这篇文章给大家介绍Nodejs中怎么解决CPU密集型任务,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
一. 方案对比

二. 其他的线程池方案
1 Libuv和nginx的线程池:线程数固定,多个线程共享一个任务队列,没有任务时主动挂起,不会主动退出。
2 Java:线程数运行时可以动态增加,支持空闲退出、任务过载多种处理策略,多种类型的线程池。
三. 诉求
1 提交一个js文件处理cpu型任务,这样比较方便。而不是传一个函数,需要经过各种序列化反序列化。
2 一个全局的线程池,可以支持多种类型的任务,类似libuv线程池
3 空闲过久的线程可以主动退出
4 任务过载可以动态扩展线程数
Nodejs线程池的调研:
1 machenjie/node-thread-pool 任务只能是代码字符串,固定线程数,不支持空闲线程主动退出
2 Truth2984/thread_pools 任务只能是代码字符串,没有实现池化,每次创建一个线程,执行完任务退出。
3 bruno303/node-workers-pool 任务只能是代码字符串,不支持空闲退出
4 zebrajaeger/threadpool 不是线程池的概念 5
psastras/node-threadpool 没有实现池化,不支持空闲退出
6 node-worker-threads-pool 周下载量20k左右,star 80。任务只能是代码字符串,不支持空闲线程退出,固定线程数
7 threads 周下载量20k左右,star 1.1k 是对线程模块的封装,没有实现池化能力
8 poolifier 周下载量5000左右,star 59,任务可以是js文件,一个类型的任务新建一个线程池,无法共享线程池
目前的npm包看起来还不太能满足需求。所以决定写一个。
四.线程池的设计需要考虑的问题
1 对于纯cpu型的任务,线程数和cpu核数要相等才能达到最优的性能,否则过多的线程引起的上下文切换反而会导致性能下降。
2 对于io型的任务,更多的线程理论上是会更好,因为可以更早地给硬盘发出命令,磁盘会优化并持续地处理请求。当然,线程数也不是越多越好。线程过多会引起系统负载过高,过多上下文切换也会带来性能的下降。
3 使用方便、简单
整体架构(原图[1])
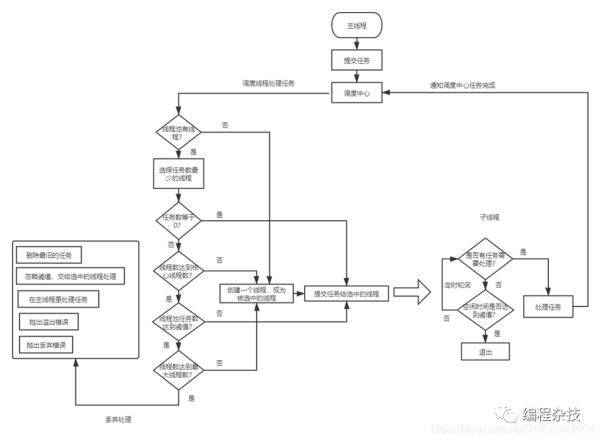
五. 设计思想
1 任务队列的设计
1.1传统的线程池设计 维护一个共享的任务队列,然后多个线程通过加锁互斥的方式访问该队列,取出任务执行。比如libuv,nginx。
1.2 我们的设计 因为我们是通过js使用nodejs线程池的,队列也是使用js数据结构表示的。所以我们无法通过加锁的方式互斥访问共享队列。这就会引起竞态条件。我们使用的方式是,每个子线程维护自己的任务队列,调度中心把任务提交给子线程,子线程自己插入所维护的队列中。
2 线程类型和任务数 把线程分为核心线程和替补线程。分为几个关键的概念:子线程当前的任务数,线程池的总任务数、核心线程数和最大线程数。在总任务数还没有得到阈值时,所有任务都由核心线程处理,达到阈值后,会创建替补线程处理。
3 过载处理策略和选择线程的策略 任务过载时,就会触发过载处理策略。分为报错、在主线程执行任务、继续交给子线程处理、删除最老的任务。选择线程的策略为选择任务数最少的线程。
4 空闲策略 当没有任务可处理的时候,线程池的线程怎么办?
4.1 传统的设计 使用条件变量机制,把线程阻塞在条件变量中,这时候操作系统不会调度该线程执行,所以不会浪费cpu,等到有新任务到来时,主线程会唤醒被阻塞的子线程。不过阻塞的线程依然占据着系统资源,如果一直没有任务,则浪费资源。
4.2 我们的设计 我们在js层无法像底层线程一样使用条件变量,所以我们无法阻塞自己,这就意味着我们会一直在空转、浪费资源。所以我们设计了线程的空闲退出时间,达到这个时间后,线程退出。尽快释放资源。
5 如何设计用户和线程池的通信 用户提交任务后,如果知道任务什么时候执行完?如何拿到执行结果?执行任务的时候,参数如何传进去?
5.1 传统的设计 用户把需要处理的逻辑封装到函数中,然后子线程中阻塞时执行,执行完后,同步拿到结果。
5.2 我们的设计 但是在nodejs中不太一样。Nodejs使用work_thread模块创建的线程,其实是一个和主线程独立的事件循环。所以我们在子线程里执行任务时,其实就相当于在执行一个nodejs的实例,这就意味着我们可以以同步和异步的方式编程我们任务函数代码。那么以异步方式进行处理的任务,我们如何拿到结果?为了解决以上问题,我们使用函数和Promise方案。用户提交的任务具体表现为一个返回Promise的函数,使用函数是因为我们可以在处理任务(执行函数)时,把用户自定义的参数传进去,使用Promise可以等到用户返回的Promise决议时,拿到返回的值,从而返回给用户。
具体实现:用户定义的逻辑test.js
module.exports = function() { return new Promise((resolve, reject) => { setTimeout(() => { resolve({code: 0}); },3000) }) }子线程逻辑
const result = await require('./test')(options);六.成果
线程池支持的参数
1 coreThreads:核心线程数,默认10个 2 maxThreads:最大线程数,默认50,只在支持动态扩容的情况下,该参数有效,否则该参数等于核心线程数 3 sync:线程处理任务的模式,同步则串行处理任务,异步则并行处理任务,不同步等待用户代码的执行结果 4 discardPolicy:任务超过阈值时的处理策略,策略如下 5 preCreate:是否预创建线程池 6 maxIdleTime:线程空闲多久后自动退出 7 pollIntervalTime:线程隔多久轮询是否有任务需要处理 8 maxWork:线程池最大任务数 9 expansion:是否支持动态扩容线程,阈值是最大线程数
支持的线程池类型
// 串行处理任务队列里的任务 const defaultSyncThreadPool = new SyncThreadPool(); // 并行处理任务队列里的任务 const defaultAsyncThreadPool = new AsyncThreadPool(); // 针对cpu密集型任务的线程池,线程数等于cpu核数 const defaultCpuThreadPool = new CPUThreadPool(); // 线程数固定的线程池 const defaultFixedThreadPool = new FixedThreadPool(); // 只有一个线程的线程池,任务在线程池中按序执行 const defaultSingleThreadPool = new SingleThreadPool();
七. 使用方式
方式1
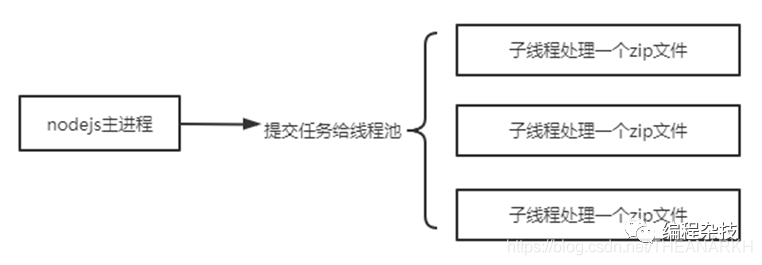
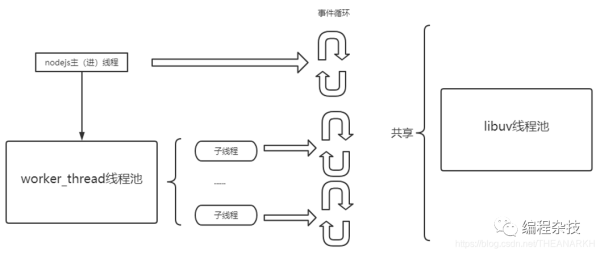
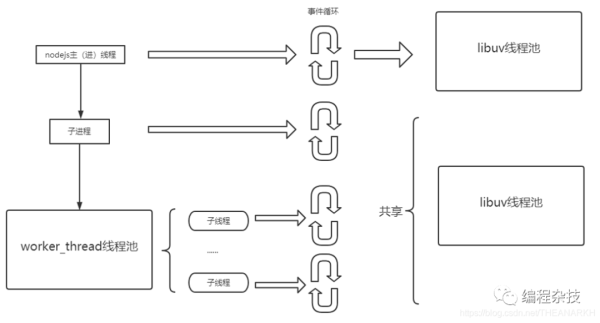
nodejs子线程和nodejs主线程共享一个libuv线程池,如果在子线程中使用了libuv的线程池,会和主线程竞争libuv子线程。从而影响主线程的任务执行。如果是纯cpu的计算,则可以这样使用。下面是这种使用方式下,nodejs的架构。
方式2
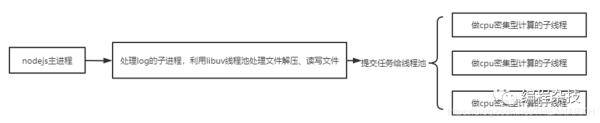
在nodejs主进程外开启一个新的进程进行任务的处理,和主进程保持独立,保证稳定性的同时,也不会和主进程竞争libuv的线程。如果在子线程中需要用到libuv线程池,则使用方式2比较好。下面是方式2对应的nodejs架构。
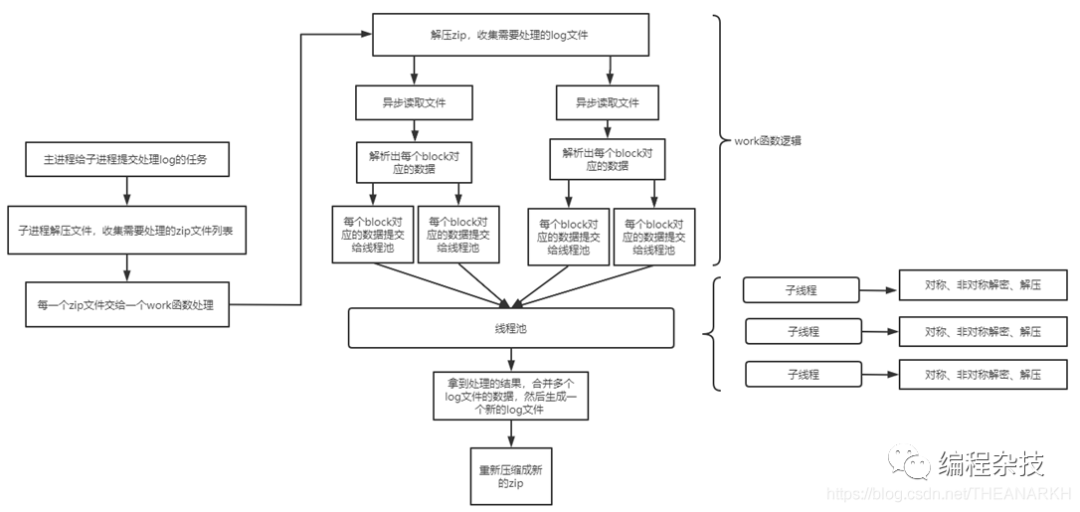
八. 具体例子
关于Nodejs中怎么解决CPU密集型任务就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





