本篇内容介绍了“怎么理解浏览器事件循环”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
为什么要有事件循环
JS引擎
要回答这个问题,我们先来看一个简单的例子:
function c() {} function b() { c(); } function a() { b(); } a();以上一段简单的JS代码,究竟是怎么被浏览器执行的?
首先,浏览器想要执行JS脚本,需要一个“东西”,将JS脚本(本质上是一个纯文本),变成一段机器可以理解并执行的计算机指令。这个“东西”就是JS引擎,它实际上会将JS脚本进行编译和执行,整个过程非常复杂,这里不再过多介绍,感兴趣可以期待下我的V8章节,如无特殊说明,以下都拿V8来举例子。
有两个非常核心的构成,执行栈和堆。执行栈中存放正在执行的代码,堆中存放变量的值,通常是不规则的。
当V8执行到a()这一行代码的时候,a会被压入栈顶。

在a的内部,我们碰到了b(),这个时候b被压入栈顶。
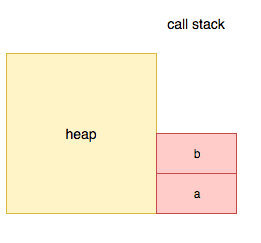
在b的内部,我们又碰到了c(),这个时候c被压入栈顶。

c执行完毕之后,会从栈顶移除。

函数返回到b,b也执行完了,b也从栈顶移除。
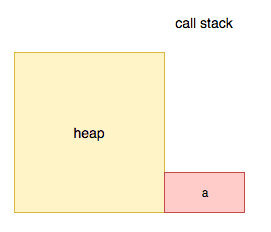
同样a也会被移除。
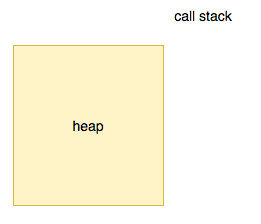
整个过程用动画来表示就是这样的:

(在线观看)
这个时候我们还没有涉及到堆内存和执行上下文栈,一切还比较简单,这些内容我们放到后面来讲。
DOM 和 WEB API
现在我们有了可以执行JS的引擎,但是我们的目标是构建用户界面,而传统的前端用户界面是基于DOM构建的,因此我们需要引入DOM。DOM是文档对象模型,其提供了一系列JS可以直接调用的接口,理论上其可以提供其他语言的接口,而不仅仅是JS。 而且除了DOM接口可以给JS调用,浏览器还提供了一些WEB API。 DOM也好,WEB API也好,本质上和JS没有什么关系,完全不一回事。JS对应的ECMA规范,V8用来实现ECMA规范,其他的它不管。 这也是JS引擎和JS执行环境的区别,V8是JS引擎,用来执行JS代码,浏览器和Node是JS执行环境,其提供一些JS可以调用的API即JS bindings。
由于浏览器的存在,现在JS可以操作DOM和WEB API了,看起来是可以构建用户界面啦。 有一点需要提前讲清楚,V8只有栈和堆,其他诸如事件循环,DOM,WEB API它一概不知。原因前面其实已经讲过了,因为V8只负责JS代码的编译执行,你给V8一段JS代码,它就从头到尾一口气执行下去,中间不会停止。
另外这里我还要继续提一下,JS执行栈和渲染线程是相互阻塞的。为什么呢? 本质上因为JS太灵活了,它可以去获取DOM中的诸如坐标等信息。 如果两者同时执行,就有可能发生冲突,比如我先获取了某一个DOM节点的x坐标,下一时刻坐标变了。 JS又用这个“旧的”坐标进行计算然后赋值给DOM,冲突便发生了。 解决冲突的方式有两种:
鸿蒙官方战略合作共建——HarmonyOS技术社区
限制JS的能力,你只能在某些时候使用某些API。 这种做法极其复杂,还会带来很多使用不便。
JS和渲染线程不同时执行就好了,一种方法就是现在广泛采用的相互阻塞。 实际上这也是目前浏览器广泛采用的方式。
单线程 or 多线程 or 异步
前面提到了你给V8一段JS代码,它就从头到尾一口气执行下去,中间不会停止。 为什么不停止,可以设计成可停止么,就好像C语言一样?
假设我们需要获取用户信息,获取用户的文章,获取用的朋友。
单线程无异步
由于是单线程无异步,因此我们三个接口需要采用同步方式。
fetchUserInfoSync().then(doSomethingA); // 1s fetchMyArcticlesSync().then(doSomethingB);// 3s fetchMyFriendsSync().then(doSomethingC);// 2s由于上面三个请求都是同步执行的,因此上面的代码会先执行fetchUserInfoSync,一秒之后执行fetchMyArcticlesSync,再过三秒执行fetchMyFriendsSync。 最可怕的是我们刚才说了JS执行栈和渲染线程是相互阻塞的。 因此用户就在这期间根本无法操作,界面无法响应,这显然是无法接受的。
多线程无异步
由于是多线程无异步,虽然我们三个接口仍然需要采用同步方式,但是我们可以将代码分别在多个线程执行,比如我们将这段代码放在三个线程中执行。
线程一:
fetchUserInfoSync().then(doSomethingA); // 1s线程二:
fetchMyArcticlesSync().then(doSomethingB); // 3s线程三:
fetchMyFriendsSync().then(doSomethingC); // 2s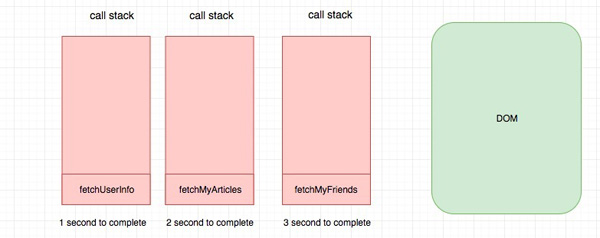
由于三块代码同时执行,因此总的时间最理想的情况下取决与最慢的时间,也就是3s,这一点和使用异步的方式是一样的(当然前提是请求之间无依赖)。为什么要说最理想呢?由于三个线程都可以对DOM和堆内存进行访问,因此很有可能会冲突,冲突的原因和我上面提到的JS线程和渲染线程的冲突的原因没有什么本质不同。因此最理想情况没有任何冲突的话是3s,但是如果有冲突,我们就需要借助于诸如锁来解决,这样时间就有可能高于3s了。 相应地编程模型也会更复杂,处理过锁的程序员应该会感同身受。
单线程 + 异步
如果还是使用单线程,改成异步是不是会好点?问题的是关键是如何实现异步呢?这就是我们要讲的主题 - 事件循环。
事件循环究竟是怎么实现异步的?
我们知道浏览器中JS线程只有一个,如果没有事件循环,就会造成一个问题。 即如果JS发起了一个异步IO请求,在等待结果返回的这个时间段,后面的代码都会被阻塞。 我们知道JS主线程和渲染进程是相互阻塞的,因此这就会造成浏览器假死。 如何解决这个问题? 一个有效的办法就是我们这节要讲的事件循环。
其实事件循环就是用来做调度的,浏览器和NodeJS中的事件循坏就好像操作系统的调度器一样。操作系统的调度器决定何时将什么资源分配给谁。对于有线程模型的计算机,那么操作系统执行代码的最小单位就是线程,资源分配的最小单位就是进程,代码执行的过程由操作系统进行调度,整个调度过程非常复杂。 我们知道现在很多电脑都是多核的,为了让多个core同时发挥作用,即没有一个core是特别闲置的,也没有一个core是特别累的。操作系统的调度器会进行某一种神秘算法,从而保证每一个core都可以分配到任务。 这也就是我们使用NodeJS做集群的时候,Worker节点数量通常设置为core的数量的原因,调度器会尽量将每一个Worker平均分配到每一个core,当然这个过程并不是确定的,即不一定调度器是这么分配的,但是很多时候都会这样。
了解了操作系统调度器的原理,我们不妨继续回头看一下事件循环。 事件循环本质上也是做调度的,只不过调度的对象变成了JS的执行。事件循环决定了V8什么时候执行什么代码。V8只是负责JS代码的解析和执行,其他它一概不知。浏览器或者NodeJS中触发事件之后,到事件的监听函数被V8执行这个时间段的所有工作都是事件循环在起作用。
我们来小结一下:
对于V8来说,它有:
调用栈(call stack)
这里的单线程指的是只有一个call stack。只有一个call stack 意味着同一时间只能执行一段代码。
堆(heap)
对于浏览器运行环境来说:
WEB API
DOM API
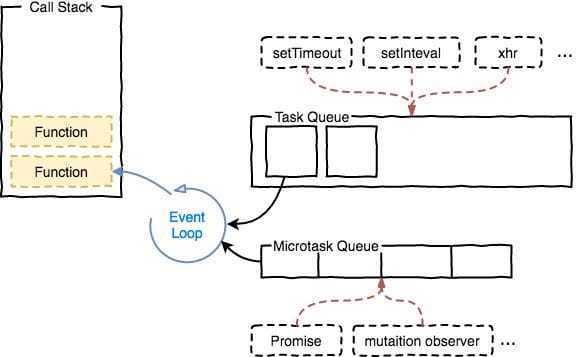
任务队列
事件来触发事件循环进行流动
以如下代码为例:
function c() {} function b() { c(); } function a() { setTimeout(b, 2000) } a();执行过程是这样的:
(在线观看)
因此事件循环之所以可以实现异步,是因为碰到异步执行的代码“比如fetch,setTimeout”,浏览器会将用户注册的回调函数存起来,然后继续执行后面的代码。等到未来某一个时刻,“异步任务”完成了,会触发一个事件,浏览器会将“任务的详细信息”作为参数传递给之前用户绑定的回调函数。具体来说,就是将用户绑定的回调函数推入浏览器的执行栈。
但并不是说随便推入的,只有浏览器将当然要执行的JS脚本“一口气”执行完,要”换气“的时候才会去检查有没有要被处理的“消息”。
如果于则将对应消息绑定的回调函数推入栈。当然如果没有绑定事件,这个事件消息实际上会被丢弃,不被处理。比如用户触发了一个click事件,但是用户没有绑定click事件的监听函数,那么实际上这个事件会被丢弃掉。
我们来看一下加入用户交互之后是什么样的,拿点击事件来说:
$.on('button', 'click', function onClick() { setTimeout(function timer() { console.log('You clicked the button!'); }, 2000); }); console.log("Hi!"); setTimeout(function timeout() { console.log("Click the button!"); }, 5000); console.log("Welcome to loupe.");上述代码每次点击按钮,都会发送一个事件,由于我们绑定了一个监听函数。因此每次点击,都会有一个点击事件的消息产生,浏览器会在“空闲的时候”对应将用户绑定的事件处理函数推入栈中执行。
伪代码:
while (true) { if (queue.length > 0) { queue.processNextMessage() } }动画演示:
(在线观看)
加入宏任务&微任务
我们来看一个更复制的例子感受一下。
console.log(1) setTimeout(() => { console.log(2) }, 0) Promise.resolve().then(() => { return console.log(3) }).then(() => { console.log(4) }) console.log(5)上面的代码会输出:1、5、3、4、2。 如果你想要非常严谨的解释可以参考 whatwg 对其进行的描述 -event-loop-processing-model。
下面我会对其进行一个简单的解释。
浏览器首先执行宏任务,也就是我们script(仅仅执行一次)
完成之后检查是否存在微任务,然后不停执行,直到清空队列
执行宏任务
其中:
宏任务主要包含:setTimeout、setInterval、setImmediate、I/O、UI交互事件
微任务主要包含:Promise、process.nextTick、MutaionObserver 等
有了这个知识,我们不难得出上面代码的输出结果。
由此我们可以看出,宏任务&微任务只是实现异步过程中,我们对于信号的处理顺序不同而已。如果我们不加区分,全部放到一个队列,就不会有宏任务&微任务。这种人为划分优先级的过程,在某些时候非常有用。
加入执行上下文栈
说到执行上下文,就不得不提到浏览器执行JS函数其实是分两个过程的。一个是创建阶段Creation Phase,一个是执行阶段Execution Phase。
同执行栈一样,浏览器每遇到一个函数,也会将当前函数的执行上下文栈推入栈顶。
举个例子:
function a(num) { function b(num) { function c(num) { const n = 3 console.log(num + n) } c(num); } b(num); } a(1);遇到上面的代码。 首先会将a的压入执行栈,我们开始进行创建阶段Creation Phase, 将a的执行上下文压入栈。然后初始化a的执行上下文,分别是VO,ScopeChain(VO chain)和 This。 从这里我们也可以看出,this其实是动态决定的。VO指的是variables, functions 和 arguments。 并且执行上下文栈也会同步随着执行栈的销毁而销毁。
伪代码表示:
const EC = { 'scopeChain': { }, 'variableObject': { }, 'this': { } }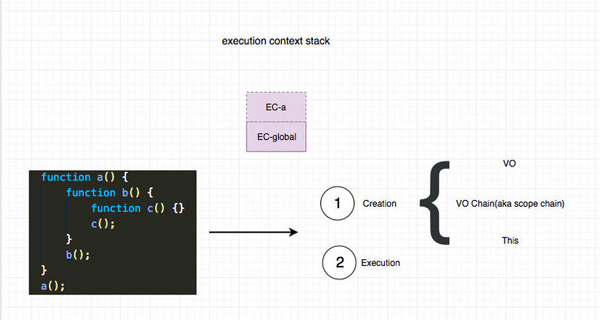
我们来重点看一下ScopeChain(VO chain)。如上图的执行上下文大概长这个样子,伪代码:
global.VO = { a: pointer to a(), scopeChain: [global.VO] } a.VO = { b: pointer to b(), arguments: { 0: 1 }, scopeChain: [a.VO, global.VO] } b.VO = { c: pointer to c(), arguments: { 0: 1 }, scopeChain: [b.VO, a.VO, global.VO] } c.VO = { arguments: { 0: 1 }, n: 3 scopeChain: [c.VO, b.VO, a.VO, global.VO] }引擎查找变量的时候,会先从VOC开始找,找不到会继续去VOB...,直到GlobalVO,如果GlobalVO也找不到会返回Referrence Error,整个过程类似原型链的查找。
值得一提的是,JS是词法作用域,也就是静态作用域。换句话说就是作用域取决于代码定义的位置,而不是执行的位置,这也就是闭包产生的本质原因。 如果上面的代码改造成下面的:
function c() {} function b() {} function a() {} a() b() c()或者这种:
function c() {} function b() { c(); } function a() { b(); } a();其执行上下文栈虽然都是一样的,但是其对应的scopeChain则完全不同,因为函数定义的位置发生了变化。拿上面的代码片段来说,c.VO会变成这样:
c.VO = { scopeChain: [c.VO, global.VO] }也就是说其再也无法获取到a和b中的VO了。
“怎么理解浏览器事件循环”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://segmentfault.com/a/1190000021295911



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



