Python怎么爬取电子课本送给居家上课的孩子们,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
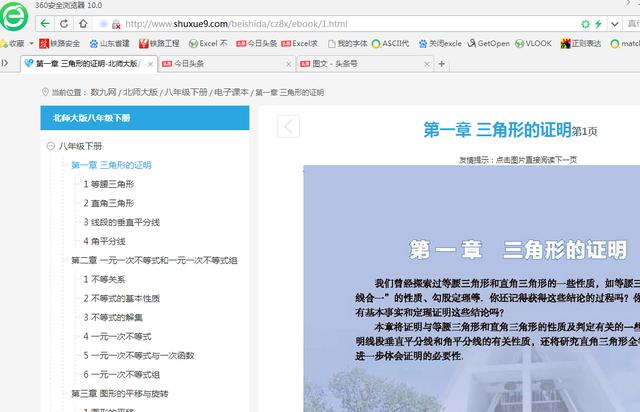
在这个全民抗疫的日子,中小学生们也开启了居家上网课的生活。很多没借到书的孩子,不得不在网上看电子课本,有的电子课本是老师发的网络链接,每次打开网页去看,既费流量,也不方便。今天我们就利用python的爬虫功能,把网络链接的课本爬下来,再做成PDF格式的本地文件,让孩子们随时都能看。本文案例爬取的网络课本见下图:
实现思路为两部分:
用python从网站爬取全部课本图片;
将图片合并生成PDF格式文件。
具体过程:
爬虫4流程:发出请求——获得网页——解析内容——保存内容。
根据上篇python批量爬取网络图片里讲过的知识,网页里的图片有单独的网址,爬取图片时需要先爬取出图片网址,再根据图片网址爬取图片。
1、发出请求:
首先找出合适的网址URL,因是静态网页网址,我们可直接用浏览器地址栏的网址,下图2中红框位置即为要用的网址,复制下来就行。
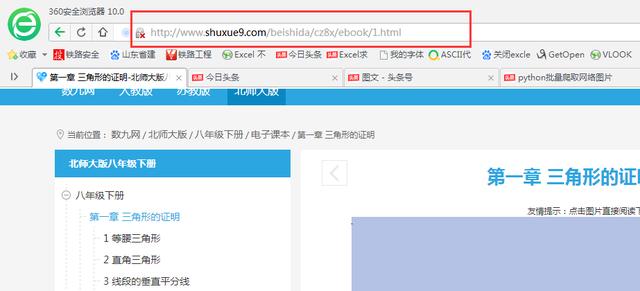
网页网址为:http://www.shuxue9.com/beishida/cz8x/ebook/1.html
2、发出请求获得响应:
url = http://www.shuxue9.com/beishida/cz8x/ebook/1.htmlresponse = requests.get(url)
3、解析响应获得网页内容:
soup = BeautifulSoup(response.content, 'lxml')4、解析网页内容,获得图片网址:
jgp_url = soup.find('div', class_="center").find('a').find('img')['src']5、向图片网址发出访问请求,并获得图片(因为该网址仅有图片,不需用find解析):
jpg = requests.get(jgp_url).content6、保存图片:
f = open(set_path() + number + '.jpg','wb')f.write(jpg)其中,set_path()是提前建好的用于存放图片的路径,代码见下,也可直接写上想用的路径:
def set_path(): path = r'e:/python/book' if not os.path.isdir(path): os.makedirs(path) paths = path+'/' return(paths)7、存在问题:
以上就完成了课本图片的爬取,我们打开文件夹,发现只有一张图片被下载了,后面的都没。这是因为浏览网页时,每个页面都有不同的网址,我们试着分析一下,发现电子课本的每一页网址很有规律:
第1页网址:http://www.shuxue9.com/beishida/cz8x/ebook/1.html
第2页网址:http://www.shuxue9.com/beishida/cz8x/ebook/2.html
......
第n页网址:http://www.shuxue9.com/beishida/cz8x/ebook/n.html
每页上的图片网址各不相同,没规律。我们可以根据规律用循环方式,对网址发起访问,获得图片后,自动循环访问下一个网址......最终获得全部图片。
8、设置循环提取:
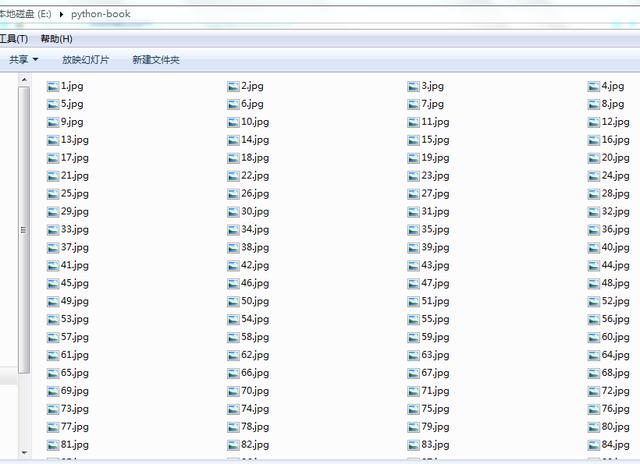
在以上全部过程纳入到一个for循环里,根据网页,我们可以看到共有152页,设置循环后完整代码为:
import requests , osfrom bs4 import BeautifulSoupfor i in range(1, 153):# 发出请求 url = "http://www.shuxue9.com/beishida/cz8x/ebook /{}".format(i)+".html" response = requests.get(url)# 获得网页 soup = BeautifulSoup(response.content, 'lxml')# 解析网页得到图片网址 jgp_url = soup.find('div', class_="center").find('a').find('img') ['src']# 发出请求解析获得图片 jpg = requests.get(jgp_url).content# 设置图片保存路径 p = r'e:/python-book' if not os.path.isdir(p): os.makedirs(p)# 保存图片 f = open(p + '/' + str(i) + '.jpg', 'wb') f.write(jpg)print("下载完成")运行程序,即可一次下载全部课本图片,效果为:

二、将图片合并生成PDF格式文件
图片下载完成后,将图片生成PDF格式才方便使用。网上有专门的软件,但免费的试用版只能合并几张图片。今天教大家一个免费且常用的OFFICE—ppt软件来将多张图片合并成一个PDF格式文件。
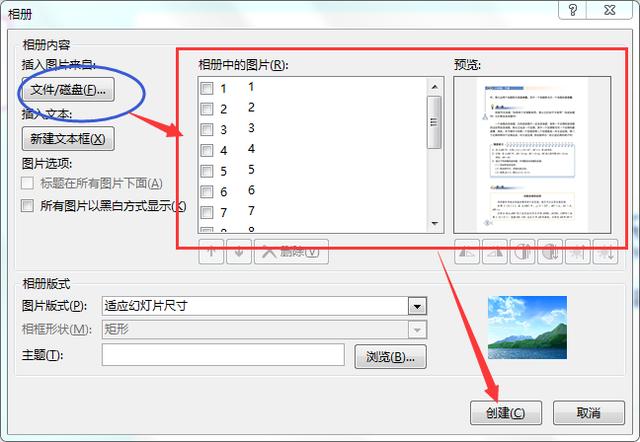
新建一个PowerPoint空白文件,点击插入——相册——新建相册,
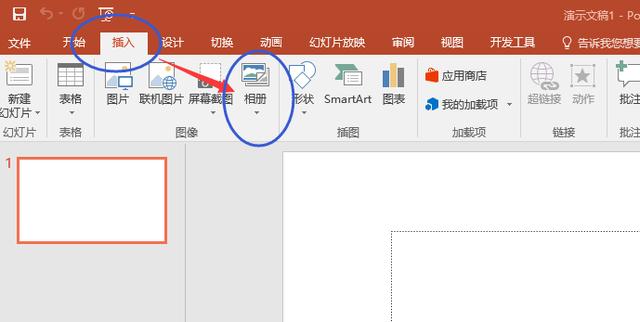
在弹出的窗体里,点击左上角的“文件/磁盘”,将刚才下载的图片全部导入进去,导入后的效果如下图右侧红框样式,然后点击“创建”,保存文件时另存为PDF格式即可。
总结:
至此,从网页爬取电子课本图片,生成PDF格式的本地文件就全部完成了。其中,如何找到并提取网页中的图片网址,在本头条上一篇文章里已有详述,有疑问的可查阅或留言交流。
另分享一个从网页内容中找到图片网址的简便方法:在打开的开发者工具界面,点击左上角的箭头符号,然后在网页上点击想要查找网址的图片,会自动高亮显示图片网址所在位置。如下所示:

关于Python怎么爬取电子课本送给居家上课的孩子们问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



