这篇文章将为大家详细讲解有关怎么在MySQL中实现分表与分区,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
分表
单表数据量太大时,会严重影响sql执行的性能。一般单表到达几百万的时候,性能就会相对差一些了,这时就得分表了。
分表就是把一个表的数据放到多个表中,然后查询的时候就查一个表。比如按照项目id来分表:将固定数量的项目数据放在一个表中,这样就可以控制每个表的数据量在可控的范围内。
分库
根据经验来讲,一个库最多支持到并发2000时就需要扩容了,而且一个健康的单库并发值最好保持在1000左右。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
这就是所谓的分库分表,为啥要分库分表?
提高并发支撑能力
降低磁盘使用率
提高SQL执行性能
直接看图:
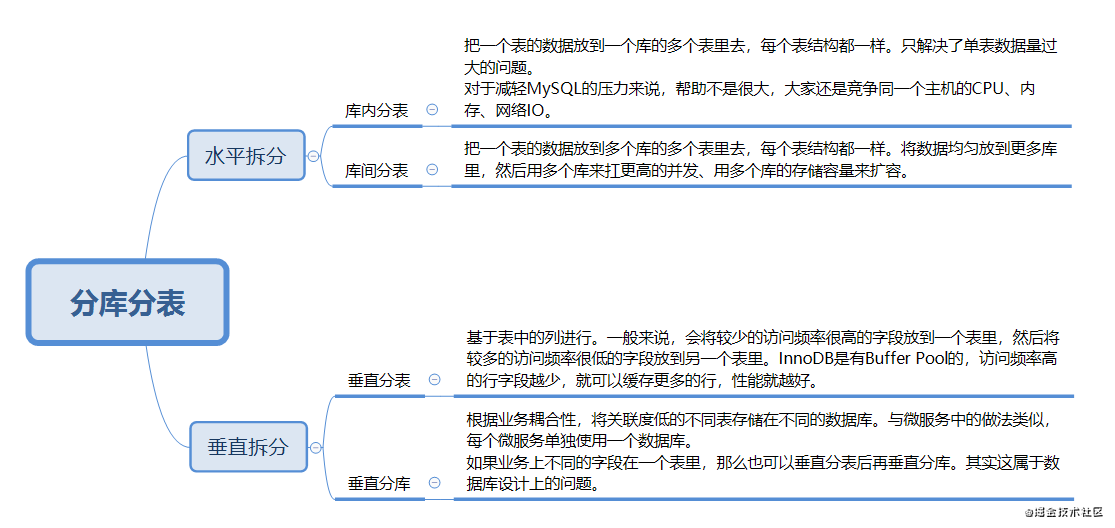
对于垂直拆分,建议最好在系统设计之初做好表设计,避免垂直分表。
水平拆分可以按照range来分,或是按照某个字段hash。按照range来分,好处在于扩容简单,准备好新的表或库就可以了。但是容易产生热点问题,实际使用时要结合业务场景来看。按照hash来分,好处在于可以平均分配每个库或表的请求压力,缺点是扩容麻烦,之前的数据要rehash,存在一个数据迁移的过程。
分库分表能有效地缓解单机和单库带来的网络IO、硬件资源、连接数的压力。但也带来了一些问题。
事务一致性问题
通过分布式事务或者保证最终一致性来解决。
跨节点关联查询join问题
全局表、字段冗余、数据组装、ER分片
跨节点分页、排序、聚集函数问题
首先在不同分片节点进行查询,最后要对结果进行汇总或归并
全局主键避重问题
各种分布式ID生成算法
数据迁移、扩容问题
如果是range分片,只需要添加节点就可以进行扩容了。
如果是hash,一般做法是先读出历史数据,然后按指定的分片规则再将数据写入到各个分片节点中。
数据迁移介绍两种方案。
一个最low的方案,就是系统停机一段时间,用实现写好的导数据的工具跑一遍把单独单表的数据独出来,写到分库分表里面去。
第二个方案听起来就比较靠谱了,双写迁移方案。在线上系统里,之前所有写数据的地方,增删改操作,除了对旧库增删改,再加上对新库的增删改,这就是所谓的双写。然后系统部署之后,把方案一里的导数据工具跑起来,读老库写新库。写的时候要根据gmt_modified这类字段判断这条数据最后修改的时间,除非是读出来新库没有,或是比新库数据新才会写。简单来说就是不允许用老数据覆盖新数据。
写完一轮之后,有可能还是存在不一致,那么就程序自动新一轮校验,对比新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环直到数据完全一致。
分库分表的中间件比较常见的有:
Cobar:阿里b2b团队开发和开源的,属于proxy层方案,介于应用服务器和数据库服务器之间。应用程序通过JDBC驱动访问Cobar集群,Cobar根据SQL和分库规则对SQL做分解,然后分发到MySQL集群不同的数据库实例上执行。不支持读写分离、存储过程、跨库join和分页等操作。最近几年都没更新了,也没啥人用了。
TDDL:淘宝团队开发的,属于client层方案。支持基本的crud语法和读写分离,但不支持join、多表查询等语法。目前只用也不多,因为还依赖淘宝的diamond配置管理系统。
Atlas:360开源的,属于proxy层方案。也是好几年没维护,现在用的公司基本也很少了。
Sharding-jdbc:当当开源的,属于client层方案,目前已更名为ShardingSphere。SQL语法支持的也比较多,没有太多限制,支持分库分表、读写分离、分布式id生成、柔性事务(最大努力送达型事务、TCC事务)。而且使用的公司比较多,社区活跃。
Mycat:基于Cobar改造,属于proxy层方案。支持的功能非常完善。相比Sharding-jdbc来说,年轻一些。
综上,现在可以考虑使用的就是Sharding-jdbc和Mycat。
Sharding-jdbc这种client层方案的有点在于不用部署,运维成本低,不需要代理层的二次转发,性能高。缺点是有耦合性。
Mycat这种proxy层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处在于对项目是透明的。
这里介绍分区主要是防止和切分、分库分表等概念混淆。
MySQL从5.1版本开始支持分区(partition)的功能。分区指根据一定的规则,数据库把一个表分解成多个更小的、更容易管理的部分。就访问数据库的应用而言,逻辑上只有一个表或一个索引,但是实际上这个表可能由多个物理分区组成,即对应用是透明的。
MySQL分区引入了分区键的概念,采取分治法,有利于管理非常大的表。分区键用于根据某个区间值、特定值列表或HASH函数执行数据的聚集,让数据根据规则分布在不同的分区中。MySQL 5.7中可用的分区类型主要有以下6种:
RANGE分区:基于一个给定连续区间范围,把数据分配到不同的分区。
LIST分区:类似RANGE分区,区别在LIST分区是基于枚举出的值列表分区,RANGE是基于给定的连续区间范围分区。
COLUMNS分区:类似于RANGE和LIST,区别在于分区键既可以是多列,又可以是非整数。
HASH分区:基于给定的分区个数,把数据取模分配到不同的分区。
KEY分区:类似于HASH分区,但使用MySQL提供的哈希函数。
子分区:也叫做复合分区或者组合分区,即在主分区下再做一层分区,将数据再次分割。
这里举一LIST分区的例子:
CREATE TABLE orders_list ( id INT AUTO_INCREMENT, customer_surname VARCHAR(30), store_id INT, salesperson_id INT, order_date DATE, note VARCHAR(500), INDEX idx (id) ) ENGINE = INNODB PARTITION BY LIST(store_id) ( PARTITION p1 VALUES IN (1, 3, 4, 17) INDEX DIRECTORY = '/var/orders/district1' DATA DIRECTORY = '/var/orders/district1', PARTITION p2 VALUES IN (2, 12, 14) INDEX DIRECTORY = '/var/orders/district2' DATA DIRECTORY = '/var/orders/district2', PARTITION p3 VALUES IN (6, 8, 20) INDEX DIRECTORY = '/var/orders/district3' DATA DIRECTORY = '/var/orders/district3', PARTITION p4 VALUES IN (5, 7, 9, 11, 16) INDEX DIRECTORY = '/var/orders/district4' DATA DIRECTORY = '/var/orders/district4', PARTITION p5 VALUES IN (10, 13, 15, 18) INDEX DIRECTORY = '/var/orders/district5' DATA DIRECTORY = '/var/orders/district5' );
分区的优点:
扩大存储容量。
优化查询。在WHERE子句中包含分区条件时可以只扫描必要的分区来提高查询效率;同事在涉及SUM()和COUNT()这类聚合函数的查询时,可以在每个分区上并行处理。
对于已经过期或不需要保存的数据分区,可以通过删除分区来快速删除数据。
跨多磁盘来分散查询数据,获得更大的查询吞吐量。
关于怎么在MySQL中实现分表与分区就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





