操作。在本例中,添加索引的反面是删除索引。正如你已经看到的,当一个迁移是可逆的时,你可以取消应用它。就像你可以在Git中使用checkout一样,如果你对较早的迁移执行了migrate命令,你可以进行逆向迁移。
许多内置迁移操作已经定义了反向操作。例如,添加字段的反向操作是删除对应的列,创建模型的反向操作是删除相应的表。
有些迁移操作是不可逆的。例如,删除字段或删除模型没有反向操作,因为一旦应用了迁移,数据就会消失。
在上一节中,你使用了RunSQL操作。当你试图进行反向迁移时,遇到了一个错误。根据错误提示,迁移中的一个操作不能逆转。Django默认情况下无法反转原始SQL。因为Django不知道该操作执行了什么,所以它不能自动生成相反的操作。
如何使迁移可逆
要使一个迁移是可逆的,迁移中的所有操作都必须是可逆的。只逆转迁移的一部分是不可能的,因此一个单一的不可逆操作将使整个迁移不可逆。
要使RunSQL操作可逆,你必须提供在操作反转时执行的SQL。反向SQL在reverse_sql参数中提供。
添加索引的相反操作是删除索引。要使你的迁移可逆,请提供reverse_sql参数来删除索引:
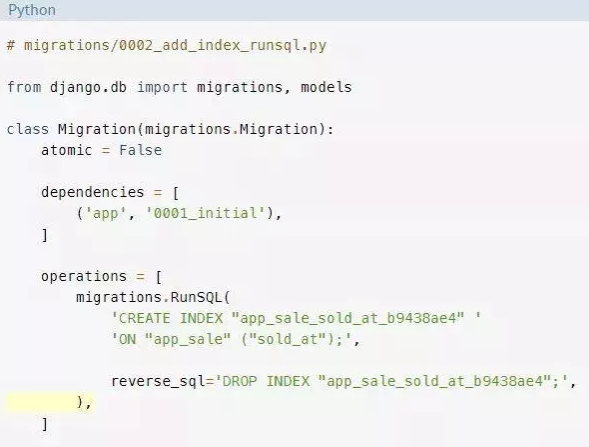
现在试着反转迁移:

我们对第二次迁移进行了反转,Django删除了索引。现在可以安全地删除迁移文件了:

提供reverse_sql总是一个好主意。在反转原始SQL操作而不需要其他任何操作的情况下,你可以使用特殊的哨兵语句migrations.
RunSQL.noop将该操作标记为可逆操作。

理解模型状态和数据库状态
在你之前尝试使用RunSQL手动创建索引时,Django一次又一次地生成了相同的迁移,尽管索引是在数据库中创建的。要理解Django为什么这样做,你首先需要理解Django如何决定何时生成新的迁移。
当Django生成一个新的迁移时
在生成和应用迁移的过程中,Django同步数据库状态和模型状态。例如,当你向模型添加字段时,Django会向表添加一列。当你从模型中删除字段时,Django将从表中删除列。
为了在模型和数据库之间同步,Django拥有一个表示模型的状态。为了使数据库与模型同步,Django会生成迁移操作。迁移操作转换为可以在数据库中执行的特定供应商的SQL。当所有迁移操作都执行后,数据库和模型应该是一致的。
为了获得数据库的状态,Django聚合了所有过去迁移的操作。当迁移的聚合状态与模型的状态不一致时,Django会生成一个新的迁移。
在前面的例子中,你使用原始SQL创建了索引。Django不知道你创建了索引,因为你没有使用熟悉的迁移操作。
当Django聚合所有迁移并将它们与模型的状态进行比较时,它发现缺少一个索引。这就是为什么即使你手动创建了索引,Django仍然认为它是缺失的,并为它生成了一个新的迁移。
如何在迁移中分离数据库和状态
由于Django无法按照你希望的方式创建索引,所以你希望提供自己的SQL,但仍然要让Django知道你已经创建了索引。
换句话说,你需要在数据库中执行一些操作,并为Django提供迁移操作来同步其内部状态。为此,Django为我们提供了一个名为 SeparateDatabaseAndState的特殊迁移操作。这项操作并不为人所知,应该留到像这种特殊情况下使用。
编辑迁移要比从头开始写容易的多,因此,首先以通常的方式生成一个迁移:
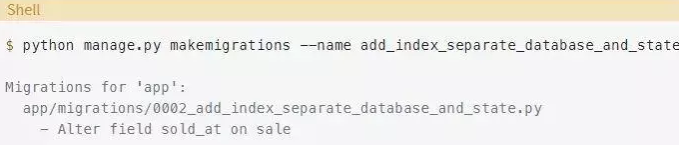
这是Django生成的迁移内容,和之前一样:
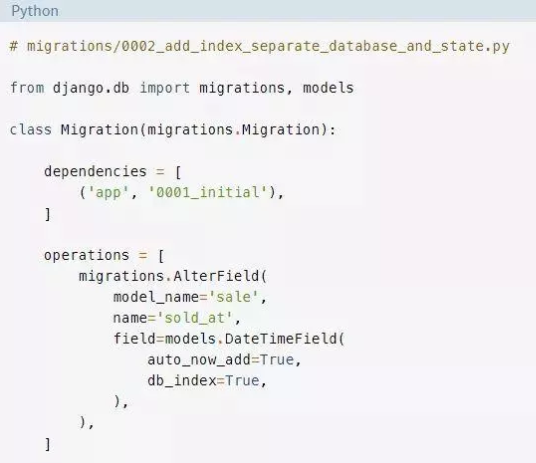
Django在字段sold_at上生成了一个AlterField操作。该操作会创建一个索引并更新状态。我们希望保留这个操作,但是在数据库中提供一个不同的命令来执行。
同样,要获得该命令,请使用Django生成的SQL:

在合适的地方添加CONCURRENTKY关键字:

接着,编辑该迁移文件,并使用SeparateDatabaseAndState来提供你修改过的SQL命令并执行:

迁移操作separate atabaseandstate接受2个操作列表:
1.state_operations是应用于内部模型状态的操作。它们不会影响数据库。
2.database_operations是应用于数据库的操作。
你在state_operations中保留了Django生成的原始操作。当使用SeparateDatabaseAndState时,这是你通常想要做的,注意向字段提供db_index=True参数。这个迁移操作将让Django知道字段上有一个索引。
你使用了Django生成的SQL并添加了CONCURRENTLY关键字。你使用特殊的操作RunSQL来在迁移中执行原始SQL。
如果你试图运行此迁移,你将获得以下输出:
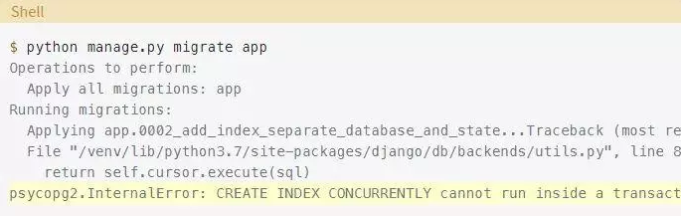
非原子迁移
在SQL中,CREATE、DROP、ALTER和TRUNCATE操作称为数据定义语言(Data Definition Language, DDL)。在支持事务性DDL的数据库中,比如PostgreSQL,Django默认会在数据库事务中执行迁移。然而,根据上面的错误,PostgreSQL不能在事务块中并发地创建索引。
为了能够在迁移中并发地创建索引,你需要告诉Django不要在数据库事务中执行迁移。为此,通过将atomic设置为False,将迁移标记为非原子(non-atomic):
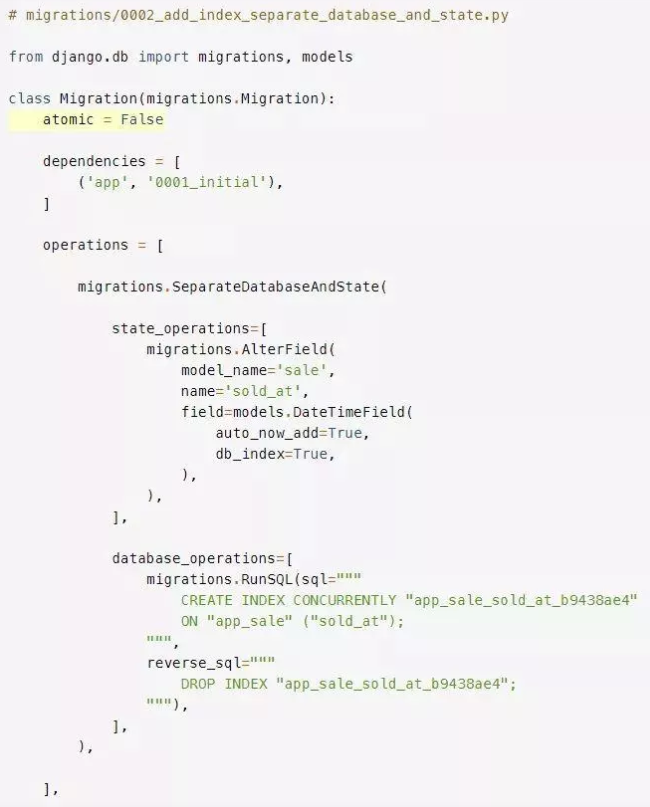
将迁移标记为非原子之后,你可以运行迁移了:
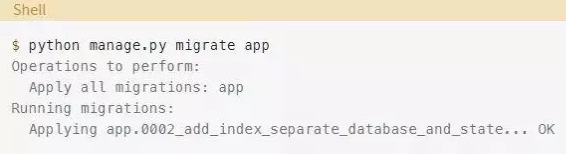
你只是执行了迁移,并没有引起任何停机。
下面是使用SeparateDatabaseAndState时需要考虑的一些问题
数据库操作必须与状态操作等价:数据库和模型状态之间的不一致可能会造成很多麻烦。一个好的开始是保留Django在 state_operations中生成的操作和编辑sqlmigrate的输出并在database_operations中使用。
非原子迁移在发生错误时不能回滚:如果在迁移过程中出现错误,则无法回滚。你必须要么回滚迁移,要么手动完成它。将在非原子迁移中执行的操作保持在最少是一个好主意。如果你在迁移中有其他操作,请将它们移到新的迁移中。
迁移可能是特定于供应商的:Django生成的SQL特定于项目中使用的数据库后端。它可能会在其他数据库后端运行,但这并不能保证。如果你需要支持多个数据库后端,则需要对这种方法进行一些调整。
结论:
你从一个大型的数据表和一个问题开始了本教程。你想让你的应用程序对用户来说更快,你想在不引起应用程序任何停机的情况下做到这一点。
在本教程的最后,你尝试生成并安全地修改了一个Django迁移来实现这一目标。在此过程中,你遇到了不同的问题,并使用migration 框架提供的内置工具设法解决了这些问题。
在本教程中,你学习了以下内容:
模型与数据库状态的分离是一个重要的概念。一旦你理解了它,以及知道如何使用它,你就可以突破内置迁移操作的许多限制。我想到的一些用例包括添加已经在数据库中创建的索引,以及为DDL命令提供特定的服务商参数。
看完上述内容,是不是对Django在不停机的情况下创建索引的方法有进一步的了解,如果还想学习更多内容,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



