目录
inheritance继承:... 1
继承中的访问控制:... 5
继承中的初始化:... 9
多继承:... 13
mixin:... 16
习题:... 23
single linkedlist. 25
double linkedlist:... 28
习题:... 32
人类和猪类都继承自动物类;
个体继承自父母,继承了父母的一部分特征,但也可以有自己的个性;
在面向对象的世界中,从父类继承,就可直接拥有父类的属性和方法,这样可减少代码、多复用;
子类可定义自己的属性和方法;
子类继承父类的特征,特征即类属性、类方法、静态方法、实例属性;
公共的属性和方法,包括_开头的;
隐私属性和方法是__开头的,对外暴露提供的方法要为属性装饰器的方法;
open-close-principle开闭原则:
对扩展开放(继承开放),扩展个性化的地方;
修改关闭;
继承也称派生;
class Cat(Animal)这种形式就是从父类继承,括号中写继承的类的列表;
继承可让子类从父类获取特征(属性和方法);
父类,Animal就是Cat的父类,也称基类、超类;
子类,Cat就是Animal的子类,也称派生类;
定义:
class 子类(基类1[,基类2,...]):
语句块
如果定义类时,没有基类列表,等同于继承自object,在python3中,object是所有对象的根基类,倒置的根;
python2中有古典类(旧式类)、新式类,3.0全是新式类;
python支持多继承,继承也可以多级,多级展开即tree,不一定是二叉树;
单继承(一条链串起来);多继承;
单继承关系图:
子类指向父类;
继承的特殊属性和方法:
__base__,类的基类,过时了;
__bases__,类的基类元组;
__mro__,多继承时用,显示方法查找顺序,基类的元组,多继承中非常重要,mro()方法的结果会放在__mro__里;
mro(),多继承时用,同上,int.mro(),在类上用该方法,实例上不能用;
__subclasses__(),类的子类列表,int.__subclasses__();
python不同版本的类:
py2.2之前,类是没有共同的祖先的,之后,引入object类,它是所有类的共同祖先类object;
py2为了兼容,分为古典类(旧式类)和新式类;
py3中全是新式类;
新式类都是继承自object类的,新式类可使用super();
py2与py3版本不同,不仅是语法方面,还有类构建方面;
例:
class Animal(object): #等价于class Animal:,默认继承自object,若加上object则兼容python2
x = 123
def __init__(self):
self.name = 'tom'
def getname(self):
return self.name
class Cat(Animal):
pass
class Dog():
pass
tom = Cat()
print(tom.name)
print(tom.__dict__)
print(tom.getname())
dog = Dog()
# print(dog.name)
# print(dog.getname())
输出:
tom
{'name': 'tom'}
tom
例:
class Animal(object):
x = 123
def __init__(self,name):
self._name = name
@property #装饰后的也能继承,终归Animal类的管辖
def name(self):
return self._name #公共属性
def shout(self):
print('Animal shout')
class Cat(Animal):
x = 'cat' #override覆盖
def shout(self): #override覆盖(重写),与rewrite是两码事
print('miao')
class Dog(Animal):
pass
class Garfield(Cat):
pass
class PersiaCat(Cat):
# def __init__(self): #call to __init__ of super class is missed,需调用父类方法
# self.eyes = 'blue'
pass
tom = Cat('tom')
print(tom.name)
print(tom.__dict__)
tom.shout() #自有的,体现个性
dog = Dog('ahuang')
dog.shout() #自己没有的,用继承的'Animal shout'
gf = Garfield(Cat)
gf.shout()
pc = PersiaCat('persiacat')
print(pc.__dict__)
# pc.name = 'persiacat' #不可修改
pc.eyes = 'blue,green'
pc.shout()
print(pc.name,pc.eyes)
print(pc.__dict__)
输出:
tom
{'_name': 'tom'}
miao
Animal shout
miao
{'_name': 'persiacat'}
miao
persiacat blue,green
{'_name': 'persiacat', 'eyes': 'blue,green'}
例:
gf = Garfield(Cat)
gf.shout()
print('gf.mro={}'.format(gf.__class__.mro())) #mro()方法,只能在类上用,不能在实例上用
print('gf.mro={}'.format(gf.__class__.__mro__))
print('gf.bases={}'.format(gf.__class__.__bases__))
输出:
miao
gf.mro=[<class '__main__.Garfield'>, <class '__main__.Cat'>, <class '__main__.Animal'>, <class 'object'>]
gf.mro=(<class '__main__.Garfield'>, <class '__main__.Cat'>, <class '__main__.Animal'>, <class 'object'>)
gf.bases=(<class '__main__.Cat'>,)
例:
In [1]: int.__subclasses__()
Out[1]: [bool, sre_constants._NamedIntConstant, <enum 'IntEnum'>]
In [2]: int.__bases__
Out[2]: (object,)
In [3]: int.__base__
Out[3]: object
In [4]: int.mro() #返回int自身
Out[4]: [int, object]
In [5]: int.__mro__
Out[5]: (int, object)
从父类继承,自己没有的,就可到父类中找;
私有的都是不可访问的,本质上是改了名并放入所在类的__dict__中,知道这个新名称就可直接找到这个隐藏的变量,这是个黑魔法技巧,慎用;
继承时,公有的(除__开头的),子类和实例都可随意访问;私有的,被隐藏,子类和实例不可直接访问,私有变量所在的类内有方法,则可访问这个私有变量;
python通过自己一套实现,实现和其它语言一样的面向对象的继承机制;
属性查找顺序:
实例的__dict__-->类__dict__,有继承-->父类__dict__;
如果搜索这些地方后没找到就抛异常,先找到就立即返回了;
方法的重写(覆盖)override:
super(),新式类中提供了该方法,可访问到父类的属性,具体原理后续;
Animal.__init__(self,name),py2写法;
super().__init__(name),相当于super(Cat,self).__init__(name)完整写法,py3写法,
self.__class__.__base__.__init__(self,name),不推荐使用;
例:
class Animal(object):
x = 123
def __init__(self,name):
self._name = name
self.__age = 10
class Cat(Animal):
x = 'cat'
class Garfield(Cat):
pass
tom = Garfield('tom')
print(tom.__dict__) #输出隐私属性_Animal__age,_父类的名字__属性,谁有这个属性编译器就改名字为谁,当前只Animal类上有
print(Garfield.__dict__) #子类先找自己的实例,再依次往上找父类
print(Cat.__dict__) #类中找不到_Animal__age,该属性在实例里,self即为实例,实例属性的__dict__,方法是在类中
输出:
{'_name': 'tom', '_Animal__age': 10}
{'__module__': '__main__', '__doc__': None}
{'__module__': '__main__', 'x': 'cat', '__doc__': None}
例(方法的重写(覆盖)):
class Animal(object):
x = 123
def __init__(self,name):
self._name = name
self.__age = 10
@property
def name(self):
return self._name
def shout(self):
print('Animal shout')
class Cat(Animal):
x = 'cat'
def __init__(self,name):
# super(Cat,self).__init__(name)
# super().__init__(name)
Animal.__init__(self,name) #子类中也初始化,python2写法;py3写法为super().__init__(name),新式类推荐使用此种写法;两种方式等价;
#self._name = name #2个属性{'_name': 'tom', '_Animal__age': 10}
#self.catname = name #3个属性{'_name': 'tom', '_Animal__age': 10, 'catname': 'tom'}
self._name = 'cat' + name #2个属性{'_name': 'cattom', '_Animal__age': 10}
tom = Cat('tom')
print(tom.name)
print(tom.__dict__)
输出:
#tom
#{'_name': 'tom', '_Animal__age': 10}
#tom
#{'_name': 'tom', '_Animal__age': 10, 'catname': 'tom'}
cattom
{'_name': 'cattom', '_Animal__age': 10}
例(方法的重写(覆盖)):
class Animal:
def shout(self):
print('Animal shout')
class Cat(Animal):
def shout(self):
print('miao')
def shout(self): #覆盖了自身的shout,之前的彻底没有了;Animal中的shout仍在自己内部,在调用时遮盖了;这两次覆盖有差异
print('cat shout')
print(super())
print(super(Cat,self)) #等价于super()
super().shout()
self.__class__.__base__.shout(self) #不推荐使用,等价于super()
cat = Cat()
cat.shout()
输出:
cat shout
<super: <class 'Cat'>, <Cat object>>
<super: <class 'Cat'>, <Cat object>>
Animal shout
Animal shout
例:
class Animal(object):
x = 123
def __init__(self,name):
self._name = name
self.__age = 10
@property
def name(self):
return self._name
def shout(self):
print('Animal shout')
class Cat(Animal):
x = 'cat'
def __init__(self,name):
# self._name = name
self._name = 'cat' + name #先后有影响
Animal.__init__(self, name)
tom = Cat('tom')
print(tom.name)
print(tom.__dict__)
输出:
tom
{'_name': 'tom', '_Animal__age': 10}
例:
class Animal:
@classmethod
def clsmtd(cls):
print(cls,cls.__name__)
class Cat(Animal):
def __init__(self,name):
self.name = name
@classmethod
def clsmtd(cls):
print(cls,cls.__name__)
class Garfield(Cat): pass
tom = Garfield('tom')
tom.clsmtd() #多态,多态前提要继承,用哪个类创建的实例就是哪个类
print(tom.__dict__)
print(Cat.__dict__)
print(Animal.__dict__) #公有的(除__开头),父类的都是你的,py内部会自动逐级找(可理解为继承的就是我的),传什么就打印什么,用哪个类创建的实例就是哪个类,虽有父类的特征在都继承下来
输出:
<class '__main__.Garfield'> Garfield
{'name': 'tom'}
{'__module__': '__main__', '__init__': <function Cat.__init__ at 0x7f1993df3488>, 'clsmtd': <classmethod object at 0x7f1993df5be0>, '__doc__': None}
{'__module__': '__main__', 'clsmtd': <classmethod object at 0x7f1993df5b70>, '__dict__': <attribute '__dict__' of 'Animal' objects>, '__weakref__': <attribute '__weakref__' of 'Animal' objects>, '__doc__': None}
好习惯 ,在子类中只要有初始化__init__方法,就要把父类的写上,如super().__init__(name),即如果父类中定义了__init__方法,子类中也有__init__,就该在子类的__init__中调用它;
建议:少在继承中使用私有变量;
例:
class A:
def __init__(self,a):
self.a = a
class B(A): #类B定义时声明继承自类A,则在类B中__bases__中可看到类A,但这和是否调用类A的构造方法是两回事
def __init__(self,b,c): #如果B中调用了A的构造方法super().__init__(a)就可拥有父类的属性了,查看b的__dict__
self.b = b
self.c = c
def printv(self):
print(self.b)
print(self.c)
# print(self.a) #AttributeError: 'B' object has no attribute 'a'
b = B(20,30)
b.printv()
print(B.__bases__)
print(B.__dict__)
print(A.__dict__)
输出:
20
30
(<class '__main__.A'>,)
{'__module__': '__main__', '__init__': <function B.__init__ at 0x7fd7e7023158>, 'printv': <function B.printv at 0x7fd7e7023488>, '__doc__': None}
{'__module__': '__main__', '__init__': <function A.__init__ at 0x7fd7e70230d0>, '__dict__': <attribute '__dict__' of 'A' objects>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__doc__': None}
解决上例问题:
class A:
def __init__(self,a):
self.a = a
class B(A):
def __init__(self,b,c):
super().__init__(b+c) #等价于A.__init__(self,b+c)
self.b = b
self.c = c
def printv(self):
print(self.b)
print(self.c)
print(self.a)
b = B(20,30)
b.printv()
print(B.__bases__)
print(b.__dict__)
print(B.__dict__)
print(A.__dict__)
输出:
20
30
50
(<class '__main__.A'>,)
{'a': 50, 'b': 20, 'c': 30}
{'__module__': '__main__', '__init__': <function B.__init__ at 0x7f0e00935158>, 'printv': <function B.printv at 0x7f0e00935488>, '__doc__': None}
{'__module__': '__main__', '__init__': <function A.__init__ at 0x7f0e009350d0>, '__dict__': <attribute '__dict__' of 'A' objects>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__doc__': None}
例:
class A:
def __init__(self,a,d):
self.a = a
self.__d = d
class B(A):
def __init__(self,b,c):
super().__init__(b+c,c-b)
self.b = b
self.c = c
self.__d = b + c + 1
def printv(self):
print(self.b)
print(self.c)
print(self.a)
print(self.__d)
b = B(20,30)
b.printv()
print(b.__class__.__bases__)
print(b.__dict__)
print(B.__dict__)
print(A.__dict__)
输出:
20
30
50
51
(<class '__main__.A'>,)
{'a': 50, '_A__d': 10, 'b': 20, 'c': 30, '_B__d': 51} #实例b的__dict__中有的私有属性,要查看该私有属性必须在该实例所在类中有方法,如果该实例的类中没有访问方法,父类中有同样属性的访问方法,那最终访问的是父类中的属性
{'__module__': '__main__', '__init__': <function B.__init__ at 0x7fadc3ca8158>, 'printv': <function B.printv at 0x7fadc3ca8488>, '__doc__': None}
{'__module__': '__main__', '__init__': <function A.__init__ at 0x7fadc3ca80d0>, '__dict__': <attribute '__dict__' of 'A' objects>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__doc__': None}
例:
class Animal:
def __init__(self,age):
print('Animal init')
self.__age = age
def show(self):
print(self.__age)
class Cat(Animal):
def __init__(self,age,height):
print('Cat init')
super().__init__(age)
self.__age = age + 1
self.__height = height
c = Cat(10,20)
c.show() #show方法在Animal中定义,__age会被解释为_Animal__age,这样设计不好,Cat的实例应显示自己的属性值
print(c.__dict__)
print(Cat.__dict__)
print(Animal.__dict__)
输出:
Cat init
Animal init
10
{'_Animal__age': 10, '_Cat__age': 11, '_Cat__height': 20}
{'__module__': '__main__', '__init__': <function Cat.__init__ at 0x7fad21a10488>, '__doc__': None}
{'__module__': '__main__', '__init__': <function Animal.__init__ at 0x7fad21a100d0>, 'show': <function Animal.show at 0x7fad21a10158>, '__dict__': <attribute '__dict__' of 'Animal' objects>, '__weakref__': <attribute '__weakref__' of 'Animal' objects>, '__doc__': None}
解决上例问题:
一个原则,自己的私有属性,就该自己的方法读取和修改,不要借助其它类的方法,即使是父类或派生类的方法;
class Animal:
def __init__(self,age):
print('Animal init')
self.__age = age
def show(self):
print(self.__age)
class Cat(Animal):
def __init__(self,age,height):
print('Cat init')
super().__init__(age)
self.__age = age + 1
self.__height = height
def show(self):
print(self.__age)
print(self.__height)
c = Cat(10,20)
c.show()
print(c.__dict__)
print(Cat.__dict__)
print(Animal.__dict__)
输出:
Cat init
Animal init
11
20
{'_Animal__age': 10, '_Cat__age': 11, '_Cat__height': 20}
{'__module__': '__main__', '__init__': <function Cat.__init__ at 0x7f565534f488>, 'show': <function Cat.show at 0x7f565534f510>, '__doc__': None}
{'__module__': '__main__', '__init__': <function Animal.__init__ at 0x7f565534f0d0>, 'show': <function Animal.show at 0x7f565534f158>, '__dict__': <attribute '__dict__' of 'Animal' objects>, '__weakref__': <attribute '__weakref__' of 'Animal' objects>, '__doc__': None}
ocp原则,open-closed principle,多继承、少修改;
继承的用途:增强基类、实现多态;
多态:
在面向对象中,父类、子类通过继承联系在一起,如果可通过一套方法,就可实现不同表现,就是多态;
一个类继承自多个类,就是多继承,它将具有多个类的特征;
多继承弊端:
多继承很好的模拟了世界,因为事物很少是单一继承,但是舍弃简单,必然引入复杂性,带来了冲突;
如同一个孩子继承了来自父母双方的特征,那么到底眼睛像爸爸还是妈妈呢?孩子更像谁多一点?
多继承的实现会导致编译器设计的复杂度增加,所以现在很多语言也舍弃了类的多继承,C++支持多继承,java舍弃了多继承;
java中,一个类可实现多个接口,一个接口也可继承多个接口,java的接口很纯粹,只是方法的声明,继承者必须实现这些方法,就具有了这些能力,就能干什么;
多继承可能会带来二异性,如猫和狗都继承自动物类,如果一个类多继承了猫类和狗类,猫和狗都有shout方法,子类空间继承谁的shout呢?
解决方案:
实现多继承的语言,可解决二义性,深度优先或广度优先;
注:单一继承;
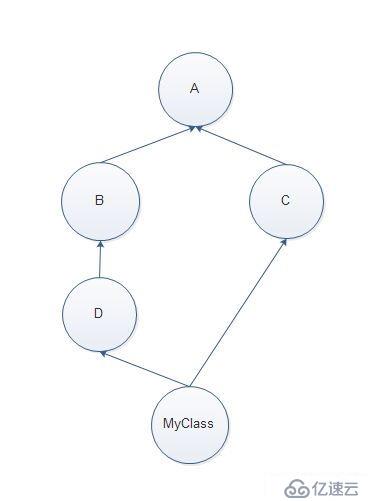
多继承,分开看两条均单继承:
MyClass-->D-->B-->A,深度优先;
MyClass-->D-->C-->B-->A,广度优先;
多继承带来路径选择问题,究竟继承哪个父类的特征呢?
py使用MRO,method resolution order,解决基类搜索顺序问题;
历史原因,MRO有三个搜索算法:
经典算法,按定义从左到右,深度优先策略,2.2之前,MyClass->D->B->A->C->A;
新式类算法,经典算法的升级,重复的只保留一个,2.2,MyClass->D->B->C->A->object;
C3算法,在类被创建出来时,就计算出一个MRO有序列表,2.3之后,py3唯一支持的算法,MyClass->D->B->C->A->object;
多继承的缺点:
当类很多,继承复杂的情况下,继承路径太多,很难说清什么样的继承路径;
py语法允许多继承,但py代码是解释执行,只有执行到的时候才发现错误;
团队协作开发,如果引入多继承,那代码将不可控;
不管编程语言是否支持多继承,都应避免多继承;
py的面向对象,太灵活了,太开放了,所以要团队守规矩,类增加要规范;
规范化、文档化、大量重构;
多继承定义:
class ClassName(基类列表):
类体
UML中,面向对象中的高级部分;
例:
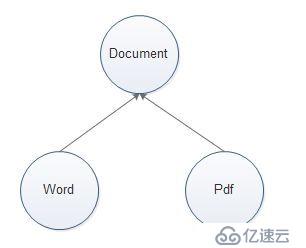
Document类是其它所有文档类的抽象基类;
Word、Pdf是Document类的子类;
要求:
为document子类提供打印能力;
思路1:
在Document类中提供print方法;
基类提供的方法不应该具体实现,因为它未必适合子类的打印,子类中需要覆盖重写;
print算是一种能力——打印功能,不是所有的Document的子类都需要的,所以,从这个角度出发,有问题;
思路2:
需要打印的子类上增加;
如果在子类上直接增加,违反了ocp原则,所以应该继承后增加;
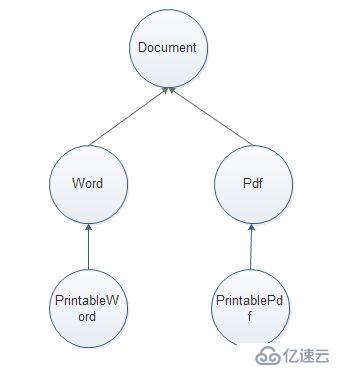
以下两种不同的继承思路,不同场景下用:
方一:用于项目正在开发中,直接加到所属类里;
方二:用于已开发完成项目或第三方库,用继承方式新增类;
看似不错,如果还要提供其它能力,如何继承?
应用于网络,文档应该具备序列化的能力,类上就应该实现序列化;
可序列化还可能分为使用pickle、messagepack、json等;
这时发现,类可能太多了,继承的方式不是很好了,功能太多,A类需要某几样功能,B类需要另几样功能,很繁琐;
思路3:
装饰器,用处极广;
优点:简单方便,在需要的地方动态增加;
用装饰器增强一个类,把功能给类附加上去,哪个类需要,就装饰它;
思路4:
mixin,本质上就是多继承实现的;
mixin体现的是一种组合的设计模式;
在面向对象的设计中,一个复杂的类,往往需要很多功能,而这些功能由来自不同的类提供,这就要将很多的类组合在一起;
从设计模式的角度来说,多组合(混在一起,如PrintableWord(PrintableMixin,Word))、少继承,组合优于继承;
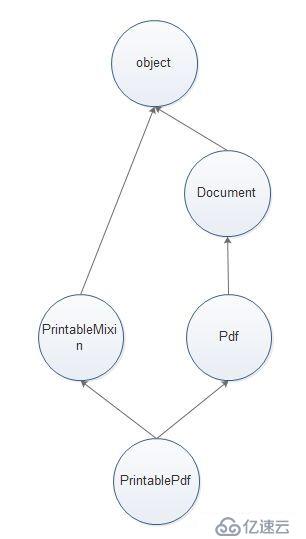
mixin类的使用原则:
mixin类中不应该显式的出现__init__初始化方法(是混进去增强功能的,不用初始化,一般是用来增强类属性,而不是增强实例的,实例缺的东西应在其类上或继承的类上,而不是混进去的);
mixin类通常不能独立工作(不完整),因为它是准备混入别的类中的部分功能实现;
mixin类如有继承,该mixin类的祖先类也应是mixin类;
使用时,mixin类通常在继承列表的第一个位置,如class SuperPrintablePdf(SuperPrintableMixin,Pdf): pass;
mixin类和装饰器:
这两种方式都可使用,看个人喜好;
如果还需要继承,就要使用mixin类方式;
简单用装饰器;复杂用mixin类;
实现方式不同,结果一样(殊途同归);
思路2:方一:
class Document:
def __init__(self,content):
self.content = content
def print(self):
print(self.content)
class Word(Document): #用于项目正在开发中,直接加到所属类里
def print(self):
print('word print: {}'.format(self.content))
class Pdf(Document):
def print(self):
print('pdf print: {}'.format(self.content))
print(Word.mro())
word = Word('test\nabc')
word.print()
print(Word.__dict__)
输出:
[<class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>]
word print: test
abc
{'__module__': '__main__', 'print': <function Word.print at 0x7f87e34ed488>, '__doc__': None}
思路2:方二1:
class Document: #第三方库
def __init__(self,content):
self.content = content
def print(self):
print(self.content)
class Word(Document): pass #第三方库
class PrintableWord(Word):
def print(self):
print('word print: {}'.format(self.content))
class Pdf(Document): pass #第三方库
class PrintablePdf(Pdf):
def print(self):
print('pdf print: {}'.format(self.content))
print(PrintableWord.mro())
word = PrintableWord('test\nabc')
word.print()
print(word.__dict__)
print(PrintableWord.__dict__)
输出:
[<class '__main__.PrintableWord'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>]
word print: test
abc
{'content': 'test\nabc'}
{'__module__': '__main__', 'print': <function PrintableWord.print at 0x7fbbc301e488>, '__doc__': None}
思路2:方二2:
class Printable:
def _print(self):
print(self.content)
class Document:
def __init__(self,content):
self.content = content
def print(self):
print(self.content)
class Word(Document): pass
class PrintableWord(Printable,Word): pass
class Pdf(Document): pass
class PrintablePdf(Printable,Pdf): pass
print(PrintableWord.mro())
word = PrintableWord('test\nabc')
word.print()
print(word.__dict__)
print(PrintableWord.__dict__)
输出:
[<class '__main__.PrintableWord'>, <class '__main__.Printable'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>]
test
abc
{'content': 'test\nabc'}
{'__module__': '__main__', '__doc__': None}
思路3(函数装饰器):
def printable(cls):
# def _print(self):
# print(self.content)
# cls.print = _print #等价于下面一行
cls.print = lambda self: print(self.content)
return cls
class Document:
def __init__(self,content):
self.content = content
def print(self):
print(self.content)
class Word(Document): pass
class Pdf(Document): pass
@printable
class PrintableWord(Word): pass
@printable
class PrintablePdf(Pdf): pass
word = PrintableWord('test\nabc')
word.print()
print(word.__class__.mro())
print(word.__dict__)
print(PrintableWord.__dict__)
输出:
test
abc
[<class '__main__.PrintableWord'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>]
{'content': 'test\nabc'}
{'__module__': '__main__', '__doc__': None, 'print': <function printable.<locals>.<lambda> at 0x7f32371490d0>}
思路4:
class PrintableMixin:
def print(self): #该行和下一行的print,与builtins中冲突?不冲突,这是自定义类中的方法;若把该函数写在与class同级下,就与builtins冲突了
print('~~~~~~~~~~~~~~~~')
print(self.content)
print('~~~~~~~~~~~~~~~~')
class Document:
def __init__(self,content):
self.content = content
class Word(Document): pass
class PrintableWord(PrintableMixin,Word): pass #PrintableMixin只能在前边,如在右边将不起作用,属多继承,本质上是改变了__mro__中的顺序
class Pdf(Document): pass
class PrintablePdf(PrintableMixin,Pdf): pass
class SuperPrintableMixin(PrintableMixin): #mixin是类,可继承
def print(self):
print('#####################')
print(self.content)
print('#####################')
class SuperPrintablePdf(SuperPrintableMixin,Pdf): pass
word = PrintableWord('test\nabc')
word.print()
print(word.__class__.mro()) #查看搜索顺序
print(word.__dict__)
print(word.__class__.__dict__)
pdf = SuperPrintablePdf('pdf\npdf')
pdf.print()
print(pdf.__class__.mro())
print(pdf.__dict__)
print(pdf.__class__.__dict__)
输出:
~~~~~~~~~~~~~~~~
test
abc
~~~~~~~~~~~~~~~~
[<class '__main__.PrintableWord'>, <class '__main__.PrintableMixin'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>]
{'content': 'test\nabc'}
{'__module__': '__main__', '__doc__': None}
#####################
#####################
[<class '__main__.SuperPrintablePdf'>, <class '__main__.SuperPrintableMixin'>, <class '__main__.PrintableMixin'>, <class '__main__.Pdf'>, <class '__main__.Document'>, <class 'object'>]
{'content': 'pdf\npdf'}
{'__module__': '__main__', '__doc__': None}
1、shape基类,要求所有子类都必须提供面积的计算,子类有三角形、矩形、圆;
2、上题圆类的数据可序列化;
3、用面向对象实现linked list链表:
单向链表实现append、iternodes;
双向链表实现append、pop、insert、remove、iternodes;
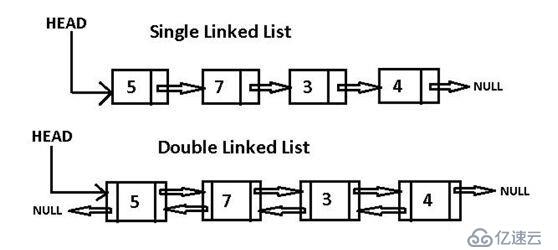
注:
pycharm中格式化,Code-->Reformat Code;
文档字符串一般用""",双引号三引号;
1、
import math
class Shape:
@property
def area(self):
# return
raise NotImplementedError('base class is not implement') #技巧,基类中未实现该方法,即这个父类就是不允许调用
class Triangle(Shape):
def __init__(self,bottom,height):
self.bottom = bottom
self.height = height
@property
def area(self):
return self.bottom * self.height / 2
class Rectangle(Shape):
def __init__(self,length,width):
self.length = length
self.width = width
@property
def area(self):
return self.length * self.width
class Circle(Shape):
def __init__(self,radius):
self.radius = radius
@property
def area(self):
return math.pi * (self.radius ** 2)
triangle = Triangle(3,2)
print(triangle.area)
rectangle = Rectangle(5,4)
print(rectangle.area)
circle = Circle(2)
print(circle.area)
输出:
3.0
20
12.566370614359172
2、
import json
import msgpack
from class_practice_8 import Circle
class SerializableMixin:
def dumps(self,t='json'):
if t == 'json':
return json.dumps(self.__dict__)
elif t == 'msgpack':
return msgpack.dumps(self.__dict__)
else:
raise NotImplementedError('Not implemented serializable')
class SerializableCircleMixin(SerializableMixin,Circle): pass
scm = SerializableCircleMixin(2)
print(scm.area)
print(scm.__dict__)
s = scm.dumps('msgpack')
print(s)
输出:
12.566370614359172
{'radius': 2}
b'\x81\xa6radius\x02'
链表与列表?链表为什么用列表实现?
列表中仅保存的是链表中每个元素内存地址的引用;
链表中每个元素之间是靠自身内部的next联系的;
单向链表,手拉手,有序,内存中是乱的、分散的;
list,内存中有序;
3、
single linkedlist1:
class SingleNode:
def __init__(self,val,next=None):
self.val = val
self.next = next
def __repr__(self):
return str(self.val)
def __str__(self):
return str(self.val)
class LinkedList:
def __init__(self):
# self.nodes = []
self.head = None
self.tail = None
def append(self,val):
node = SingleNode(val)
if self.tail is None:
self.head = node
else:
self.tail.next = node
# self.nodes.append(node)
self.tail = node
def iternodes(self):
current = self.head
while current:
yield current
current = current.next
ll = LinkedList()
node = SingleNode(5)
ll.append(node)
node = SingleNode(6)
ll.append(node)
for node in ll.iternodes():
print(node)
输出:
5
6
single linkedlist2:
class SingleNode: #代表一个节点
def __init__(self,val,next=None): #最后一个为None
self.val = val
self.next = next #实例属性,类中print和装饰器中的_print
def __repr__(self):
return str(self.val)
__str__ = __repr__
class LinkedList: #容器类,某种方式存储一个个节点
def __init__(self):
self.items = [] #保存每个节点的地址;可用索引,便于查询,检索方便,但insert、remove不方便,[]适合读多写少;业务中如果频繁插入元素则不用列表
self.head = None
self.tail = None #追加方便
def append(self,val):
node = SingleNode(val)
if self.tail is None: #尾巴是空则该链表为空
self.head = node
else:
self.tail.next = node
self.tail = node
self.items.append(node)
def iternodes(self): #要知道链表中的元素必须迭代;技巧:generator
current = self.head
while current:
yield current
current = current.next
def __getitem__(self, item): #仅用于容器,提供一种方便的接口,如索引或其它方式来用
return self.items[item]
def __len__(self): #很少拿长度,频繁操作长度一直在变,只是大概
return len(self.items)
ll = LinkedList()
node = SingleNode(5)
ll.append(node)
node = SingleNode(6)
ll.append(node)
for node in ll.iternodes():
print(node)
print(ll[0])
输出:
5
6
5
2
技巧:
generator;
三目运算符;
enumerate();
class SingleNode:
def __init__(self,val,next=None,prev=None):
self.val = val
self.next = next
self.prev = prev
def __repr__(self):
return str(self.val)
__str__ = __repr__
class LinkedList:
def __init__(self):
# self.items = []
self.head = None
self.tail = None
def append(self,val):
node = SingleNode(val)
if self.tail is None: #第一个node,the first node
self.head = node
else:
self.tail.next = node
node.prev = self.tail #当前节点的上一个节点
self.tail = node
# self.items.append(node)
def iternodes(self,reverse=False):
current = self.tail if reverse else self.head #2个技巧,generator函数和类三目运算符
while current:
yield current
current = current.prev if reverse else current.next
def pop(self):
if self.tail is None: #链表中元素为0
raise Exception('Empty')
tail = self.tail
prev = tail.prev
# next = tail.next #用不上,尾巴的下一个元素一定为None
if prev is None: #尾巴的前一个元素为空,说明该链表仅一个元素
self.head = None
self.tail = None #把当前尾巴的元素清空后,链表就为空
else: #链表中元素>1个
self.tail = prev
prev.next = None
return tail.val
def getitem(self,index):
if index < 0:
return None
current = None
for i,node in enumerate(self.iternodes()): #技巧
if i == index:
current = node
break
if current is None: #如下四行可简写为if current is not None: return current
return None
else:
return current
def insert(self,index,val): #考虑当前链表,0个元素,1个元素(index为0、1时),尾部追加
if index < 0:
raise Exception('Error')
current = None
for i,node in enumerate(self.iternodes()):
if i == index:
current = node
break
if current is None: #链表中无元素,index只要大于边界就往里追加
self.append(val)
return
prev = current.prev
# next = current.next
node = SingleNode(val)
if prev is None: #前加、中间加、尾部加
self.head = node
node.next = current
current.prev = node
else:
node.prev = prev
node.next = current
current.prev = node
prev.next = node
def remove(self,index):
if self.tail is None:
raise Exception('Empty')
if index < 0:
raise ValueError('Wrong Index{}'.format(index))
current = None
for i,node in enumerate(self.iternodes()):
if i == index:
current = node
break
if current is None:
raise ValueError('Wrong Index {} out of memory'.format(index))
prev = current.prev
next = current.next
if prev is None and next is None:
self.head = None
self.tail = None
elif prev is None:
self.head = next
next.prev = None
elif next is None:
self.tail = prev
prev.next = None
else:
prev.next = next
next.prev = prev
del current
ll = LinkedList()
node1 = SingleNode('abc')
ll.append(node1)
node2 = SingleNode(4)
ll.append(node2)
node3 = SingleNode(5)
ll.append(node3)
node4 = SingleNode(6)
ll.append(node4)
node5 = SingleNode('end')
ll.append(node5)
for node in ll.iternodes():
print(node)
print('~'*20)
ll.pop()
ll.pop()
ll.pop()
ll.insert(0,'start') #各种测试,前、中、尾,元素为空,元素为1个
ll.insert(8,'end')
ll.insert(1,123)
ll.insert(2,456)
ll.remove(5)
ll.remove(0)
for node in ll.iternodes(reverse=True):
print(node)
输出:
abc
4
5
6
end
~~~~~~~~~~~~~~~~~~~~
4
abc
456
123
1、将链表,封装成容器:
要求:
1)提供__getitem__()、__iter__()、__setitem__();
2)使用一个列表,辅助完成上面的方法;
3)进阶:不使用列表,完成上面的方法;
2、实现类property装饰器,类名称为Property;
1、方一(容器实现):
class SingleNode:
def __init__(self,val,next=None,prev=None):
self.val = val
self.next = next
self.prev = prev
def __repr__(self):
return str(self.val)
__str__ = __repr__
class LinkedList:
def __init__(self):
self.items = []
self.head = None
self.tail = None
self.size = 0
def append(self,val):
node = SingleNode(val)
if self.tail is None:
self.head = node
else:
self.tail.next = node
node.prev = self.tail
self.tail = node
self.items.append(node)
self.size += 1
def iternodes(self,reverse=False):
current = self.tail if reverse else self.head
while current:
yield current
current = current.prev if reverse else current.next
def pop(self):
if self.tail is None:
raise Exception('Empty')
tail = self.tail
prev = tail.prev
# next = tail.next
if prev is None:
self.head = None
self.tail = None
else:
self.tail = prev
prev.next = None
self.items.pop()
self.size -= 1
return tail.val
def getitem(self,index):
if index < 0:
return None
current = None
for i,node in enumerate(self.iternodes()):
if i == index:
current = node
break
if current is None:
return None
else:
return current
def insert(self,index,val):
if index < 0:
raise Exception('Error')
current = None
for i,node in enumerate(self.iternodes()):
if i == index:
current = node
break
if current is None:
self.append(val)
return
prev = current.prev
# next = current.next
node = SingleNode(val)
if prev is None:
self.head = node
node.next = current
current.prev = node
else:
node.prev = prev
node.next = current
current.prev = node
prev.next = node
self.items.insert(index,val)
self.size += 1
def remove(self,index):
if self.tail is None:
raise Exception('Empty')
if index < 0:
raise ValueError('Wrong Index{}'.format(index))
current = None
for i,node in enumerate(self.iternodes()):
if i == index:
current = node
break
if current is None:
raise ValueError('Wrong Index {} out of memory'.format(index))
prev = current.prev
next = current.next
if prev is None and next is None:
self.head = None
self.tail = None
elif prev is None:
self.head = next
next.prev = None
elif next is None:
self.tail = prev
prev.next = None
else:
prev.next = next
next.prev = prev
del current
self.items.pop(index)
self.size -= 1
def __len__(self):
return self.size
# def __iter__(self):
# return iter(self.items)
__iter__ = iternodes
def __getitem__(self, item):
return self.items[item]
def __setitem__(self, key, value):
self.items[key].val = value #如果出错,借用列表来抛异常,不需自己实现
ll = LinkedList()
node1 = SingleNode('abc')
ll.append(node1)
node2 = SingleNode(4)
ll.append(node2)
node3 = SingleNode(5)
ll.append(node3)
node4 = SingleNode(6)
ll.append(node4)
# ll.remove(3)
node5 = SingleNode('end')
ll.append(node5)
for node in ll.iternodes():
print(node)
print('~'*20)
ll.pop()
node6 = SingleNode('head')
ll.insert(0,node6)
node7 = SingleNode('middle')
ll.insert(3,node7)
ll.remove(3)
# print(len(ll))
for node in ll:
print(node)
# print(node7.next) #None
1、方二(非容器实现):
class SingleNode:
def __init__(self,val,next=None,prev=None):
self.val = val
self.next = next
self.prev = prev
def __repr__(self):
return str(self.val)
__str__ = __repr__
class LinkedList:
def __init__(self):
# self.items = []
self.head = None
self.tail = None
self.size = 0
def append(self,val):
node = SingleNode(val)
if self.tail is None:
self.head = node
else:
self.tail.next = node
node.prev = self.tail
self.tail = node
# self.items.append(node)
self.size += 1
def iternodes(self,reverse=False):
current = self.tail if reverse else self.head
while current:
yield current
current = current.prev if reverse else current.next
def pop(self):
if self.tail is None:
raise Exception('Empty')
tail = self.tail
prev = tail.prev
# next = tail.next
if prev is None:
self.head = None
self.tail = None
else:
self.tail = prev
prev.next = None
# self.items.pop()
self.size -= 1
return tail.val
def getitem(self,index):
if index < 0:
return None
current = None
for i,node in enumerate(self.iternodes()):
if i == index:
current = node
break
if current is None:
return None
else:
return current
def insert(self,index,val):
if index < 0:
raise Exception('Error')
current = None
for i,node in enumerate(self.iternodes()):
if i == index:
current = node
break
if current is None:
self.append(val)
return
prev = current.prev
# next = current.next
node = SingleNode(val)
if prev is None:
self.head = node
node.next = current
current.prev = node
else:
node.prev = prev
node.next = current
current.prev = node
prev.next = node
# self.items.insert(index,val)
self.size += 1
def remove(self,index):
if self.tail is None:
raise Exception('Empty')
if index < 0:
raise ValueError('Wrong Index{}'.format(index))
current = None
for i,node in enumerate(self.iternodes()):
if i == index:
current = node
break
if current is None:
raise ValueError('Wrong Index {} out of memory'.format(index))
prev = current.prev
next = current.next
if prev is None and next is None:
self.head = None
self.tail = None
elif prev is None:
self.head = next
next.prev = None
elif next is None:
self.tail = prev
prev.next = None
else:
prev.next = next
next.prev = prev
del current
# self.items.pop(index)
self.size -= 1
def __len__(self):
return self.size
# def __iter__(self):
# return iter(self.items)
__iter__ = iternodes #可用partial解决reverse传参问题
# def __getitem__(self, item):
# return self.items[item]
def __getitem__(self, index):
# for i,node in enumerate(self.iternodes()):
# if i == index:
# return node
# for i,node in enumerate(self.iternodes(True),1):
# if -i = index:
# return node
flag = False if index >= 0 else True
start = 0 if index >= 0 else 1
for i,node in enumerate(self.iternodes(flag),start):
if i == abs(index):
return node
# def __setitem__(self, key, value):
# self.items[key] = value
def __setitem__(self, key, value):
#self.items[key] = value #X错误,self.items[key]的结果为SingleNode的实例不能赋值,赋值得是实例.val=value,即self.items[key].val = value
# node = self[key] #self[key]利用了__getitem__(),同node = self.items[key];此处两行可简写为self[key].val = value
# node.val = value
self[key].val = value
ll = LinkedList()
node1 = SingleNode('abc')
ll.append(node1)
node2 = SingleNode(4)
ll.append(node2)
node3 = SingleNode(5)
ll.append(node3)
node4 = SingleNode(6)
ll.append(node4)
# ll.remove(3)
node5 = SingleNode('end')
ll.append(node5)
for node in ll.iternodes():
print(node)
print('~'*20)
ll.pop()
node6 = SingleNode('head')
ll.insert(0,node6)
node7 = SingleNode('middle')
ll.insert(3,node7)
ll.remove(3)
# print(len(ll))
ll[2]=1
ll[-1]=3
ll[-2]=2
ll[0]='head1'
ll[0]=123
for node in ll:
print(node)
# print(node7.next) #None
2、
class Property:
def __init__(self,fget,fset=None):
self.fget = fget
self.fset = fset
def __get__(self, instance, owner):
if instance is not None:
return self.fget(instance)
return self
def __set__(self, instance, value):
if callable(self.fset):
self.fset(instance,value)
else:
raise AttributeError('attribute error')
def setter(self,fn):
self.fset = fn
return self
class A:
def __init__(self,data):
self._data = data
@Property
def data(self):
return self._data
@data.setter
def data(self,value):
self._data = value
a = A(100)
print(a.data)
a.data = 200
print(a.data)
输出:
100
200
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





