这篇文章给大家分享的是有关pytorch怎么把图像数据集进行划分成train,test和val的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
如图所示
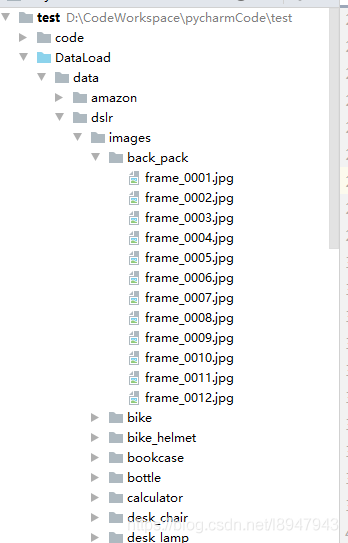
|---data |---dslr |---images |---back_pack |---a.jpg |---b.jpg ...
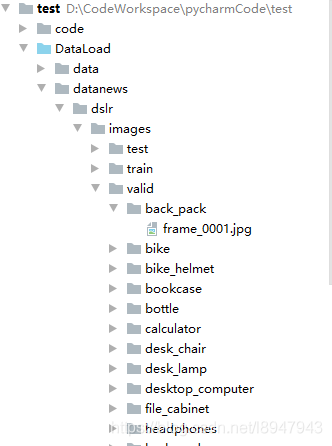
目录结构为:
|---datanews |---dslr |---images |---test |---train |---valid |---back_pack |---a.jpg |---b.jpg ...
4.1 先创建同样结构的层级结构
4.2 然后讲原始数据按照比例划分
4.3 移入到对应的文件目录里面
import os, random, shutil def make_dir(source, target): ''' 创建和源文件相似的文件路径函数 :param source: 源文件位置 :param target: 目标文件位置 ''' dir_names = os.listdir(source) for names in dir_names: for i in ['train', 'valid', 'test']: path = target + '/' + i + '/' + names if not os.path.exists(path): os.makedirs(path) def divideTrainValiTest(source, target): ''' 创建和源文件相似的文件路径 :param source: 源文件位置 :param target: 目标文件位置 ''' # 得到源文件下的种类 pic_name = os.listdir(source) # 对于每一类里的数据进行操作 for classes in pic_name: # 得到这一种类的图片的名字 pic_classes_name = os.listdir(os.path.join(source, classes)) random.shuffle(pic_classes_name) # 按照8:1:1比例划分 train_list = pic_classes_name[0:int(0.8 * len(pic_classes_name))] valid_list = pic_classes_name[int(0.8 * len(pic_classes_name)):int(0.9 * len(pic_classes_name))] test_list = pic_classes_name[int(0.9 * len(pic_classes_name)):] # 对于每个图片,移入到对应的文件夹里面 for train_pic in train_list: shutil.copyfile(source + '/' + classes + '/' + train_pic, target + '/train/' + classes + '/' + train_pic) for validation_pic in valid_list: shutil.copyfile(source + '/' + classes + '/' + validation_pic, target + '/valid/' + classes + '/' + validation_pic) for test_pic in test_list: shutil.copyfile(source + '/' + classes + '/' + test_pic, target + '/test/' + classes + '/' + test_pic) if __name__ == '__main__': filepath = r'../data/dslr/images' dist = r'../datanews/dslr/images' make_dir(filepath, dist) divideTrainValiTest(filepath, dist)
补充:pytorch中数据集的划分方法及eError: take(): argument 'index' (position 1) must be Tensor, not numpy.ndarray错误原因
在使用pytorch框架时,难免需要对数据集进行训练集和验证集的划分,一般使用sklearn.model_selection中的train_test_split方法
from sklearn.model_selection import train_test_split import numpy as np import torch import torch.autograd import Variable from torch.utils.data import DataLoader traindata = np.load(train_path) # image_num * W * H trainlabel = np.load(train_label_path) train_data = traindata[:, np.newaxis, ...] train_label_data = trainlabel[:, np.newaxis, ...] x_tra, x_val, y_tra, y_val = train_test_split(train_data, train_label_data, test_size=0.1, random_state=0) # 训练集和验证集使用9:1 x_tra = Variable(torch.from_numpy(x_tra)) x_tra = x_tra.float() y_tra = Variable(torch.from_numpy(y_tra)) y_tra = y_tra.float() x_val = Variable(torch.from_numpy(x_val)) x_val = x_val.float() y_val = Variable(torch.from_numpy(y_val)) y_val = y_val.float() # 训练集的DataLoader traindataset = torch.utils.data.TensorDataset(x_tra, y_tra) trainloader = DataLoader(dataset=traindataset, num_workers=opt.threads, batch_size=8, shuffle=True) # 验证集的DataLoader validataset = torch.utils.data.TensorDataset(x_val, y_val) valiloader = DataLoader(dataset=validataset, num_workers=opt.threads, batch_size=opt.batchSize, shuffle=True)
注意:如果按照如下方式使用,就会报eError: take(): argument 'index' (position 1) must be Tensor, not numpy.ndarray错误
from sklearn.model_selection import train_test_split import numpy as np import torch import torch.autograd import Variable from torch.utils.data import DataLoader traindata = np.load(train_path) # image_num * W * H trainlabel = np.load(train_label_path) train_data = traindata[:, np.newaxis, ...] train_label_data = trainlabel[:, np.newaxis, ...] x_train = Variable(torch.from_numpy(train_data)) x_train = x_train.float() y_train = Variable(torch.from_numpy(train_label_data)) y_train = y_train.float() # 将原始的训练数据集分为训练集和验证集,后面就可以使用早停机制 x_tra, x_val, y_tra, y_val = train_test_split(x_train, y_train, test_size=0.1) # 训练集和验证集使用9:1
train_test_split方法接受的x_train,y_train格式应该为numpy.ndarray 而不应该是Tensor,这点需要注意。
感谢各位的阅读!关于“pytorch怎么把图像数据集进行划分成train,test和val”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





