访问路径是指Oracle找到用户需要的数据的方法,这些方法很少,包括:
声名狼藉的全表扫描--人们不惜一切视图避免的(曲解的)访问路径。
各种类型的索引扫描--这是人们感觉良好的访问路径(多数情况下是被曲解的)。
通过hash或者rowid的方式直接访问,通常对于单数据行来说,是最快的。
并没有一种访问路径是最好的,如果有,那么Oracle只需提供这一种访问路径就好了。
全表扫描
全扫描就是顺序的读取表中的所有数据块。采用多块读的方式,从头开始扫描表中的块,直到高水位线。全扫描是处理大数据量行之有效的方法。需要牢记:全扫描并不邪恶,多数情况下全扫描是获得结果的最快方法。
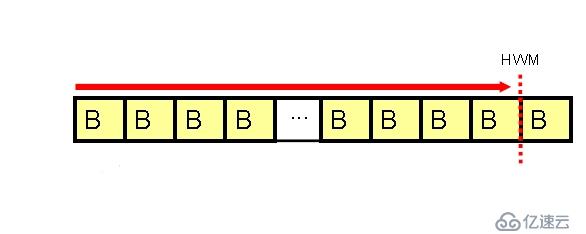
全扫描每次读取的块数由参数db_file_multiblock_read_count指定
SQL> show parameter db_file_mu NAME TYPE VALUE ------------------------------------ --------------------------------- ------------------------------ db_file_multiblock_read_count integer 128
2.rowid 访问
rowid是一行数据的物理位置,访问单行数据的速度是最快的。
SQL> select * from emp where rowid ='AAASZHAAEAAAACXAAN'; 7934 MILLER CLERK 7782 1982/01/23 00:00:00 1300 10
通过索引的方式访问数据,其实也是通过索引,先找到这行数据的rowid,然后再通过rowid访问数据。
SQL> set autotrace on traceonly SQL> select * from emp where empno=7934; Execution Plan ---------------------------------------------------------- Plan hash value: 2949544139 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 | --------------------------------------------------------------------------------------
rowid还可以进行范围扫描。
SQL> select * from emp where rowid between 'AAASZHAAEAAAACXAAA' and 'AAASZHAAEAAAACXAAN'; 7369 SMITH CLERK 7902 1980/12/17 00:00:00 800 20 7499 ALLEN SALESMAN 7698 1981/02/20 00:00:00 1600 300 30 7521 WARD SALESMAN 7698 1981/02/22 00:00:00 1250 500 30 7566 JONES MANAGER 7839 1981/04/02 00:00:00 2975 20 7654 MARTIN SALESMAN 7698 1981/09/28 00:00:00 1250 1400 30 7698 BLAKE MANAGER 7839 1981/05/01 00:00:00 2850 30 7782 CLARK MANAGER 7839 1981/06/09 00:00:00 2450 10 7788 SCOTT ANALYST 7566 1987/04/19 00:00:00 3000 20 7839 KING PRESIDENT 1981/11/17 00:00:00 5000 10 7844 TURNER SALESMAN 7698 1981/09/08 00:00:00 1500 0 30 7876 ADAMS CLERK 7788 1987/05/23 00:00:00 1100 20 7900 JAMES CLERK 7698 1981/12/03 00:00:00 950 30 7902 FORD ANALYST 7566 1981/12/03 00:00:00 3000 20 7934 MILLER CLERK 7782 1982/01/23 00:00:00 1300 10 14 rows selected.
3. 索引扫描
索引扫描是最常见的数据访问之一,例如
SQL> set autotrace on traceonly SQL> select * from emp where empno=7934; Execution Plan ---------------------------------------------------------- Plan hash value: 2949544139 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 | --------------------------------------------------------------------------------------
我们下面主要以b-tree索引为例
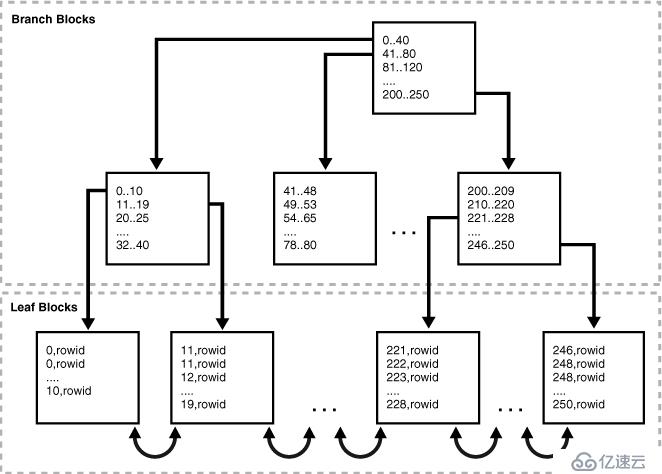
索引唯一性扫描
优化器知道索引列的值是唯一的,查询结果只返回一行。这种索引的访问速度最快,找到一行数据就不再继续扫描索引,直接返回。
SQL> select * from emp where empno=7934; 7934 MILLER CLERK 7782 1982/01/23 00:00:00 1300 10 Execution Plan ---------------------------------------------------------- Plan hash value: 2949544139 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 | --------------------------------------------------------------------------------------
实际上Oracle中并没有非唯一索引,在非唯一索引中,Oracle将数据的rowid添加到索引键中使其唯一。
索引范围扫描
SQL> set autot traceonly SQL> select empno from emp where empno<5000; no rows selected Execution Plan ---------------------------------------------------------- Plan hash value: 1567865628 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 4 | 1 (0)| 00:00:01 | |* 1 | INDEX RANGE SCAN| PK_EMP | 1 | 4 | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------
有取的是,索引可以按照两个方向去扫描索引
SQL> select empno from emp where empno<5000 order by empno;
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 1567865628
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| PK_EMP | 1 | 4 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("EMPNO"<5000)
SQL> select empno from emp where empno<5000 order by empno desc;
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 2474278666
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN DESCENDING| PK_EMP | 1 | 4 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------这个的好处是避免排序操作
如果你建立的是非唯一索引,即便你使用=查询,也是范围扫描
SQL> create index ind_emp_ename on emp(ename);
Index created.
SQL> select * from emp where ename='KING';
Execution Plan
----------------------------------------------------------
Plan hash value: 2929622481
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IND_EMP_ENAME | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ENAME"='KING')索引全扫描
SQL> select empno from emp; 14 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 179099197 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 14 | 56 | 1 (0)| 00:00:01 | | 1 | INDEX FULL SCAN | PK_EMP | 14 | 56 | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------
索引全扫描,并不是扫描全部的索引。它实际上只需扫描索引的叶子节点。但是为了找到叶子节点的位置,也会扫描部分的分支节点。
我们看如下查询
SQL> select empno,ename from emp; 14 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 3956160932 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 14 | 140 | 3 (0)| 00:00:01 | | 1 | TABLE ACCESS FULL| EMP | 14 | 140 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------
查询列ename并不在索引中,所以走的是全表扫描。但是如果我们将语句做如下修改。
SQL> select empno,ename from emp order by empno; 14 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 4170700152 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 14 | 140 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 14 | 140 | 2 (0)| 00:00:01 | | 2 | INDEX FULL SCAN | PK_EMP | 14 | | 1 (0)| 00:00:01 | --------------------------------------------------------------------------------------
Oracle为了避免排序操作,而使用了索引全扫描。因为索引是有序的数据,并且索引全扫描是按顺序的单块读操作。
max和min
SQL> select max(empno) from emp; Execution Plan ---------------------------------------------------------- Plan hash value: 1707959928 ------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 4 | 1 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 4 | | | | 2 | INDEX FULL SCAN (MIN/MAX)| PK_EMP | 1 | 4 | 1 (0)| 00:00:01 |
该扫描使用了索引全扫描,但其实并非真正的全扫描,max和min限定词使得Oracle知道何时停止,它只是扫描最高块或者最低块。
索引跳跃扫描
通常要使用索引,索引的前置列一定要出现在查询条件中。
SQL> create table t(a int,b int ,c int,d int,e int,f int,g int); SQL> create index t_idx on t(a,b,c);
通常情况下只有如下的查询才会使用索引
select * from t where a =:a; select * from t where a =:a and b =:b; select * from t where a =:a and b =:b and c =:c;
但是如下查询不会使用索引(除了使用hint强制索引全扫描)
select * from t where b =:b; select * from t where c =:c; select * from t where b =:b and c =:c;
Oracle 9i后实现了跳跃索引扫描,条件如下:
谓词中使用了索引中其他的列。
前置列值的DISTINCT_NUM比较少。
我们看看如下示例
SQL> create table t as
2 select mod(rownum,3) a,rownum b,rownum c,object_name d
3 from all_objects;
Table created.
SQL> create index t_idx on t(a,b,c);
Index created.
SQL> analyze table t compute statistics;
Table analyzed.
SQL> select * from t where b=1 and c=1;
Execution Plan
----------------------------------------------------------
Plan hash value: 2053318169
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 34 | 5 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 34 | 5 (0)| 00:00:01 |
|* 2 | INDEX SKIP SCAN | T_IDX | 1 | | 4 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("B"=1 AND "C"=1)
filter("B"=1 AND "C"=1)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
8 consistent gets
0 physical reads
0 redo size
724 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed因为a的值比较少,只有3个,Oracle把索引(a,b,c) 看成3个小索引 。
索引快速全扫描
索引快速全扫描与索引全扫描明显的不同,它有如下特征
它读取索引中的每个块,包括所有分支块。
它采用多块读,像全表扫描一样。
它不按排序顺序扫描索引。
我们先建立一个表,并插入大量数据。
SQL> create table big_table as select * from dba_objects; Table created. SQL> insert into big_table select * from big_table; 74577 rows created. SQL> insert into big_table select * from big_table; 223731 rows created. SQL> / 447462 rows created. SQL> commit; Commit complete. SQL> alter table big_table modify object_id not null; Table altered. SQL> create index idx_big_table_objid on big_table(object_id); Index created. SQL> analyze table big_table compute statistics; Table analyzed.
执行如下查询
SQL> set autot traceonly SQL> select object_id from big_table; 894924 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 205523069 -------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 894K| 3495K| 544 (2)| 00:00:07 | | 1 | INDEX FAST FULL SCAN| IDX_BIG_TABLE_OBJID | 894K| 3495K| 544 (2)| 00:00:07 | -------------------------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 15 recursive calls 0 db block gets 61534 consistent gets 2 physical reads 0 redo size 15755358 bytes sent via SQL*Net to client 656794 bytes received via SQL*Net from client 59663 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 894924 rows processed
查询使用的是索引快速全扫描。
有心的人可以思考一下,如下查询为啥没有使用索引快速全扫描,而使用了索引全扫描。
SQL> select empno from emp; 14 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 179099197 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 14 | 56 | 1 (0)| 00:00:01 | | 1 | INDEX FULL SCAN | PK_EMP | 14 | 56 | 1 (0)| 00:00:01 | --------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 686 bytes sent via SQL*Net to client 523 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 14 rows processed
索引连接
索引连接(index join)是在表中存在多个索引时针对某个查询所选中的索引路径。
我们看如下例子
SQL> create table t1 as select * from dba_objects;
Table created.
SQL> create index t1_idx1 on t1(object_id);
Index created.
SQL> create index t1_idx2 on t1(owner,object_type);
Index created.
SQL> analyze table t1 compute statistics;
Table analyzed.
SQL> set autot traceonly
SQL> select object_id,owner,object_type from t1
2 where object_id between 100 and 2000
3 and owner='SYS';
1478 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2563395799
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 69 | 1173 | 18 (6)| 00:00:01 |
|* 1 | VIEW | index$_join$_001 | 69 | 1173 | 18 (6)| 00:00:01 |
|* 2 | HASH JOIN | | | | | |
|* 3 | INDEX RANGE SCAN| T1_IDX1 | 69 | 1173 | 7 (15)| 00:00:01 |
|* 4 | INDEX RANGE SCAN| T1_IDX2 | 69 | 1173 | 12 (9)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_ID"<=2000 AND "OWNER"='SYS' AND "OBJECT_ID">=100)
2 - access(ROWID=ROWID)
3 - access("OBJECT_ID">=100 AND "OBJECT_ID"<=2000)
4 - access("OWNER"='SYS')
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
215 consistent gets
0 physical reads
0 redo size
32014 bytes sent via SQL*Net to client
1601 bytes received via SQL*Net from client
100 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1478 rows processed优化器通过扫描T1_IDX1,T1_IDX2得到结果集,用两个结果集的rowid进行join运算,得到返回集。
这样避免扫描表。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





