前言
SpringBoot是Spring的包装,通过自动配置使得SpringBoot可以做到开箱即用,上手成本非常低,但是学习其实现原理的成本大大增加,需要先了解熟悉Spring原理。如果还不清楚Spring原理的,可以先查看博主之前的文章,本篇主要分析SpringBoot的启动、自动配置、Condition、事件驱动原理。
正文
启动原理
SpringBoot启动非常简单,因其内置了Tomcat,所以只需要通过下面几种方式启动即可:
@SpringBootApplication(scanBasePackages = {"cn.dark"})
public class SpringbootDemo {
public static void main(String[] args) {
// 第一种
SpringApplication.run(SpringbootDemo .class, args);
// 第二种
new SpringApplicationBuilder(SpringbootDemo .class)).run(args);
// 第三种
SpringApplication springApplication = new SpringApplication(SpringbootDemo.class);
springApplication.run();
}
}
可以看到第一种是最简单的,也是最常用的方式,需要注意类上面需要标注@SpringBootApplication注解,这是自动配置的核心实现,稍后分析,先来看看SpringBoot启动做了些什么?
在往下之前,不妨先猜测一下,run方法中需要做什么?对比Spring源码,我们知道,Spring的启动都会创建一个ApplicationContext的应用上下文对象,并调用其refresh方法启动容器,SpringBoot只是Spring的一层壳,肯定也避免不了这样的操作。
另一方面,以前通过Spring搭建的项目,都需要打成War包发布到Tomcat才行,而现在SpringBoot已经内置了Tomcat,只需要打成Jar包启动即可,所以在run方法中肯定也会创建对应的Tomcat对象并启动。
以上只是我们的猜想,下面就来验证,进入run方法:
public ConfigurableApplicationContext run(String... args) {
// 统计时间用的工具类
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
// 获取实现了SpringApplicationRunListener接口的实现类,通过SPI机制加载
// META-INF/spring.factories文件下的类
SpringApplicationRunListeners listeners = getRunListeners(args);
// 首先调用SpringApplicationRunListener的starting方法
listeners.starting();
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
// 处理配置数据
ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);
configureIgnoreBeanInfo(environment);
// 启动时打印banner
Banner printedBanner = printBanner(environment);
// 创建上下文对象
context = createApplicationContext();
// 获取SpringBootExceptionReporter接口的类,异常报告
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
prepareContext(context, environment, listeners, applicationArguments, printedBanner);
// 核心方法,启动spring容器
refreshContext(context);
afterRefresh(context, applicationArguments);
// 统计结束
stopWatch.stop();
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass).logStarted(getApplicationLog(), stopWatch);
}
// 调用started
listeners.started(context);
// ApplicationRunner
// CommandLineRunner
// 获取这两个接口的实现类,并调用其run方法
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
// 最后调用running方法
listeners.running(context);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}
SpringBoot的启动流程就是这个方法,先看getRunListeners方法,这个方法就是去拿到所有的SpringApplicationRunListener实现类,这些类是用于SpringBoot事件发布的,关于事件驱动稍后分析,这里主要看这个方法的实现原理:
private SpringApplicationRunListeners getRunListeners(String[] args) {
Class<?>[] types = new Class<?>[] { SpringApplication.class, String[].class };
return new SpringApplicationRunListeners(logger,
getSpringFactoriesInstances(SpringApplicationRunListener.class, types, this, args));
}
private <T> Collection<T> getSpringFactoriesInstances(Class<T> type, Class<?>[] parameterTypes, Object... args) {
ClassLoader classLoader = getClassLoader();
// Use names and ensure unique to protect against duplicates
Set<String> names = new LinkedHashSet<>(SpringFactoriesLoader.loadFactoryNames(type, classLoader));
// 加载上来后反射实例化
List<T> instances = createSpringFactoriesInstances(type, parameterTypes, classLoader, args, names);
AnnotationAwareOrderComparator.sort(instances);
return instances;
}
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
String factoryTypeName = factoryType.getName();
return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList());
}
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories";
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
MultiValueMap<String, String> result = cache.get(classLoader);
if (result != null) {
return result;
}
try {
Enumeration<URL> urls = (classLoader != null ?
classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
result = new LinkedMultiValueMap<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
UrlResource resource = new UrlResource(url);
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
for (Map.Entry<?, ?> entry : properties.entrySet()) {
String factoryTypeName = ((String) entry.getKey()).trim();
for (String factoryImplementationName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) {
result.add(factoryTypeName, factoryImplementationName.trim());
}
}
}
cache.put(classLoader, result);
return result;
}
}
一步步追踪下去可以看到最终就是通过SPI机制根据接口类型从META-INF/spring.factories文件中加载对应的实现类并实例化,SpringBoot的自动配置也是这样实现的。
为什么要这样实现呢?通过注解扫描不可以么?当然不行,这些类都在第三方jar包中,注解扫描实现是很麻烦的,当然你也可以通过@Import注解导入,但是这种方式不适合扩展类特别多的情况,所以这里采用SPI的优点就显而易见了。
回到run方法中,可以看到调用了createApplicationContext方法,见名知意,这个就是去创建应用上下文对象:
public static final String DEFAULT_SERVLET_WEB_CONTEXT_CLASS = "org.springframework.boot."
+ "web.servlet.context.AnnotationConfigServletWebServerApplicationContext";
protected ConfigurableApplicationContext createApplicationContext() {
Class<?> contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
switch (this.webApplicationType) {
case SERVLET:
contextClass = Class.forName(DEFAULT_SERVLET_WEB_CONTEXT_CLASS);
break;
case REACTIVE:
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default:
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Unable create a default ApplicationContext, please specify an ApplicationContextClass", ex);
}
}
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}
注意这里通过反射实例化了一个新的没见过的上下文对象AnnotationConfigServletWebServerApplicationContext,这个是SpringBoot扩展的,看看其构造方法:
public AnnotationConfigServletWebServerApplicationContext() {
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
如果你有看过Spring注解驱动的实现原理,这两个对象肯定不会陌生,一个实支持注解解析的,另外一个是扫描包用的。上下文创建好了,下一步自然就是调用refresh方法启动容器:
private void refreshContext(ConfigurableApplicationContext context) {
refresh(context);
if (this.registerShutdownHook) {
try {
context.registerShutdownHook();
}
catch (AccessControlException ex) {
// Not allowed in some environments.
}
}
}
protected void refresh(ApplicationContext applicationContext) {
Assert.isInstanceOf(AbstractApplicationContext.class, applicationContext);
((AbstractApplicationContext) applicationContext).refresh();
}
这里首先会调用到其父类中ServletWebServerApplicationContext:
public final void refresh() throws BeansException, IllegalStateException {
try {
super.refresh();
}
catch (RuntimeException ex) {
stopAndReleaseWebServer();
throw ex;
}
}
可以看到是直接委托给了父类:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
这个方法不会陌生吧,之前已经分析过了,这里不再赘述,至此SpringBoot的容器就启动了,但是Tomcat启动是在哪里呢?run方法中也没有看到。实际上Tomcat的启动也是在refresh流程中,这个方法其中一步是调用了onRefresh方法,在Spring中这是一个没有实现的模板方法,而SpringBoot就通过这个方法完成了Tomcat的启动:
protected void onRefresh() {
super.onRefresh();
try {
createWebServer();
}
catch (Throwable ex) {
throw new ApplicationContextException("Unable to start web server", ex);
}
}
private void createWebServer() {
WebServer webServer = this.webServer;
ServletContext servletContext = getServletContext();
if (webServer == null && servletContext == null) {
ServletWebServerFactory factory = getWebServerFactory();
// 主要看这个方法
this.webServer = factory.getWebServer(getSelfInitializer());
}
else if (servletContext != null) {
try {
getSelfInitializer().onStartup(servletContext);
}
catch (ServletException ex) {
throw new ApplicationContextException("Cannot initialize servlet context", ex);
}
}
initPropertySources();
}
这里首先拿到TomcatServletWebServerFactory对象,通过该对象再去创建和启动Tomcat:
public WebServer getWebServer(ServletContextInitializer... initializers) {
if (this.disableMBeanRegistry) {
Registry.disableRegistry();
}
Tomcat tomcat = new Tomcat();
File baseDir = (this.baseDirectory != null) ? this.baseDirectory : createTempDir("tomcat");
tomcat.setBaseDir(baseDir.getAbsolutePath());
Connector connector = new Connector(this.protocol);
connector.setThrowOnFailure(true);
tomcat.getService().addConnector(connector);
customizeConnector(connector);
tomcat.setConnector(connector);
tomcat.getHost().setAutoDeploy(false);
configureEngine(tomcat.getEngine());
for (Connector additionalConnector : this.additionalTomcatConnectors) {
tomcat.getService().addConnector(additionalConnector);
}
prepareContext(tomcat.getHost(), initializers);
return getTomcatWebServer(tomcat);
}
上面的每一步都可以对比Tomcat的配置文件,需要注意默认只支持了http协议:
Connector connector = new Connector(this.protocol);
private String protocol = DEFAULT_PROTOCOL;
public static final String DEFAULT_PROTOCOL = "org.apache.coyote.http11.Http11NioProtocol";
如果想要扩展的话则可以对additionalTomcatConnectors属性设置值,需要注意这个属性没有对应的setter方法,只有addAdditionalTomcatConnectors方法,也就是说我们只能通过实现BeanFactoryPostProcessor接口的postProcessBeanFactory方法,而不能通过BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法,因为前者可以通过传入的BeanFactory对象提前获取到TomcatServletWebServerFactory对象调用addAdditionalTomcatConnectors即可;而后者只能拿到BeanDefinition对象,该对象只能通过setter方法设置值。
事件驱动
Spring原本就提供了事件机制,而在SpringBoot中又对其进行扩展,通过发布订阅事件在容器的整个生命周期的不同阶段进行不同的操作。我们先来看看SpringBoot启动关闭的过程中默认会发布哪些事件,使用下面的代码即可:
@SpringBootApplication
public class SpringEventDemo {
public static void main(String[] args) {
new SpringApplicationBuilder(SpringEventDemo.class)
.listeners(event -> {
System.err.println("接收到事件:" + event.getClass().getSimpleName());
})
.run()
.close();
}
}
这段代码会在控制台打印所有的事件名称,按照顺序如下:
ApplicationStartingEvent:容器启动
ApplicationEnvironmentPreparedEvent:环境准备好
ApplicationContextInitializedEvent:上下文初始化完成
ApplicationPreparedEvent:上下文准备好
ContextRefreshedEvent:上下文刷新完
ServletWebServerInitializedEvent:webServer初始化完成
ApplicationStartedEvent:容器启动完成
ApplicationReadyEvent:容器就绪
ContextClosedEvent:容器关闭
以上是正常启动关闭,如果发生异常还有发布ApplicationFailedEvent事件。事件的发布遍布在整个容器的启动关闭周期中,事件发布对象刚刚我们也看到了是通过SPI加载的SpringApplicationRunListener实现类EventPublishingRunListener,同样事件监听器也是在spring.factories文件中配置的,默认实现了以下监听器:
org.springframework.context.ApplicationListener=\
org.springframework.boot.ClearCachesApplicationListener,\
org.springframework.boot.builder.ParentContextCloserApplicationListener,\
org.springframework.boot.cloud.CloudFoundryVcapEnvironmentPostProcessor,\
org.springframework.boot.context.FileEncodingApplicationListener,\
org.springframework.boot.context.config.AnsiOutputApplicationListener,\
org.springframework.boot.context.config.ConfigFileApplicationListener,\
org.springframework.boot.context.config.DelegatingApplicationListener,\
org.springframework.boot.context.logging.ClasspathLoggingApplicationListener,\
org.springframework.boot.context.logging.LoggingApplicationListener,\
org.springframework.boot.liquibase.LiquibaseServiceLocatorApplicationListener可以看到有用于文件编码的(FileEncodingApplicationListener),有加载日志框架的(LoggingApplicationListener),还有加载配置的(ConfigFileApplicationListener)等等一系列监听器,SpringBoot也就是通过这系列监听器将必要的配置和组件加载到容器中来,这里不再详细分析,感兴趣的读者可以通过其实现的onApplicationEvent方法看到每个监听器究竟是监听的哪一个事件,当然事件发布和监听我们自己也是可以扩展的。
自动配置原理
SpringBoot最核心的还是自动配置,为什么它能做到开箱即用,不再需要我们手动使用@EnableXXX等注解来开启?这一切的答案就在@SpringBootApplication注解中:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {}
这里重要的注解有三个:@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan。@ComponentScan就不用再说了,@SpringBootConfiguration等同于@Configuration,而@EnableAutoConfiguration就是开启自动配置:
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
}
@Import(AutoConfigurationPackages.Registrar.class)
public @interface AutoConfigurationPackage {
}
@AutoConfigurationPackage注解的作用就是将该注解所标记类所在的包作为自动配置的包,简单看看就行,主要看AutoConfigurationImportSelector,这个就是实现自动配置的核心类,注意这个类是实现的DeferredImportSelector接口。在这个类中有一个selectImports方法。
这个方法在我之前的文章这一次搞懂Spring事务注解的解析也有分析过,只是实现类不同,它同样会被ConfigurationClassPostProcessor类调用,先来看这个方法做了些什么:
public String[] selectImports(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return NO_IMPORTS;
}
AutoConfigurationMetadata autoConfigurationMetadata = AutoConfigurationMetadataLoader
.loadMetadata(this.beanClassLoader);
// 获取所有的自动配置类
AutoConfigurationEntry autoConfigurationEntry = getAutoConfigurationEntry(autoConfigurationMetadata,
annotationMetadata);
return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
}
protected AutoConfigurationEntry getAutoConfigurationEntry(AutoConfigurationMetadata autoConfigurationMetadata,
AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
AnnotationAttributes attributes = getAttributes(annotationMetadata);
// SPI获取EnableAutoConfiguration为key的所有实现类
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
configurations = removeDuplicates(configurations);
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
// 把某些自动配置类过滤掉
configurations = filter(configurations, autoConfigurationMetadata);
fireAutoConfigurationImportEvents(configurations, exclusions);
// 包装成自动配置实体类
return new AutoConfigurationEntry(configurations, exclusions);
}
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
// SPI获取EnableAutoConfiguration为key的所有实现类
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
追踪源码最终可以看到也是从META-INF/spring.factories文件中拿到所有EnableAutoConfiguration对应的值(在spring-boot-autoconfigure中)并通过反射实例化,过滤后包装成AutoConfigurationEntry对象返回。
看到这里你应该会觉得自动配置的实现就是通过这个selectImports方法,但实际上这个方法通常并不会被调用到,而是会调用该类的内部类AutoConfigurationGroup的process和selectImports方法,前者同样是通过getAutoConfigurationEntry拿到所有的自动配置类,而后者这是过滤排序并包装后返回。
下面就来分析ConfigurationClassPostProcessor是怎么调用到这里的,直接进入processConfigBeanDefinitions方法:
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
String[] candidateNames = registry.getBeanDefinitionNames();
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
if (configCandidates.isEmpty()) {
return;
}
// Sort by previously determined @Order value, if applicable
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// Detect any custom bean name generation strategy supplied through the enclosing application context
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(
AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// Parse each @Configuration class
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
parser.parse(candidates);
parser.validate();
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
this.reader.loadBeanDefinitions(configClasses);
alreadyParsed.addAll(configClasses);
// 省略。。。。
}
前面一大段主要是拿到合格的Configuration配置类,主要逻辑是在ConfigurationClassParser.parse方法中,该方法完成了对@Component、@Bean、@Import、@ComponentScans等注解的解析,这里主要看对@Import的解析,其它的读者可自行分析。
一步步追踪,最终会进入到processConfigurationClass方法:
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
这里需要注意this.conditionEvaluator.shouldSkip方法的调用,这个方法就是进行Bean加载过滤的,即根据@Condition注解的匹配值判断是否加载该Bean,具体实现稍后分析,继续跟踪主流程doProcessConfigurationClass:
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
省略....
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), true);
省略....
return null;
}
这里就是完成对一系列注解的支撑,我省略掉了,主要看processImports方法,这个方法就是处理@Import注解的:
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, boolean checkForCircularImports) {
if (importCandidates.isEmpty()) {
return;
}
if (checkForCircularImports && isChainedImportOnStack(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
this.importStack.push(configClass);
try {
for (SourceClass candidate : importCandidates) {
if (candidate.isAssignable(ImportSelector.class)) {
// Candidate class is an ImportSelector -> delegate to it to determine imports
Class<?> candidateClass = candidate.loadClass();
ImportSelector selector = ParserStrategyUtils.instantiateClass(candidateClass, ImportSelector.class,
this.environment, this.resourceLoader, this.registry);
if (selector instanceof DeferredImportSelector) {
this.deferredImportSelectorHandler.handle(configClass, (DeferredImportSelector) selector);
}
else {
String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata());
Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames);
processImports(configClass, currentSourceClass, importSourceClasses, false);
}
}
else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {
Class<?> candidateClass = candidate.loadClass();
ImportBeanDefinitionRegistrar registrar =
ParserStrategyUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class,
this.environment, this.resourceLoader, this.registry);
configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());
}
else {
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
processConfigurationClass(candidate.asConfigClass(configClass));
}
}
}
}
}
刚刚我提醒过AutoConfigurationImportSelector是实现DeferredImportSelector接口的,如果不是该接口的实现类则是直接调用selectImports方法,反之则是调用DeferredImportSelectorHandler.handle方法:
private List<DeferredImportSelectorHolder> deferredImportSelectors = new ArrayList<>();
public void handle(ConfigurationClass configClass, DeferredImportSelector importSelector) {
DeferredImportSelectorHolder holder = new DeferredImportSelectorHolder(
configClass, importSelector);
if (this.deferredImportSelectors == null) {
DeferredImportSelectorGroupingHandler handler = new DeferredImportSelectorGroupingHandler();
handler.register(holder);
handler.processGroupImports();
}
else {
this.deferredImportSelectors.add(holder);
}
}
首先创建了一个DeferredImportSelectorHolder对象,如果是第一次执行则是添加到deferredImportSelectors属性中,等到ConfigurationClassParser.parse的最后调用process方法:
public void parse(Set<BeanDefinitionHolder> configCandidates) {
省略.....
this.deferredImportSelectorHandler.process();
}
public void process() {
List<DeferredImportSelectorHolder> deferredImports = this.deferredImportSelectors;
this.deferredImportSelectors = null;
try {
if (deferredImports != null) {
DeferredImportSelectorGroupingHandler handler = new DeferredImportSelectorGroupingHandler();
deferredImports.sort(DEFERRED_IMPORT_COMPARATOR);
deferredImports.forEach(handler::register);
handler.processGroupImports();
}
}
finally {
this.deferredImportSelectors = new ArrayList<>();
}
}
反之则是直接执行,首先通过register拿到AutoConfigurationGroup对象:
public void register(DeferredImportSelectorHolder deferredImport) {
Class<? extends Group> group = deferredImport.getImportSelector()
.getImportGroup();
DeferredImportSelectorGrouping grouping = this.groupings.computeIfAbsent(
(group != null ? group : deferredImport),
key -> new DeferredImportSelectorGrouping(createGroup(group)));
grouping.add(deferredImport);
this.configurationClasses.put(deferredImport.getConfigurationClass().getMetadata(),
deferredImport.getConfigurationClass());
}
public Class<? extends Group> getImportGroup() {
return AutoConfigurationGroup.class;
}
然后在processGroupImports方法中进行真正的处理:
public void processGroupImports() {
for (DeferredImportSelectorGrouping grouping : this.groupings.values()) {
grouping.getImports().forEach(entry -> {
ConfigurationClass configurationClass = this.configurationClasses.get(
entry.getMetadata());
try {
processImports(configurationClass, asSourceClass(configurationClass),
asSourceClasses(entry.getImportClassName()), false);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configurationClass.getMetadata().getClassName() + "]", ex);
}
});
}
}
public Iterable<Group.Entry> getImports() {
for (DeferredImportSelectorHolder deferredImport : this.deferredImports) {
this.group.process(deferredImport.getConfigurationClass().getMetadata(),
deferredImport.getImportSelector());
}
return this.group.selectImports();
}
在getImports方法中就完成了对process和selectImports方法的调用,拿到自动配置类后再递归调用调用processImports方法完成对自动配置类的加载。
至此,自动配置的加载过程就分析完了,下面是时序图:
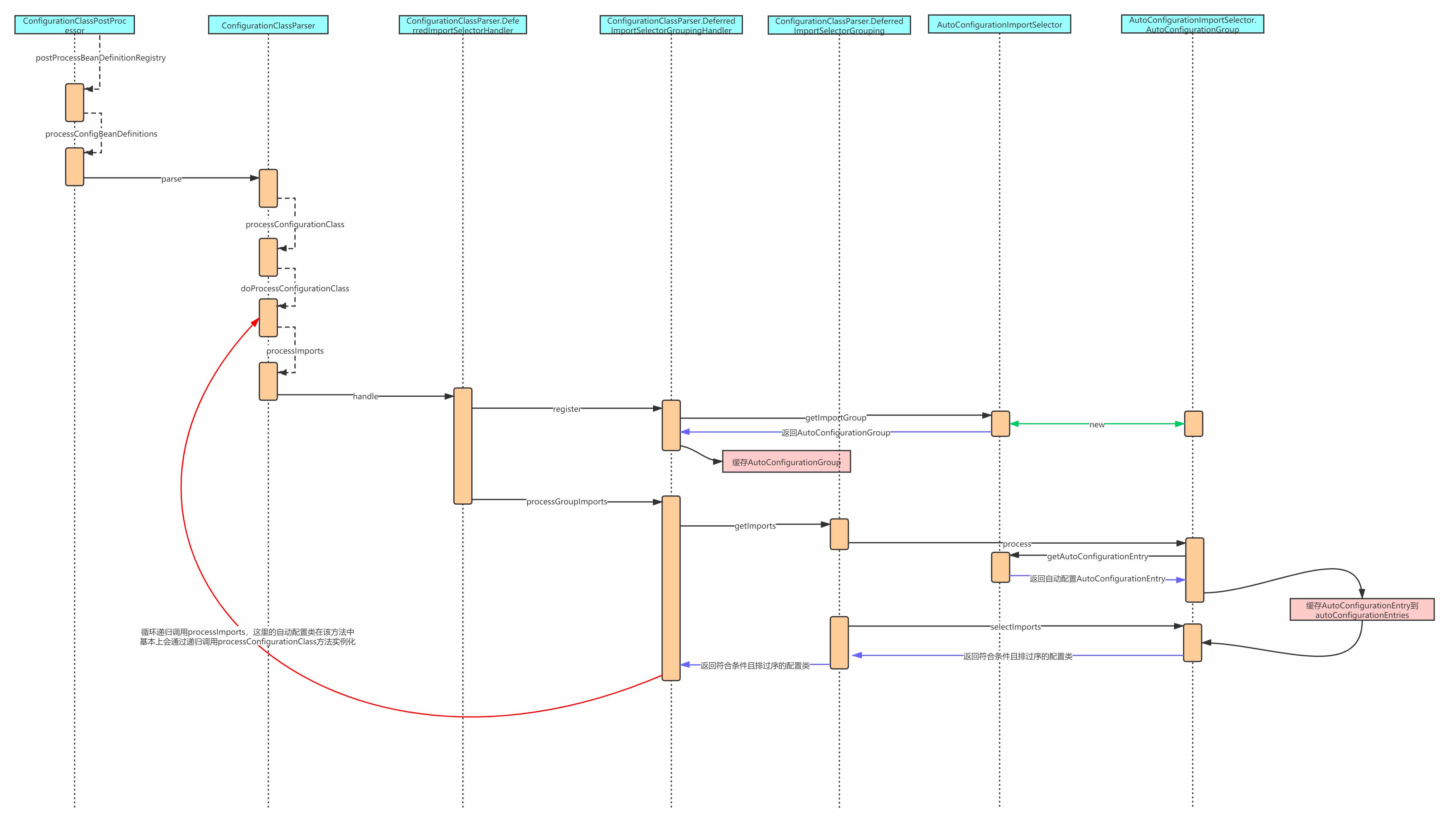
Condition注解原理
在自动配置类中有很多Condition相关的注解,以AOP为例:
Configuration(proxyBeanMethods = false)
@ConditionalOnProperty(prefix = "spring.aop", name = "auto", havingValue = "true", matchIfMissing = true)
public class AopAutoConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(Advice.class)
static class AspectJAutoProxyingConfiguration {
@Configuration(proxyBeanMethods = false)
@EnableAspectJAutoProxy(proxyTargetClass = false)
@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "false",
matchIfMissing = false)
static class JdkDynamicAutoProxyConfiguration {
}
@Configuration(proxyBeanMethods = false)
@EnableAspectJAutoProxy(proxyTargetClass = true)
@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true",
matchIfMissing = true)
static class CglibAutoProxyConfiguration {
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingClass("org.aspectj.weaver.Advice")
@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true",
matchIfMissing = true)
static class ClassProxyingConfiguration {
ClassProxyingConfiguration(BeanFactory beanFactory) {
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
AopConfigUtils.registerAutoProxyCreatorIfNecessary(registry);
AopConfigUtils.forceAutoProxyCreatorToUseClassProxying(registry);
}
}
}
}
这里就能看到@ConditionalOnProperty、@ConditionalOnClass、@ConditionalOnMissingClass,另外还有@ConditionalOnBean、@ConditionalOnMissingBean等等很多条件匹配注解。这些注解表示条件匹配才会加载该Bean,以@ConditionalOnProperty为例,表明配置文件中符合条件才会加载对应的Bean,prefix表示在配置文件中的前缀,name表示配置的名称,havingValue表示配置为该值时才匹配,matchIfMissing则是表示没有该配置是否默认加载对应的Bean。
其它注解可类比理解记忆,下面主要来分析该注解的实现原理。
这里注解点进去看会发现每个注解上都标注了@Conditional注解,并且value值都对应一个类,比如OnBeanCondition,而这些类都实现了Condition接口,看看其继承体系:
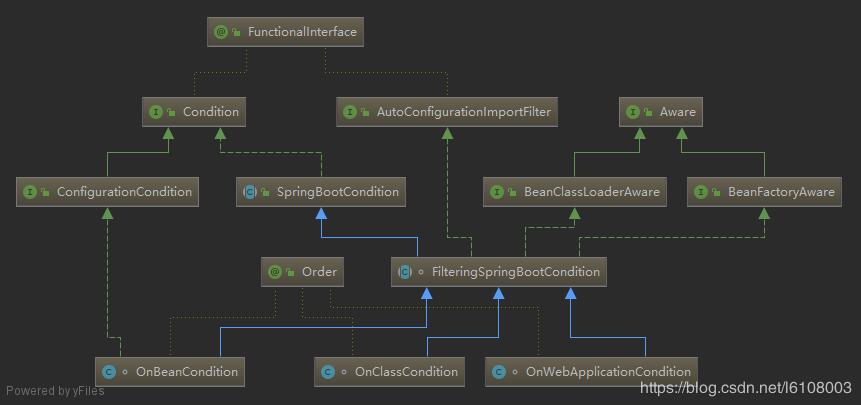
上面只展示了几个实现类,但实际上Condition的实现类是非常多的,我们还可以自己实现该接口来扩展@Condition注解。
Condition接口中有一个matches方法,这个方法返回true则表示匹配。该方法在ConfigurationClassParser中多处都有调用,也就是刚刚我提醒过的shouldSkip方法,具体实现是在ConditionEvaluator类中:
public boolean shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase) {
if (metadata == null || !metadata.isAnnotated(Conditional.class.getName())) {
return false;
}
if (phase == null) {
if (metadata instanceof AnnotationMetadata &&
ConfigurationClassUtils.isConfigurationCandidate((AnnotationMetadata) metadata)) {
return shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION);
}
return shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN);
}
List<Condition> conditions = new ArrayList<>();
for (String[] conditionClasses : getConditionClasses(metadata)) {
for (String conditionClass : conditionClasses) {
Condition condition = getCondition(conditionClass, this.context.getClassLoader());
conditions.add(condition);
}
}
AnnotationAwareOrderComparator.sort(conditions);
for (Condition condition : conditions) {
ConfigurationPhase requiredPhase = null;
if (condition instanceof ConfigurationCondition) {
requiredPhase = ((ConfigurationCondition) condition).getConfigurationPhase();
}
if ((requiredPhase == null || requiredPhase == phase) && !condition.matches(this.context, metadata)) {
return true;
}
}
return false;
}
再来看看matches的实现,但OnBeanCondition类中没有实现该方法,而是在其父类SpringBootCondition中:
public final boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
String classOrMethodName = getClassOrMethodName(metadata);
try {
ConditionOutcome outcome = getMatchOutcome(context, metadata);
logOutcome(classOrMethodName, outcome);
recordEvaluation(context, classOrMethodName, outcome);
return outcome.isMatch();
}getMatchOutcome方法也是一个模板方法,具体的匹配逻辑就在这个方法中实现,该方法返回的ConditionOutcome对象就包含了是否匹配和日志消息两个字段。进入到OnBeanCondition类中:
public ConditionOutcome getMatchOutcome(ConditionContext context, AnnotatedTypeMetadata metadata) {
ConditionMessage matchMessage = ConditionMessage.empty();
MergedAnnotations annotations = metadata.getAnnotations();
if (annotations.isPresent(ConditionalOnBean.class)) {
Spec<ConditionalOnBean> spec = new Spec<>(context, metadata, annotations, ConditionalOnBean.class);
MatchResult matchResult = getMatchingBeans(context, spec);
if (!matchResult.isAllMatched()) {
String reason = createOnBeanNoMatchReason(matchResult);
return ConditionOutcome.noMatch(spec.message().because(reason));
}
matchMessage = spec.message(matchMessage).found("bean", "beans").items(Style.QUOTE,
matchResult.getNamesOfAllMatches());
}
if (metadata.isAnnotated(ConditionalOnSingleCandidate.class.getName())) {
Spec<ConditionalOnSingleCandidate> spec = new SingleCandidateSpec(context, metadata, annotations);
MatchResult matchResult = getMatchingBeans(context, spec);
if (!matchResult.isAllMatched()) {
return ConditionOutcome.noMatch(spec.message().didNotFind("any beans").atAll());
}
else if (!hasSingleAutowireCandidate(context.getBeanFactory(), matchResult.getNamesOfAllMatches(),
spec.getStrategy() == SearchStrategy.ALL)) {
return ConditionOutcome.noMatch(spec.message().didNotFind("a primary bean from beans")
.items(Style.QUOTE, matchResult.getNamesOfAllMatches()));
}
matchMessage = spec.message(matchMessage).found("a primary bean from beans").items(Style.QUOTE,
matchResult.getNamesOfAllMatches());
}
if (metadata.isAnnotated(ConditionalOnMissingBean.class.getName())) {
Spec<ConditionalOnMissingBean> spec = new Spec<>(context, metadata, annotations,
ConditionalOnMissingBean.class);
MatchResult matchResult = getMatchingBeans(context, spec);
if (matchResult.isAnyMatched()) {
String reason = createOnMissingBeanNoMatchReason(matchResult);
return ConditionOutcome.noMatch(spec.message().because(reason));
}
matchMessage = spec.message(matchMessage).didNotFind("any beans").atAll();
}
return ConditionOutcome.match(matchMessage);
}可以看到该类支持了@ConditionalOnBean、@ConditionalOnSingleCandidate、@ConditionalOnMissingBean注解,主要的匹配逻辑在getMatchingBeans方法中:
protected final MatchResult getMatchingBeans(ConditionContext context, Spec<?> spec) {
ClassLoader classLoader = context.getClassLoader();
ConfigurableListableBeanFactory beanFactory = context.getBeanFactory();
boolean considerHierarchy = spec.getStrategy() != SearchStrategy.CURRENT;
Set<Class<?>> parameterizedContainers = spec.getParameterizedContainers();
if (spec.getStrategy() == SearchStrategy.ANCESTORS) {
BeanFactory parent = beanFactory.getParentBeanFactory();
Assert.isInstanceOf(ConfigurableListableBeanFactory.class, parent,
"Unable to use SearchStrategy.ANCESTORS");
beanFactory = (ConfigurableListableBeanFactory) parent;
}
MatchResult result = new MatchResult();
Set<String> beansIgnoredByType = getNamesOfBeansIgnoredByType(classLoader, beanFactory, considerHierarchy,
spec.getIgnoredTypes(), parameterizedContainers);
for (String type : spec.getTypes()) {
Collection<String> typeMatches = getBeanNamesForType(classLoader, considerHierarchy, beanFactory, type,
parameterizedContainers);
typeMatches.removeAll(beansIgnoredByType);
if (typeMatches.isEmpty()) {
result.recordUnmatchedType(type);
}
else {
result.recordMatchedType(type, typeMatches);
}
}
for (String annotation : spec.getAnnotations()) {
Set<String> annotationMatches = getBeanNamesForAnnotation(classLoader, beanFactory, annotation,
considerHierarchy);
annotationMatches.removeAll(beansIgnoredByType);
if (annotationMatches.isEmpty()) {
result.recordUnmatchedAnnotation(annotation);
}
else {
result.recordMatchedAnnotation(annotation, annotationMatches);
}
}
for (String beanName : spec.getNames()) {
if (!beansIgnoredByType.contains(beanName) && containsBean(beanFactory, beanName, considerHierarchy)) {
result.recordMatchedName(beanName);
}
else {
result.recordUnmatchedName(beanName);
}
}
return result;
}这里逻辑看起来比较复杂,但实际上就做了两件事,首先通过getNamesOfBeansIgnoredByType方法调用beanFactory.getBeanNamesForType拿到容器中对应的Bean实例,然后根据返回的结果判断哪些Bean存在,哪些Bean不存在(Condition注解中是可以配置多个值的)并返回MatchResult对象,而MatchResult中只要有一个Bean没有匹配上就返回false,也就决定了当前Bean是否需要实例化。
总结
本篇分析了SpringBoot核心原理的实现,通过本篇相信读者也将能更加熟练地使用和扩展SpringBoot。另外还有一些常用的组件我没有展开分析,如事务、MVC、监听器的自动配置,这些我们有了Spring源码基础的话下来看一下就明白了,这里就不赘述了。最后读者可以思考一下我们应该如何自定义starter启动器,相信看完本篇应该难不倒你。
以上这篇基于SpringBoot核心原理(自动配置、事件驱动、Condition)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持亿速云。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



