Python3зҪ‘з»ңзҲ¬иҷ«е®һжҲҳ-10гҖҒзҲ¬иҷ«жЎҶжһ¶зҡ„е®үиЈ…пјҡPySpiderгҖҒScrapy
жҲ‘们зӣҙжҺҘз”Ё RequestsгҖҒSelenium зӯүеә“еҶҷзҲ¬иҷ«пјҢеҰӮжһңзҲ¬еҸ–йҮҸдёҚжҳҜеӨӘеӨ§пјҢйҖҹеәҰиҰҒжұӮдёҚй«ҳпјҢжҳҜе®Ңе…ЁеҸҜд»Ҙж»Ўи¶ійңҖжұӮзҡ„гҖӮдҪҶжҳҜеҶҷеӨҡдәҶдјҡеҸ‘зҺ°е…¶еҶ…йғЁи®ёеӨҡд»Јз Ғе’Ң组件жҳҜеҸҜд»ҘеӨҚз”Ёзҡ„пјҢеҰӮжһңжҲ‘们жҠҠиҝҷдәӣ组件жҠҪзҰ»еҮәжқҘпјҢе°Ҷеҗ„дёӘеҠҹиғҪжЁЎеқ—еҢ–пјҢе°ұж…ўж…ўдјҡеҪўжҲҗдёҖдёӘжЎҶжһ¶йӣҸеҪўпјҢд№…иҖҢд№…д№ӢпјҢзҲ¬иҷ«жЎҶжһ¶е°ұиҜһз”ҹдәҶгҖӮ
еҲ©з”ЁжЎҶжһ¶жҲ‘们еҸҜд»ҘдёҚз”ЁеҶҚеҺ»е…іеҝғжҹҗдәӣеҠҹиғҪзҡ„е…·дҪ“е®һзҺ°пјҢеҸӘйңҖиҰҒеҺ»е…іеҝғзҲ¬еҸ–йҖ»иҫ‘еҚіеҸҜгҖӮжңүдәҶе®ғ们пјҢеҸҜд»ҘеӨ§еӨ§з®ҖеҢ–д»Јз ҒйҮҸпјҢиҖҢдё”жһ¶жһ„д№ҹдјҡеҸҳеҫ—жё…жҷ°пјҢзҲ¬еҸ–ж•ҲзҺҮд№ҹдјҡй«ҳи®ёеӨҡгҖӮжүҖд»ҘеҰӮжһңеҜ№зҲ¬иҷ«жңүдёҖе®ҡеҹәзЎҖпјҢдёҠжүӢжЎҶжһ¶жҳҜдёҖз§ҚеҘҪзҡ„йҖүжӢ©гҖӮ
жң¬д№Ұдё»иҰҒд»Ӣз»Қзҡ„зҲ¬иҷ«жЎҶжһ¶жңүPySpiderе’ҢScrapyпјҢжң¬иҠӮжҲ‘们жқҘд»Ӣз»ҚдёҖдёӢ PySpiderгҖҒScrapy д»ҘеҸҠе®ғ们зҡ„дёҖдәӣжү©еұ•еә“зҡ„е®үиЈ…ж–№ејҸгҖӮ
PySpiderзҡ„е®үиЈ…
PySpider жҳҜеӣҪдәә binux зј–еҶҷзҡ„ејәеӨ§зҡ„зҪ‘з»ңзҲ¬иҷ«жЎҶжһ¶пјҢе®ғеёҰжңүејәеӨ§зҡ„ WebUIгҖҒи„ҡжң¬зј–иҫ‘еҷЁгҖҒд»»еҠЎзӣ‘жҺ§еҷЁгҖҒйЎ№зӣ®з®ЎзҗҶеҷЁд»ҘеҸҠз»“жһңеӨ„зҗҶеҷЁпјҢеҗҢж—¶е®ғж”ҜжҢҒеӨҡз§Қж•°жҚ®еә“еҗҺз«ҜгҖҒеӨҡз§Қж¶ҲжҒҜйҳҹеҲ—пјҢеҸҰеӨ–е®ғиҝҳж”ҜжҢҒ JavaScript жёІжҹ“йЎөйқўзҡ„зҲ¬еҸ–пјҢдҪҝз”Ёиө·жқҘйқһеёёж–№дҫҝпјҢжң¬иҠӮд»Ӣз»ҚдёҖдёӢе®ғзҡ„е®үиЈ…иҝҮзЁӢгҖӮ
1. зӣёе…ій“ҫжҺҘ
- е®ҳж–№ж–ҮжЎЈпјҡhttp://docs.pyspider.org/
- PyPiпјҡhttps://pypi.python.org/pypi/...
- GitHubпјҡhttps://github.com/binux/pysp...
- е®ҳж–№ж•ҷзЁӢпјҡhttp://docs.pyspider.org/en/l...
- еңЁзәҝе®һдҫӢпјҡhttp://demo.pyspider.org
2. еҮҶеӨҮе·ҘдҪң
PySpider жҳҜж”ҜжҢҒ JavaScript жёІжҹ“зҡ„пјҢиҖҢиҝҷдёӘиҝҮзЁӢжҳҜдҫқиө–дәҺ PhantomJS зҡ„пјҢжүҖд»ҘиҝҳйңҖиҰҒе®үиЈ… PhantomJSпјҢжүҖд»ҘеңЁе®үиЈ…д№ӢеүҚиҜ·е®үиЈ…еҘҪ PhantomJSпјҢе®үиЈ…ж–№ејҸеңЁеүҚж–Үжңүд»Ӣз»ҚгҖӮ
3. Pipе®үиЈ…
жҺЁиҚҗдҪҝз”Ё Pip е®үиЈ…пјҢе‘Ҫд»ӨеҰӮдёӢпјҡ
pip3 install pyspider
Pythonиө„жәҗеҲҶдә«qun 784758214 ,еҶ…жңүе®үиЈ…еҢ…пјҢPDFпјҢеӯҰд№ и§Ҷйў‘пјҢиҝҷйҮҢжҳҜPythonеӯҰд№ иҖ…зҡ„иҒҡйӣҶең°пјҢйӣ¶еҹәзЎҖпјҢиҝӣйҳ¶пјҢйғҪж¬ўиҝҺ
е‘Ҫд»Өжү§иЎҢе®ҢжҜ•еҚіеҸҜе®ҢжҲҗе®үиЈ…гҖӮ
4. еёёи§Ғй”ҷиҜҜ
Windows дёӢеҸҜиғҪдјҡеҮәзҺ°иҝҷж ·зҡ„й”ҷиҜҜжҸҗзӨәпјҡCommand "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-vXo1W3/pycurl
иҝҷдёӘжҳҜ PyCurl е®үиЈ…й”ҷиҜҜпјҢдёҖиҲ¬дјҡеҮәзҺ°еңЁ Windows дёӢпјҢйңҖиҰҒе®үиЈ… PyCurl еә“пјҢдёӢиҪҪй“ҫжҺҘдёәпјҡhttp://www.lfd.uci.edu/~gohlk...пјҢжүҫеҲ°еҜ№еә” Python зүҲжң¬з„¶еҗҺдёӢиҪҪзӣёеә”зҡ„ Wheel ж–Ү件гҖӮ
еҰӮ Windows 64 дҪҚпјҢPython3.6 еҲҷдёӢиҪҪ pycurlвҖ‘7.43.0вҖ‘cp36вҖ‘cp36mвҖ‘win_amd64.whlпјҢйҡҸеҗҺз”Ё Pip е®үиЈ…еҚіеҸҜпјҢе‘Ҫд»ӨеҰӮдёӢпјҡ
pip3 install pycurlвҖ‘7.43.0вҖ‘cp36вҖ‘cp36mвҖ‘win_amd64.whl
Linux дёӢеҰӮжһңйҒҮеҲ° PyCurl зҡ„й”ҷиҜҜеҸҜд»ҘеҸӮиҖғжң¬ж–Үпјҡhttps://imlonghao.com/19.html
MacйҒҮеҲ°иҝҷз§Қжғ…еҶө,жү§иЎҢдёӢйқўж“ҚдҪңпјҡ
brew install openssl
openssl version
жҹҘзңӢзүҲжң¬
find /usr/local -name ssl.h
еҸҜд»ҘзңӢеҲ°еҪўеҰӮпјҡ
usr/local/Cellar/openssl/1.0.2s/include/openssl/ssl.h
ж·»еҠ зҺҜеўғеҸҳйҮҸ
export PYCURL_SSL_LIBRARY=openssl
export LDFLAGS=-L/usr/local/Cellar/openssl/1.0.2s/lib
export CPPFLAGS=-I/usr/local/Cellar/openssl/1.0.2s/include
pip3 install pyspider
5. йӘҢиҜҒе®үиЈ…
е®үиЈ…е®ҢжҲҗд№ӢеҗҺпјҢеҸҜд»ҘзӣҙжҺҘеңЁе‘Ҫд»ӨиЎҢдёӢеҗҜеҠЁ PySpiderпјҡ
pyspider all
еӣҫ 1-75 жҺ§еҲ¶еҸ°
иҝҷж—¶ PySpider зҡ„ Web жңҚеҠЎе°ұдјҡеңЁжң¬ең° 5000 з«ҜеҸЈиҝҗиЎҢпјҢзӣҙжҺҘеңЁжөҸи§ҲеҷЁжү“ејҖпјҡhttp://localhost:5000/ еҚіеҸҜиҝӣе…Ҙ PySpider зҡ„ WebUI з®ЎзҗҶйЎөйқўпјҢеҰӮеӣҫ 1-76 жүҖзӨәпјҡ
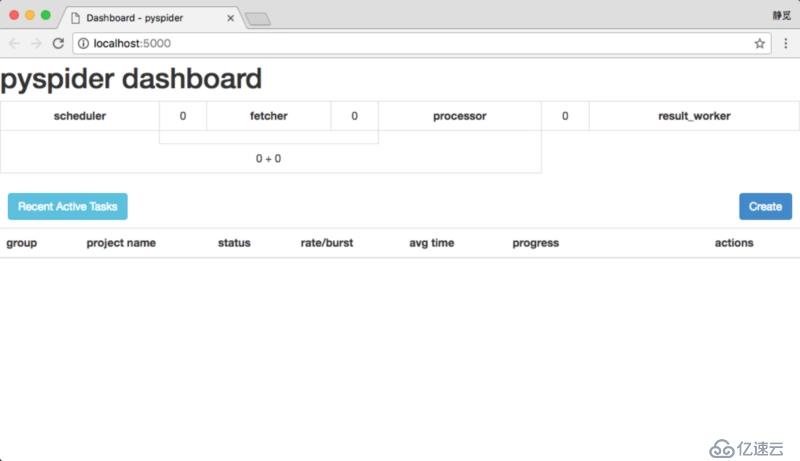
еӣҫ 1-76 з®ЎзҗҶйЎөйқў
еҰӮжһңеҮәзҺ°зұ»дјјйЎөйқўйӮЈиҜҒжҳҺ PySpider е·Із»Ҹе®үиЈ…жҲҗеҠҹдәҶгҖӮ
еңЁеҗҺж–Үдјҡд»Ӣз»Қ PySpider зҡ„иҜҰз»Ҷз”Ёжі•гҖӮ
иҝҷйҮҢжңүдёҖдёӘж·ұеқ‘пјҢPySpiderеңЁPython3.7дёҠиҝҗиЎҢж—¶дјҡжҠҘй”ҷ
File "/usr/local/lib/python3.7/site-packages/pyspider/run.py", line 231
async=True, get_object=False, no_input=False):
^
SyntaxError: invalid syntax
еҺҹеӣ жҳҜpython3.7дёӯasyncе·Із»ҸеҸҳжҲҗдәҶе…ій”®еӯ—гҖӮеӣ жӯӨеҮәзҺ°иҝҷдёӘй”ҷиҜҜгҖӮ
дҝ®ж”№ж–№ејҸжҳҜжүӢеҠЁжӣҝжҚўдёҖдёӢ
дёӢйқўдҪҚзҪ®зҡ„asyncж”№дёәmark_async
/usr/local/lib/python3.7/site-packages/pyspider/run.py зҡ„231иЎҢгҖҒ245иЎҢпјҲдёӨдёӘпјүгҖҒ365иЎҢ
/usr/local/lib/python3.7/site-packages/pyspider/webui/app.py зҡ„95иЎҢ
/usr/local/lib/python3.7/site-packages/pyspider/fetcher/tornado_fetcher.py зҡ„81иЎҢгҖҒ89иЎҢпјҲдёӨдёӘпјүгҖҒ95иЎҢгҖҒ117иЎҢ
Scrapyзҡ„е®үиЈ…
Scrapy жҳҜдёҖдёӘеҚҒеҲҶејәеӨ§зҡ„зҲ¬иҷ«жЎҶжһ¶пјҢдҫқиө–зҡ„еә“жҜ”иҫғеӨҡпјҢиҮіе°‘йңҖиҰҒдҫқиө–еә“жңү Twisted 14.0пјҢlxml 3.4пјҢpyOpenSSL 0.14гҖӮиҖҢеңЁдёҚеҗҢе№іеҸ°зҺҜеўғеҸҲеҗ„дёҚзӣёеҗҢпјҢжүҖд»ҘеңЁе®үиЈ…д№ӢеүҚжңҖеҘҪзЎ®дҝқжҠҠдёҖдәӣеҹәжң¬еә“е®үиЈ…еҘҪгҖӮжң¬иҠӮд»Ӣз»ҚдёҖдёӢ Scrapy еңЁдёҚеҗҢе№іеҸ°зҡ„е®үиЈ…ж–№жі•гҖӮ
1. зӣёе…ій“ҫжҺҘ
- е®ҳж–№зҪ‘з«ҷпјҡhttps://scrapy.org
- е®ҳж–№ж–ҮжЎЈпјҡhttps://docs.scrapy.org
- PyPiпјҡhttps://pypi.python.org/pypi/...
- GitHubпјҡhttps://github.com/scrapy/scrapy
- дёӯж–Үж–ҮжЎЈпјҡhttp://scrapy-chs.readthedocs.io
3. MacдёӢзҡ„е®үиЈ…
еңЁ Mac дёҠжһ„е»ә Scrapy зҡ„дҫқиө–еә“йңҖиҰҒ C зј–иҜ‘еҷЁд»ҘеҸҠејҖеҸ‘еӨҙж–Ү件пјҢе®ғдёҖиҲ¬з”ұ Xcode жҸҗдҫӣпјҢиҝҗиЎҢеҰӮдёӢе‘Ҫд»Өе®үиЈ…еҚіеҸҜпјҡ
xcode-select --install
йҡҸеҗҺеҲ©з”Ё Pip е®үиЈ… Scrapy еҚіеҸҜпјҢиҝҗиЎҢеҰӮдёӢе‘Ҫд»Өпјҡ
pip3 install Scrapy
иҝҗиЎҢе®ҢжҜ•д№ӢеҗҺеҚіеҸҜе®ҢжҲҗ Scrapy зҡ„е®үиЈ…гҖӮ
4. йӘҢиҜҒе®үиЈ…
е®үиЈ…д№ӢеҗҺпјҢеңЁе‘Ҫд»ӨиЎҢдёӢиҫ“е…Ҙ scrapyпјҢеҰӮжһңеҮәзҺ°зұ»дјјдёӢж–№зҡ„з»“жһңпјҢе°ұиҜҒжҳҺ Scrapy е®үиЈ…жҲҗеҠҹпјҢеҰӮеӣҫ 1-80 жүҖзӨәпјҡ
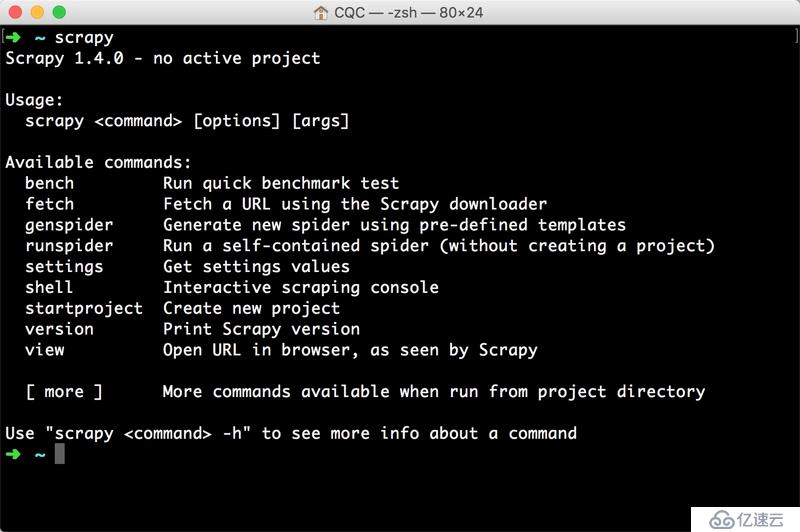
еӣҫ 1-80 йӘҢиҜҒе®үиЈ…
5. еёёи§Ғй”ҷиҜҜ
pkg_resources.VersionConflict: (six 1.5.2 (/usr/lib/python3/dist-packages), Requirement.parse('six>=1.6.0'))
six еҢ…зүҲжң¬иҝҮдҪҺпјҢsixеҢ…жҳҜдёҖдёӘжҸҗдҫӣе…је®№ Python2 е’Ң Python3 зҡ„еә“пјҢеҚҮзә§ six еҢ…еҚіеҸҜпјҡ
sudo pip3 install -U six
c/_cffi_backend.c:15:17: fatal error: ffi.h: No such file or directory
иҝҷжҳҜеңЁ Linux дёӢеёёеҮәзҺ°зҡ„й”ҷиҜҜпјҢзјәе°‘ Libffi иҝҷдёӘеә“гҖӮд»Җд№ҲжҳҜ libffiпјҹвҖңFFIвҖқ зҡ„е…ЁеҗҚжҳҜ Foreign Function InterfaceпјҢйҖҡеёёжҢҮзҡ„жҳҜе…Ғи®ёд»ҘдёҖз§ҚиҜӯиЁҖзј–еҶҷзҡ„д»Јз Ғи°ғз”ЁеҸҰдёҖз§ҚиҜӯиЁҖзҡ„д»Јз ҒгҖӮиҖҢ Libffi еә“еҸӘжҸҗдҫӣдәҶжңҖеә•еұӮзҡ„гҖҒдёҺжһ¶жһ„зӣёе…ізҡ„гҖҒе®Ңж•ҙзҡ„вҖқFFIвҖқгҖӮ
е®үиЈ…зӣёеә”зҡ„еә“еҚіеҸҜгҖӮ
UbuntuгҖҒDebianпјҡ
sudo apt-get install build-essential libssl-dev libffi-dev python3-dev
CentOSгҖҒRedHat:
sudo yum install gcc libffi-devel python-devel openssl-devel
Command "python setup.py egg_info" failed with error code 1 in/tmp/pip-build/cryptography/
иҝҷжҳҜзјәе°‘еҠ еҜҶзҡ„зӣёе…із»„件пјҢеҲ©з”ЁPip е®үиЈ…еҚіеҸҜгҖӮ
pip3 install cryptography
ImportError: No module named 'packaging'
зјәе°‘ packaging иҝҷдёӘеҢ…пјҢе®ғжҸҗдҫӣдәҶ Python еҢ…зҡ„ж ёеҝғеҠҹиғҪпјҢеҲ©з”Ё Pip е®үиЈ…еҚіеҸҜгҖӮ
ImportError: No module named '_cffi_backend'
зјәе°‘ cffi еҢ…пјҢдҪҝз”Ё Pip е®үиЈ…еҚіеҸҜпјҡ
pip3 install cffi
ImportError: No module named 'pyparsing'
Pythonиө„жәҗеҲҶдә«qun 784758214 ,еҶ…жңүе®үиЈ…еҢ…пјҢPDFпјҢеӯҰд№ и§Ҷйў‘пјҢиҝҷйҮҢжҳҜPythonеӯҰд№ иҖ…зҡ„иҒҡйӣҶең°пјҢйӣ¶еҹәзЎҖпјҢиҝӣйҳ¶пјҢйғҪж¬ўиҝҺ
зјәе°‘ pyparsing еҢ…пјҢдҪҝз”Ё Pip е®үиЈ…еҚіеҸҜпјҡ
pip3 install pyparsing appdirs





