Python字符串——一个有序字符的集合,用于存储和表现基于文本的信息。
Python中没有单个字符的类型,只有使用一个字符的字符串。
字符串被划分为不可变序列,意味着这些字符串所包含的字符存在从左往右的位置程序,并且不可以在原处修改。
常见字符串常量和表达式:
#
单引号:'Yert"s'
双引号:"Yert's"
三引号:"....................Yert................................"
转义字符:’\tp’
Raw字符串:r"C:w\test.com"
Python3.0中的Byte字符串:b’sp\x01
只在Python2.6出现的Unicode字符串:u’egg\suu’
单双引号的作用相同:
>>> 'Yert',"Yert"
('Yert', 'Yert')
Python自动合并相邻的字符串常量:
>>> title="The truth " 'of' "life"
>>>
>>> title
'The truth oflife'
三重引号编写多行字符串块:
>>>
>>> longfile='''
...
...
... a
... a
... a
... a
... a
... '''
>>>
>>>
>>> longfile
'\n\n\na\na\na\na\na\n'
>>>
>>> print(longfile)
a
a
a
a
a
>>>
转义字符序列: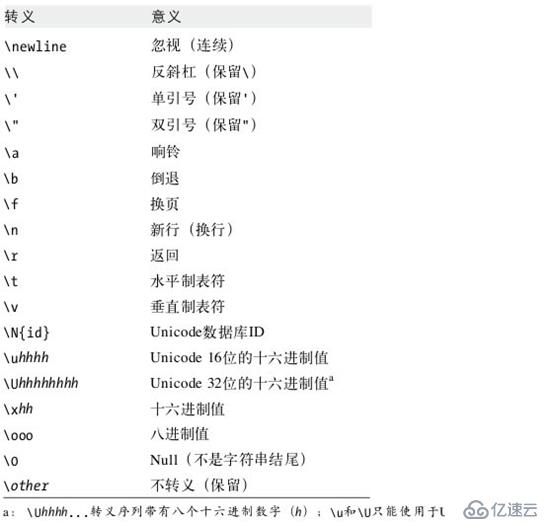
通过反斜杠转义字符嵌入引号:
>>> 'today\'s',"yesterday\"s"
("today's", 'yesterday"s')
转义序列插入绝对的二进制值:
>>>
>>> s = 'a\0b\0c'
>>>
>>> s
'a\x00b\x00c'
>>>
>>> len(s)
5
>>>
Python会在内存中保持了整个字符串的长度和文本,Python没有字符会结束一个字符串。
>>>
>>> s = '\001\002\003'
>>>
>>> s
'\x01\x02\x03'
>>>
>>> len(s)
3
>>>
如果Python没有作为一个合法的转义编码识别出在“\”后的字符,它就直接在最终的字符串中保留反斜杠。
>>> x = "C:\py\code"
>>>
>>> x
'C:\\py\\code'
raw字符串抑制转义
Raw字符串:如果字母r(大写或小写)出现在字符串的第一引号的前面,它将会关闭转义机制。Python将反斜杠作为常量来保持,就像普通字符串,为了避免错误,在Windows系统中必须增加字母r。
>>> myfile=open(r'D:test\test.txt','w')
>>>
>>> text="I'm Yert,the word would been wroten in text."
>>>
>>> myfile.write(text)
44
>>>
>>> myfile.close()
索引和分片:
索引:
字符串在Python中被定义为字符的有序集合,可以通过位置偏移值获取字符。在Python中,字符串中的字符是通过索引(通过在字符串之后的方括号中提供所需要的元素的数字偏移量)提取的。
Python的偏移量是从0开始,并比字符串的长度小1,还支持在字符串中使用负偏移的方法从序列中获取因素。从技术上讲,一个负偏移与这个字符串长度相加可以得到它的正偏移值。
>>> S='YertAlan'
>>>
>>> S[0]
'Y'
>>> S[-1]
'n'
>>>
>>> len(S)
8
>>> S[len(S)-1]
'n'
分片:
当使用一对以冒号分隔的偏移来索引字符串时,Python将会返回一个新的对象,其中包含了以这对偏移所标识的连续内容。
>>> S[1:3]
'er'
>>> S[1:]
'ertAlan'
>>>
>>> S[::]
'YertAlan'
>>>
>>> S[-4:-1]
'Ala'
>>>
>>> S[:-2]
'YertAl'
拓展分片:第三个限制值
分片表达式增加一个可选的第三个索引,用作步进。步进添加到每个提取的元素的索引中。完×××式的分片为string[X:Y:Z],表示“索引字符串string对象中的元素,从偏移X直到偏移为Y-1,每隔Z元素索引一次”。第三个限制没人为1,所以通常在一个切片中从左至右提取每一个元素的原因。
>>> string='ABCDEFGHIJKLMNOPQRST'
>>>
>>> string[1:8]
'BCDEFGH'
>>>
>>> string[1:8:2]
'BDFH'
>>>
>>> string[1:12]
'BCDEFGHIJKL'
>>> string[1:12:3]
'BEHK'
负数步进:
>>> string[1:10]
'BCDEFGHIJ'
>>>
>>> string[1:10:-1]
''
>>> string[10:1:-1]
'KJIHGFEDC'
>>>
>>> string[10:1]
''
>>> string[10:1:-2]
'KIGEC'
字符串转换工具
>>>#将以字符串形式出现的数字进行转换:
>>> int('55'),str(55)
(55, '55')
>>> repr(55)
'55'
注意:Repr函数可以将一个对象转换为其字符串形式,然而这些返回的对象作为代码的字符串,可以重新创建对象。
>>> print(str('Yert'),repr('Yert'))
Yert 'Yert'
>>>#浮点数转换字符串:
>>> str(3.1415),float("1.5")
('3.1415', 1.5)
>>>
>>> text="1.234E-10"
>>>
>>> float(text)
1.234e-10
字符串代码转换:
单个字符可以通过将其传给内置的ord函数转换为其对应的ASCII码——则个函数实际返回的是这个字符在内存中对应的字符的二进制值。而chr函数将会执行相反的操作,获取ASCII码并将其转换为对应的字符:
>>> ord('s')
115
>>>
>>> chr(115)
's'
>>>#执行基于字符串的数学运算:
>>> S='a'
>>> S=chr(ord(S)+1)
>>> S
'b'
>>> S=chr(ord(S)+1)
>>>
>>> S
'c'
>>> int('5')
5
>>>
>>> ord('5') - ord('0')
5
与循环语句结合,进行整数的处理:
将二进制字符串转换为整数,并将当前值乘以2,并加上下一位数字值。
>>> B = '1101'
>>> I = 0
>>> while B != '':
... I = I * 2 + (ord(B[0])-ord('0'))
... B = B[1:]
...
>>>
>>> I
13
>>>
修改字符串
>>>#使用合并、分片:
>>> S='Yert'
>>>
>>> S = 'Yert'
>>> S = S + 'Alan'
>>> S
'YertAlan'
>>> S = S[:4] + '·D·' + S[4:] #D之一族
>>>
>>> S
'Yert·D·Alan'
使用replace函数修改(索引到字符串,将其改为指定字符串):
>>> S=S.replace('Alan','King')
>>> S
'Yert·D·King'
通过字符串格式化表达式来创建新字符串:
>>> "March %sst,I'm a apple,I'm have a %s" % (1,'pencil')
"March 1st,I'm a apple,I'm have a pencil"
>>>
>>> "March {0}st,I'm a apple,I'm have a {1}".format(1,'pencil')
"March 1st,I'm a apple,I'm have a pencil"
使用find方法进行修改:
>>> S = '13658934230' #实现修改号码,保护隐私
>>>
>>> node = S.find('5893')
>>>
>>> node
3
>>> S = S[:node] + 'XXXX' + S[(node+4):]
>>>
>>> S
'136XXXX4230'
使用合并操作和replace方法每次运行产生新的字符串对象,会消耗性能,所以在对超长文本进行多处修改时,需要将字符串转换为一个支持原处修改的对象。
>>> S = 'yert'
>>>
>>> L = list(S)
>>>
>>> L
['y', 'e', 'r', 't']
内置的list函数(或一个对象构造函数调用)以任意序列中的元素创立一个新的列表,可以将字符串中的字符分解为一个列表。
Join函数可以将列表合成为一个字符串:
>>> D = ''.join(L)
>>>
>>> D
'yert'
其他字符串方法:
>>>#通过分片的方式将数据从原始字符串中分离,称为解析。
>>> S
'yert'
>>>
>>> J = S[1:3]
>>>
>>> J
'er'
>>>#如果分隔符分开了数据组件,可以使用split方法提取组件。
>>> date = 'My name is Yert'
>>>
>>> cols = date.split()
>>>
>>> cols
['My', 'name', 'is', 'Yert']
>>>
>>> long_str = 'My name is Yert, I am a computer engineer,I am studing Python'
>>>
>>> cols = long_str.split(',')
>>>
>>> cols
['My name is Yert', ' I am a computer engineer', 'I am studing Python']
>>> line = 'The dog is Sam which it is yellow ! \n'
>>>#清除每行末尾空白
>>> line.rstrip()
'The dog is Sam which it is yellow !'
>>>#全部转换大写
>>> line.upper()
'THE DOG IS SAM WHICH IT IS YELLOW ! \n'
>>>#测试内容
>>> line.isalpha()
False
>>>
>>>#检测末尾内容字符串
>>> line.endswith('! \n')
True
>>>#检测开始内容字符串
>>> line.startswith('The')
True
>>> line[-len('! \n'):] == '! \n'
True
>>>
>>> line[:len('The ')] == 'The '
True
字符串格式化表达式
格式化字符串:
>>> '%d years later,I have became a %s!' % (3,'engineer')
'3 years later,I have became a engineer!'
高级字符串格式化表达式:
转换目标通用结构:
%[ (name) ] [flags] [width] [.precision] typecode
表中的字节码出现在目标字符串的尾部,在%和字符码只间:可以放置一个字典的键;罗列出左对齐(-)、正负号(+)和补零(0)的标志位;给出数字的整体长度和小数点后的位数等。Width和precision都可编码为一个*,以指定它们应该从输入值的下一项中取值。
>>>#%d对整数进行默认,%-6d进行6位的左对齐格式化,%06d进行6位补零的格式化
>>> M = 24
>>>
>>> resu = "result: %d %-6d %06d" % (M,M,M)
>>>
>>> resu
'result: 24 24 000024'
>>>#可以在格式化字符串中用一个*来指定通过计算得出width和precision,从而迫使它们的值从%运算符右边的输出中的下一项获取,元组中的4指定为precision。
>>> '%f,%.2f,%.*f' % (1/3.0,1/3.0,4,1/3.0)
'0.333333,0.33,0.3333'
基于字典字符串格式化
>>>#通过字典的键来提取对应的值:
>>> "%(a)d %(x)s" % {'a':1,'x':'Yert'}
'1 Yert'
>>>#Format方法格式化字符串:
>>> date = '{0},{1} and {2}'
>>>
>>> date.format('Python','PHP','Go')
'Python,PHP and Go'
>>>
>>> date = '{a},{b} and {c}'
>>>
>>> date.format(a='Python',b='PHP',c='Go')
'Python,PHP and Go'
>>>
>>>
>>> date = '{a},{0} and {c}'
>>>
>>> date.format('PHP',a='Python',c='Go')
'Python,PHP and Go'
格式化字符串可以指定对象属性和字典键。
>>> import sys
>>>
>>> 'The machine {1[name]} runs {0.platform}'.format(sys,{'name':'Yert'})
'The machine Yert runs win32'
>>>
>>> 'The machine {config[name]} runs {sys.platform}'.format(sys=sys,config={'name':'Yert'})
'The machine Yert runs win32'
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





