目标网站:http://bbs.fengniao.com/
使用框架:scrapy
因为有很多模块的方法都还不是很熟悉,所有本次爬虫有很多代码都用得比较笨,希望各位读者能给处意见
首先创建好爬虫项目,并使用crawl模板创建爬虫文件
通过观察论坛的规律得出,很多贴子的页数往往大于一页,那么要将贴子里各页的图片下载到同一文件夹内,并且不能重名,就是获取到当前的页码数,已页码数+自然数的方式命令文件。
发现scrapy自动爬虫会爬很多重复的页面,度娘后得出两个解决方法,第一个是用布隆过滤器,布隆过滤器相对于目前的我来说太过深奥,于是便采用了将URL写入mysql的方式,通过mysql键的唯一性来去重复。
先编写items文件
import scrapy
class FengniaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field() #定义贴子名
images=scrapy.Field() #定义图片链接
act=scrapy.Field() #定义页码数
thisurl=scrapy.Field() #定义当前url
其次是爬虫文件,这里命名为s1.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from fengniao.items import FengniaoItem
from scrapy import Request
class S1Spider(CrawlSpider):
name = 's1'
allowed_domains = ['bbs.fengniao.com']
#start_urls = ['http://bbs.fengniao.com/']
def start_requests(self):
url='http://bbs.fengniao.com/forum/forum_101.html/' #爬虫开始的网址
ua={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36"} #设置浏览器ua模拟浏览器
yield Request(url,headers=ua)
rules = (
Rule(LinkExtractor(allow=r'forum/'), callback='parse_item', follow=True), #allow=r'forum/' 设置爬取的网址的规律
)
def parse_item(self, response):
item = FengniaoItem()
item["thisurl"]=response.url #获取当前页面
item["title"]=response.xpath("/html/head/title/text()").extract() #获取当前标题
item["images"]=response.xpath("//div[@class='img']//img/@src").extract() #获取当前的图片url
item["act"]=response.xpath("//a[@class='act']/text()").extract() #获取当前的页码
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return item
当然啦,在settings.py里要开启pipelines 设置浏览器ua
然后我们在pipelines.py里开始处理我们的爬到的东西
# -*- coding: utf-8 -*-
import os
import urllib.request
import re
import pymysql
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class FengniaoPipeline(object):
def process_item(self, item, spider):
images=item["images"] #将图片链接列表赋给images变量
thisurl = item["thisurl"] #将当前网址赋值费thisurl变量
conn=pymysql.connect(host='127.0.0.1',user='root',passwd='root',db='dd',charset='utf8') #创建数据库连接
cursor=conn.cursor() #创建游标
sql="insert into fengniao(link) values('" + thisurl + "')" 编写数据库代码将当前链接插入数据库
try: #做一个异常处理,如果可以插进数据库,说明当前网址没有爬出过
cursor.execute(sql)
conn.commit()
if len(images)>0: #监测当前网址图片链接是否存在 ,如果存在则执行下面的操作
title = item["title"][0] #将帖子名提取出来并赋值给title
new_title = title.replace("【有图】", "") #使用replace方法将【有图】 去掉
act = item["act"][0] # 当前页码数 #提取当前的页码数并赋值给act
print(act)
print(thisurl)
folder = "E:/PAS/fengniao1/" + new_title + '/' # 构造文件夹目录 以帖子名命名
folder_test = os.path.exists(folder) # 监测文件夹是否存在
if not folder_test: #如果文件夹不存在
os.mkdir(folder) #创建文件夹
print("创建文件夹"+new_title+"成功")
else: #如果文件夹存在
print("文件夹"+new_title+"已存在")
print("一共有" + str(len(images)) + "张图片")
for i in range(0, len(images)): #使用for循环依次输出图片地址
pat='(.*?)?imageView' #观察得出,图片的地址为小图地址,所以使用正则表达式处理一下图片地址,得到高品质图片的地址
new_images=re.compile(pat).findall(images[i]) #得到大图图片地址列表
#print(new_images)
num=int(act)-1 #处理一下页码数
print("正在下载" + str(num) + str(i) + "张图片")
file = folder + str(num) + str(i) + ".jpg" #构造图片名称,为当前(页面数-1)+自然数
urllib.request.urlretrieve(new_images[0], filename=file) #使用urllib.request.urlretrieve 方法下载图片
# for i in range(0,len(images)):
# print("正在下载"+str(count)+str(i)+"张图片")
# file=folder+str(count)+str(i)+".jpg"
# urllib.request.urlretrieve(images[i],filename=file)
else: #如果当前网址没有图片 跳过
pass
except: #如果当前url写不进数据库,输出异常
print("本网页已经爬过了,跳过了哦") #打印提示
cursor.close()
conn.close()
return item
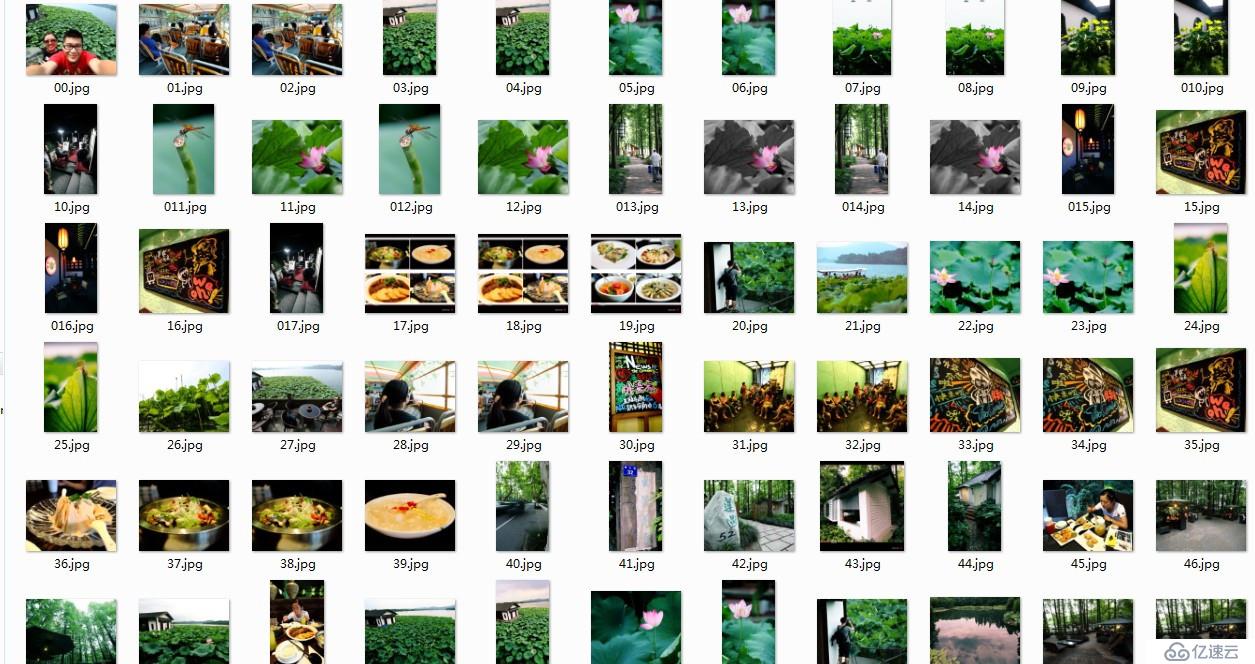
至此,代码已经编写完成 我们来看看运行后是怎么样的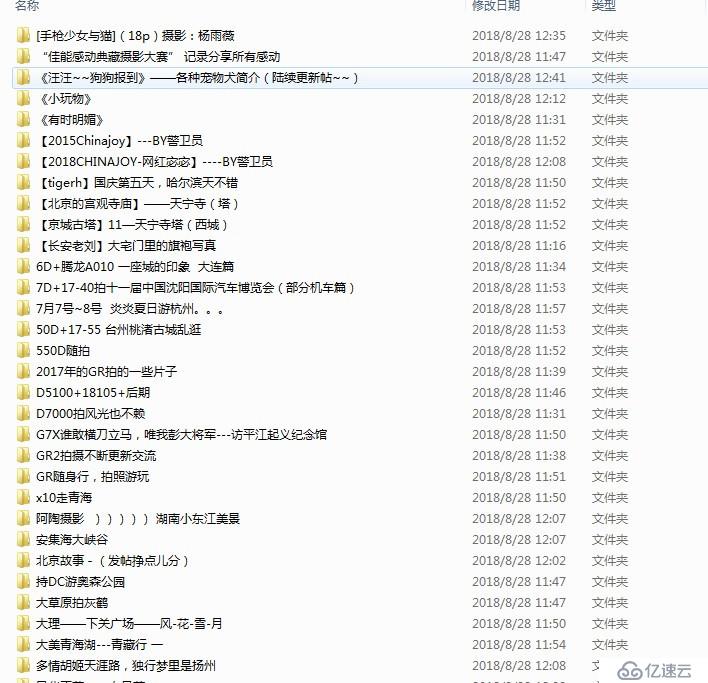
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





