本篇文章给大家分享的是有关利用Python爬虫怎么爬取喜马拉雅app上的音频数据,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
环境:
1.确定数据所在的链接地址(url)
2.通过代码发送url地址的请求
3.解析数据(要的, 筛选不要的)
4.数据持久化(保存)
案例思路:
1. 在静态数据中获取音频的id值
2. 发送指定id值json数据请求(src)
3. 从json数据中解析音频所对应的URL地址 开始写代码
先导入所需的模块
import requests import parsel # 数据解析模块 import re
1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
打开开发者工具,播放一个音频,在Madie里面可以找到一个数据包
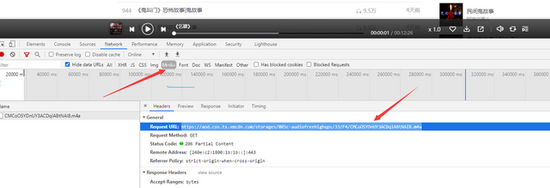
复制URL,搜索
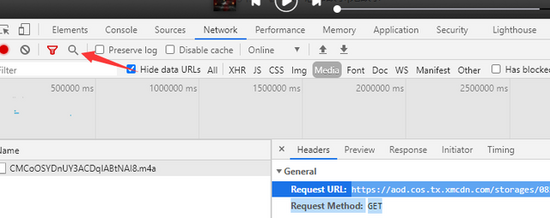
找到ID值
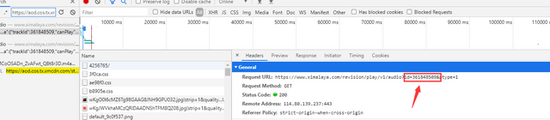
继续搜索,找到请求头参数
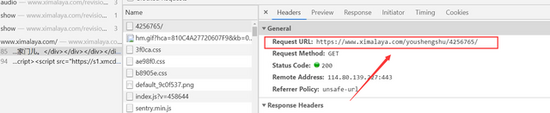
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers) html_data = response.text
3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revision/play/v1/audio?id={}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)最后还要处理文件名非法字符
def change_title(title): pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |' new_title = re.sub(pattern, "_", title) # 替换为下划线 return new_title
完整代码
import re
import requests
import parsel # 数据解析模块
def change_title(title):
"""处理文件名非法字符的方法"""
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
for page in range(13, 33):
print('---------------正在爬取第{}页的数据----------------'.format(page))
# 1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
# 2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data)
# 3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li')
for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href)
m4a_id = href.split('/')[-1]
# print(href, m4a_id)
# 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revision/play/v1/audio?id={}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data)
# 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url)
# 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content
new_title = change_title(title)
# print(new_title)
# 4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
except:
pass以上就是利用Python爬虫怎么爬取喜马拉雅app上的音频数据,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





