本篇文章给大家分享的是有关怎么在mysql中利用覆盖索引避免回表优化查询,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
| id | name |
| 1 | aa |
| 3 | kl |
| 5 | op |
| 8 | aa |
| 10 | kk |
| 11 | kl |
| 14 | jk |
| 16 | ml |
| 17 | mn |
| 18 | kl |
| 19 | kl |
| 22 | hj |
| 24 | io |
| 25 | vg |
| 29 | jk |
| 31 | jk |
| 33 | rt |
| 34 | ty |
| 35 | yu |
| 37 | rt |
| 39 | rt |
| 41 | ty |
| 45 | qt |
| 47 | ty |
| 53 | qi |
| 57 | gh |
| 61 | dh |
以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚集索引。
非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
B+树和B树是mysql索引的常用数据结构,B+树是B树的进一步优化,将上面的表转成图分析一下:
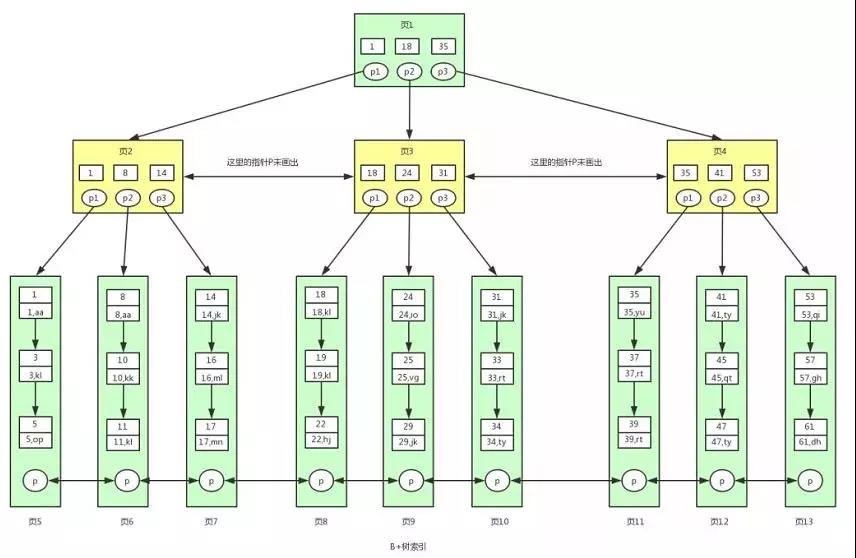
B+树的特点:
1.B+ 树非叶子节点上是不存储数据的,仅存储键值
2.叶子节点的数据是按照顺序排列的
3. B+ 树中各个页之间是通过双向链表连接
B+ 树索引按照存储方式的不同分为聚集索引和非聚集索引。
聚簇索引:
以 InnoDB 作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。
这是因为 InnoDB 是把数据存放在 B+ 树中的,而 B+ 树的键值就是主键,在 B+ 树的叶子节点中,存储了表中所有的数据。
这种以主键作为 B+ 树索引的键值而构建的 B+ 树索引,我们称之为聚集索引。
非聚簇索引:
以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚集索引。
非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
为什么明明用了非主键索引还会回表,简单说就是非主键索引是非聚簇索引,在B+树叶子节点中只保存主键和该非主键索引,一次查询只能查到这两个字段,如果想查三个字段,就必须再查一次聚簇索引,这就是回表。
举个例子,表中新增一个字段age,我们用name建一个索引(非聚簇索引)
| id | name | age |
| 10 | zs | 23 |
| 7 | ls | 54 |
| 13 | ww | 12 |
| 5 | zl | 76 |
| 8 | xw | 23 |
| 12 | xm | 43 |
| 17 | dy | 21 |
select id,name from user where name = 'zs';能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
select id,name,age from user where name = 'zs';能够命中name索引,索引叶子节点存储了主键id,但age字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取age字段,效率会降低。
以上就是怎么在mysql中利用覆盖索引避免回表优化查询,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



